selenium+phantomjs爬取
selenium+phantomjs爬取京东商品信息今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618.html打开 https://www.jd
2024-11-16
pyspider+PhantomJS的代
环境:pyspider0.3.9 PhantomJS2.1.1,均为最新版进程用supervisor托管的。其中需要加的几个地方:webui进程:pyspider -c config.json --phantomjs-proxy=127.0
2024-11-16
php phantomjs的安装方法
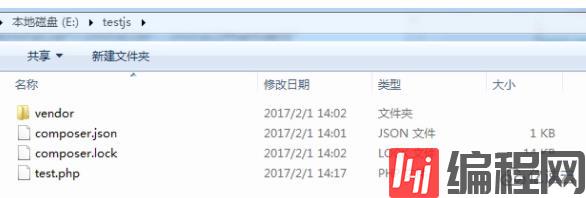
本文将为大家详细介绍“php phantomjs的安装方法”,内容步骤清晰详细,细节处理妥当,而小编每天都会更新不同的知识点,希望这篇“php phantomjs的安装方法”能够给你意想不到的收获,请大家跟着小编的思路慢慢深入,具体内容如下
2024-11-16
Python使用Phantomjs截屏网
#!/usr/bin/python# -*- coding:utf8 -*-from selenium import webdriverimport osdriver1 = webdriver.PhantomJS(executable_pa
2024-11-16
windows环境安装phantomjs
1. 安装phantomjs下载地址:http://phantomjs.org/download.html解压后将phantomjs.exe文件放到python根目录 2.安装pyspiderpip install pyspider运行:p
2024-11-16
python基于phantomjs实现导入图片
基于的phantomjs的自动化,会出现
1.flash不支持2.部分基于view的按钮点不到,部分按钮是基于flash的(尤其是在于上传按钮)browser.find_element_by_xpath(".//*[@name='SWFUp
2024-11-16
phantomjs怎么安装及应用
PhantomJS是一个无界面的、基于WebKit的JavaScript API,可用于处理页面自动化、网页截图、网页内容抓取等任务。以下是安装和应用PhantomJS的步骤:安装PhantomJS:1. 访问PhantomJS的官方网站(
2024-11-16
selenium模拟浏览器&PhantomJS
注意:最新版本的selenium停止对PhantomJS的支持(可以使用谷歌&火狐的无头浏览器),如果还想用PhantomJS,需要对selenium降级卸载最新版本:pip3 uninstall selenium安装老版本:pip3 in
2024-11-16
Selenium&PhantomJS实战一:获取代理ip
用Selenium&PhantomJS完成的网络爬虫,最适合使用的情形是爬取有JavaScript的网站,用来爬其他的站点也一样给力准备环境将在https://www.kuaidaili.com/ops/proxylist/1/中获取已经验
2024-11-16
nodejs通过phantomjs实现下载网页
功能其实很见简单,通过 phantomjs.exe 采集 url 加载的资源,通过子进程的方式,启动nodejs 加载所有的资源,对于css的资源,匹配css内容,下载里面的url资源
当然功能还是很简单的,在响应式设计和异步加载的情况下,
2024-11-16
Selenium&PhantomJS实战二:爬取漫画
准备环境一般来说在线看漫画的网站都会使用JavaScript来返回页面,打开百度搜索在线漫画,如下图:目标网站: http://www.1kkk.com极速漫画,选取一个漫画爬取 http://www.1kkk.com/manhua1963
2024-11-16
Phantomjs抓取渲染JS后的网页(Python代码)
最近需要爬取某网站,无奈页面都是JS渲染后生成的,普通的爬虫框架搞不定,于是想到用Phantomjs搭一个代理。
Python调用Phantomjs貌似没有现成的第三方库(如果有,请告知小编),漫步了一圈,发现只有pyspider提供了现成
2024-11-16
Node.JS利用PhantomJs抓取网页入门教程
前言
当想用 nodejs 抓取一些网页 , 我第一反应想到的就是使用 http 模块 , 比如抓取百度首页:var http = require('http');
var req = http.request('http://www.ba
2024-11-16



















![[mysql]mysql8修改root密码](https://static.528045.com/imgs/25.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





