Selenium cookies for requests
使用selenium模拟登录,保存cookies代码示例:importjsonfromseleniumimportwebdriverfromselenium.webdriver.common.keysimportKeysimporttime
2024-11-07
selenium如何获取动态数据
这篇文章主要介绍了selenium如何获取动态数据的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇selenium如何获取动态数据文章都会有所收获,下面我们一起来看看吧。Selenium 是一个自动化测试工具,利
2024-11-07
Jmeter接口测试获取Cookies的方法是什么
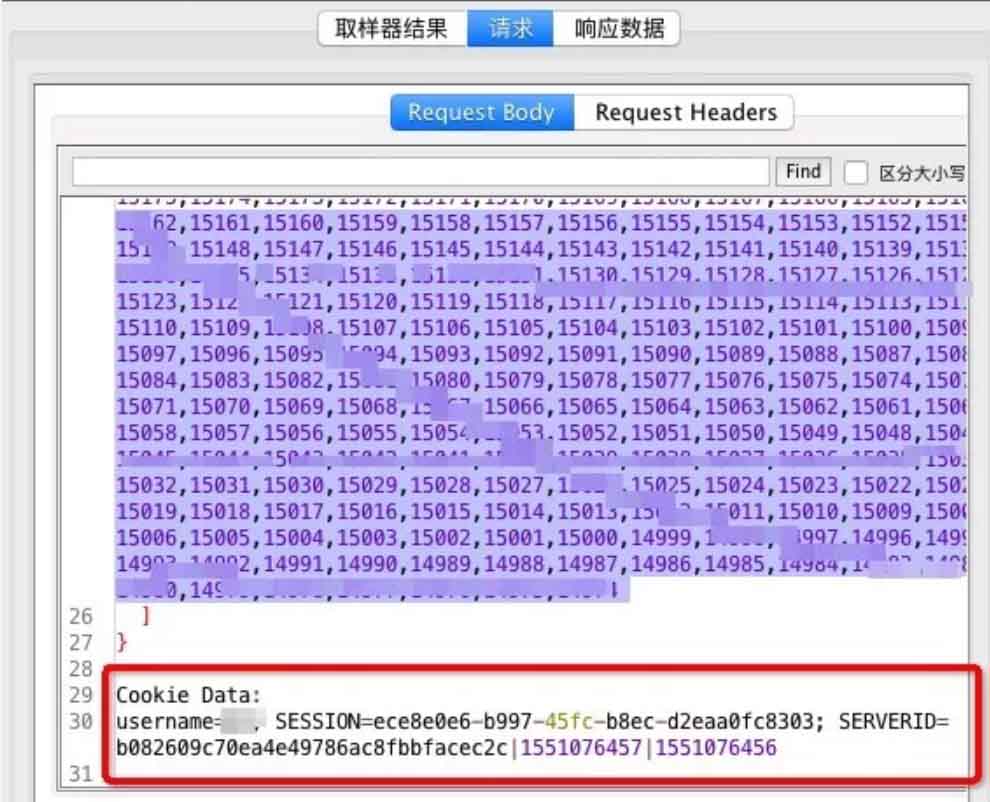
这篇“Jmeter接口测试获取Cookies的方法是什么”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Jmeter接口测试获
2024-11-07
Selenium&PhantomJS实战一:获取代理ip
用Selenium&PhantomJS完成的网络爬虫,最适合使用的情形是爬取有JavaScript的网站,用来爬其他的站点也一样给力准备环境将在https://www.kuaidaili.com/ops/proxylist/1/中获取已经验
2024-11-07
qpython3 读取安卓lastpass Cookies
之前我的博客写了python读取windows chrome Cookies,沿着同样的思路,这次本来想尝试读取安卓chrome Cookies,
但是可能是chrome的sqlite3版本比较高失败了,so改成读取lastpass 的Co
2024-11-07
selenium+phantomjs爬取
selenium+phantomjs爬取京东商品信息今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618.html打开 https://www.jd
2024-11-07
python selenium爬取kuk
在爬取这个网站之前,试过爬取其他网站的漫画,但是发现有很多反爬虫的限制,有的图片后面加了动态参数,每秒都会更新,所以前一秒爬取的图片链接到一下秒就会失效了,还有的是图片地址不变,但是访问次数频繁的话会返回403,终于找到一个没有限制的漫画网
2024-11-07
selenium+pyquery爬取淘宝
import refrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui imp
2024-11-07
Selenium&PhantomJS实战二:爬取漫画
准备环境一般来说在线看漫画的网站都会使用JavaScript来返回页面,打开百度搜索在线漫画,如下图:目标网站: http://www.1kkk.com极速漫画,选取一个漫画爬取 http://www.1kkk.com/manhua1963
2024-11-07

























![[mysql]mysql8修改root密码](https://static.528045.com/imgs/15.jpg?imageMogr2/format/webp/blur/1x0/quality/35)




