如何使用分区处理MySQL的亿级数据优化
mysql在查询上千万级数据的时候,通过索引可以解决大部分查询优化问题。但是在处理上亿数据的时候,索引就不那么友好了。
数据表(日志)是这样的:表大小:1T,约24亿行;表分区:按时间分区,每个月为一个分区,一个分区约2-3亿行数据(40-
2024-11-16
浅谈MySQL 亿级数据分页的优化
目录背景分析数据模拟1、创建两个表:员工表和部门表2、创建两个函数:生成随机字符串和随机编号3、编写存储过程,模拟500W的员工数据4、编写存储过程,模拟120的部门数据5、建立关键字段的索引,这边是跑完数据之后再建索引,会导致建索引耗时长
2024-11-16
mysql上亿数据秒级查询怎么实现
要实现MySQL上亿数据的秒级查询,需要考虑以下几个方面:1. 数据分库分表:将数据分散存储在多个数据库和表中,以减少单个数据库或表的数据量,提高查询性能。可以根据某个字段进行分库分表,如用户ID、时间等。2. 索引优化:通过合理地创建索引
2024-11-16
mongodb亿级数据如何处理
处理MongoDB亿级数据的方法可以包括以下几个方面:1. 数据分片:将数据分散存储在不同的分片上,可以提高读写性能。可以根据数据的某个字段进行分片,使数据均匀分布在不同的节点上。2. 副本集和故障转移:通过配置副本集,可以实现数据的冗余备
2024-11-16
MySQL 亿级数据导入导出及迁移笔记
最近MySQL的笔记有点多了,主要是公司Oracle比较稳定维护较少,上周被安排做了一个MySQL亿级数据的迁移,趁此记录下学习笔记;
数据迁移,工作原理和技术支持数据导出、BI报表之类的相似,差异较大的地方是导入和导出数据量区别,一般报表
2024-11-16
MySQL亿级数据平滑迁移双写方案实战
目录一、背景二、方案选型三、前期准备3.1 全量同步&增量同步&一致性校验3.2 代码改造3.3 插件实现四、双写流程4.1 上线双写改造后的业务代码,上线时只读写老库4.2 使用公司中间件平台提供的数据工具同步老库数据到新库4.3 停止同
2024-11-16
oracle中如何删除亿级数据
目录oracle删除亿级数据1、drop table ,然后再create table,插入数据2、使用delete批量删除3、使用truncate table ,然后再插入数据oracle数据库亿级数据量清理SQL优化常识第一种方法就是D
2024-11-16
redis 亿级数据读取的实现
目录引言Redis 的基础特性亿级数据读取策略1. 分片与集群2. 使用管道(Pipeline)3. 批量读取(MGET、HGETALL)4. 数据分页5. 读写分离实战案例分析场景描述解决方案结论引言随着数据量的爆炸式增长,如何在亿级数
2024-11-16
SQL级别数据分区策略
SQL级别的数据分区策略是在数据库表中按照一定的规则将数据分割成多个分区,以提高查询性能、管理数据和优化存储空间利用率。SQL数据库管理系统通常提供了多种数据分区方法,包括范围分区、列表分区、哈希分区和复合分区等。范围分区是根据某个列的范
2024-11-16
MySQL实现清空分区表单个分区数据
目录mysql清空分区表单个分区数据1.单个分区清空2.编辑存储过程MySQL自动分区自动清理完整的SQL查看分区总结MySQL清空分区表单个分区数据1.单个分区清空ALTER TABLE xxx TRUNCATE PARTITION
2024-11-16
mysql怎么查询分区数据
在MySQL中,可以使用以下语法来查询分区数据:SELECT * FROM table_name PARTITION (partition_name);其中,table_name是要查询的表名,partition_name是要查询的分区名
2024-11-16
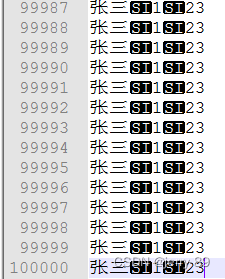
MySQL快速插入一亿测试数据
目录1、建表1.1 建立测试表 t_user1.2 创建临时表2、生成数据2.1 用 python生成 【一亿】 记录的数据文件(这个确实稍微花点时间)2.2 将生成的文件导入到临时表tmp_table中3、以临时表为基础数据,插入数据到t
2024-11-16

























![[mysql]mysql8修改root密码](https://static.528045.com/imgs/50.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





