python3.6+scrapy+m
最近闲着,把之前写的小爬虫分享一下,才疏学浅,仅当参考。[介绍文档] python版本:python3.6 scrapy: 1.5.0 需要安装pymysql包支持访问mysql数据库 可以使用pip安装: pip
2024-11-06
scrapy入门
什么是scrapy?scrapy是一个为了爬去网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取scrapy使用了 Twisted 异步网络框架,可以加快我们的下载速度异步和非阻塞的区别异步:调用在发布之后
2024-11-06
Scrapy框架
目录 1. Scrapy介绍 1.1. Scrapy框架 1.2. Scrapy运行流程 1.3. 制作Srapy爬虫的四部曲 1.4. 文件目录
2024-11-06
python的Scrapy...
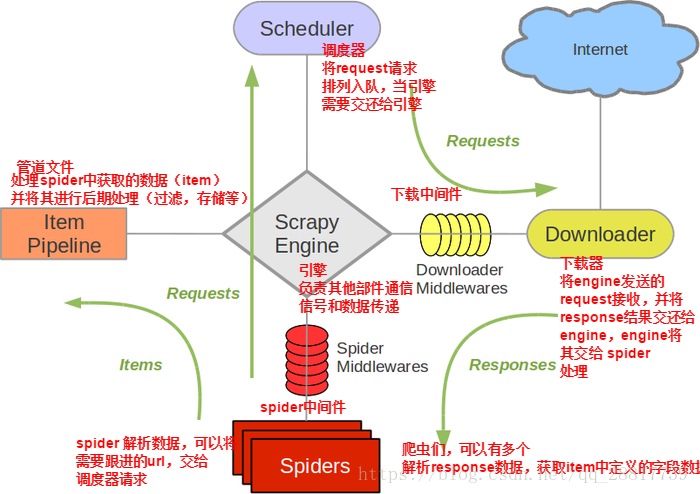
1、Scrapy Engine(Scrapy引擎)Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。2、Scheduler(调度)调度程序从Scrapy引擎接受请求并排序列入队列
2024-11-06
Scrapy框架-Spider
目录 1. Spider 2.Scrapy源代码 2.1. Scrapy主要属性和方法 3.parse()方法的工作机制
2024-11-06
Scrapy+Chromium+代理+
上周说到scrapy的基本入门。这周来写写其中遇到的代理和js渲染的坑。js是爬虫中毕竟麻烦处理的一块。通常的解决办法是通过抓包,然后查看request信息,接着捕获ajax返回的消息。但是,如果遇到一些js渲染特别复杂的情况,这种办法就非
2024-11-06
scrapy选择器css
CSS是网页代码中非常重要的一环,即使不是专业的Web从业人员,也有必要认真学习一下CSS选择器.class .intro 选择class="intro"的所有元素#id #firstname
2024-11-06
scrapy选择器xpath
Scrapy提取数据有自己的一套机制,它们被称作选择器(seletors),通过特定的Xpath或者css表达式来"选择"html文件中的某个部分。Xpath是一门用来在XML文件中选择节点的语言,也可以用在HTML上,css是一门将HTM
2024-11-06
爬虫——scrapy入门
安装scrapypip install scrapywindows可能安装失败,需要先安装c++库或twisted,pip install twisted创建项目scrapy startproject tutorial该命令将会创建包含下列
2024-11-06
scrapy框架安装
windows系统需要使用cmd管理员权限运行右键以管理员运行,不然会报错,没权限安装安装步骤pip install scrapy安装过程中报错需要visual c++这个,去对应的网址下载安装即可,注意管理员方式安装cmd运行scrapy
2024-11-06
Scrapy快速上手
超详细官方教程解析https://blog.csdn.net/fly_yr/article/details/51540269 实战过程:创建一个Scrapy项目定义提取的Item编写爬取网站的 spider 并提取 Item编写 Item
2024-11-06
python 之 scrapy 入门 (
在网上浏览了众多scrapy入门教程 作为小白的我总结一下: 最重要的一点就是安装Scrapy 前提是安装好了Anaconda Navigator过后 简直是如履平地啊! 可以借鉴https://blog.csdn.net/zjiang1
2024-11-06
python3安装scrapy框架
方法一:1.执行pip install scrapy命令2.这时肯定会报错,由于scrapy依赖的包比较多,执行上述操作,已经将大部分的依赖包安装好3.安装Twisted:下载网址4.下载完成后,可以进入下载文件的目录执行pip insta
2024-11-06
Scrapy 中 Request 对象和
Request构造器方法的参数列表:Request(url [, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding=
2024-11-06
如何使用scrapy-splash
这篇文章主要介绍了如何使用scrapy-splash,编程网小编觉得不错,现在分享给大家,也给大家做个参考,一起跟随编程网小编来看看吧!1.scrapy_splash是scrapy的一个组件scrapy_splash加载js数据基于Spla
2024-11-06
Python3 爬虫 scrapy框架
上次用requests写的爬虫速度很感人,今天打算用scrapy框架来实现,看看速度如何。第一步,安装scrapy,执行一下命令pip install Scrapy第二步,创建项目,执行一下命令scrapy startproject nov
2024-11-06
Scrapy持久化存储
基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作;执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储
2024-11-06
scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的
2024-11-06





















![[mysql]mysql8修改root密码](https://static.528045.com/imgs/52.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





