spark计算模型RDD
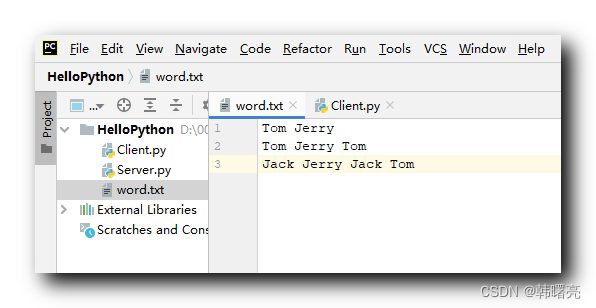
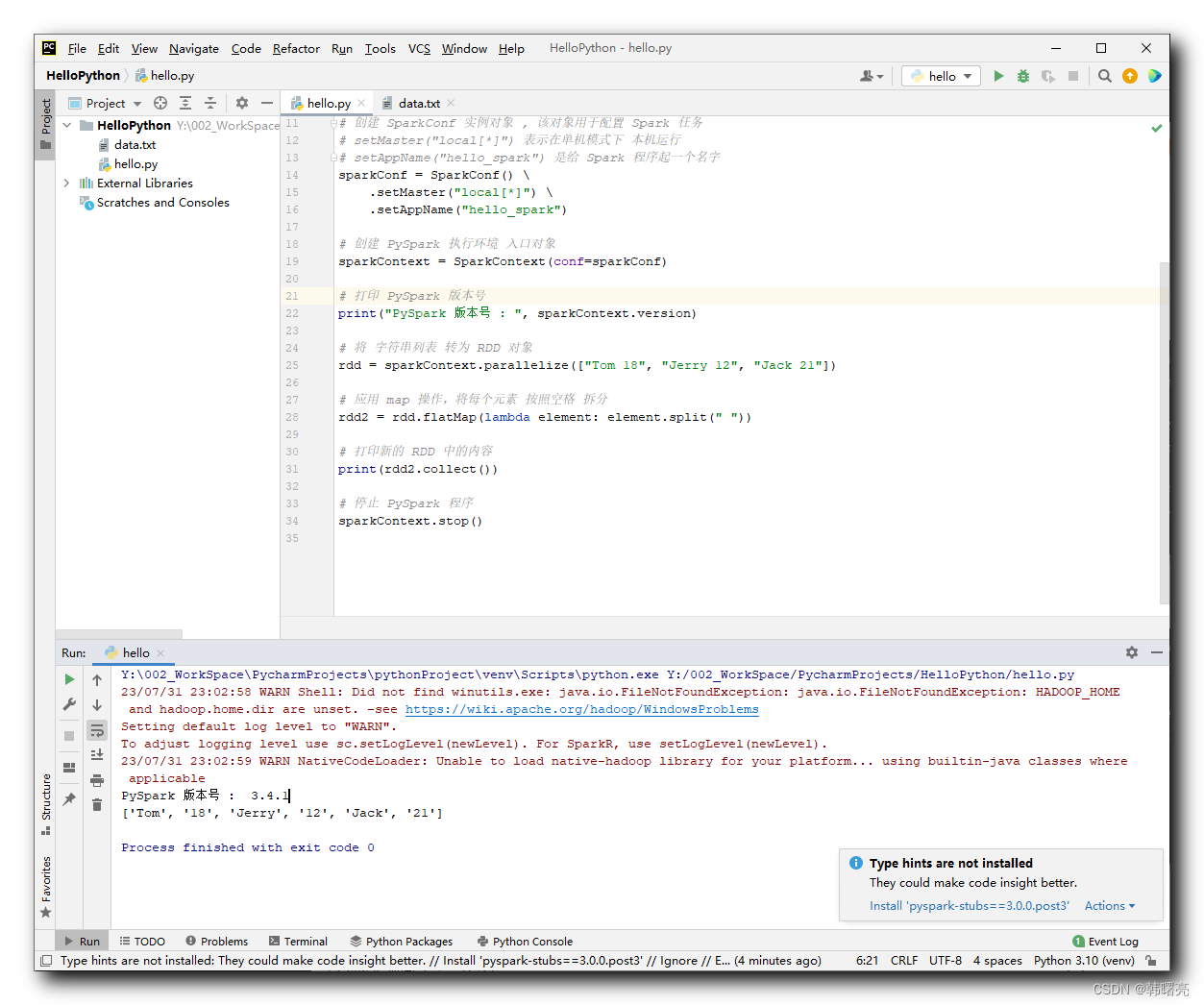
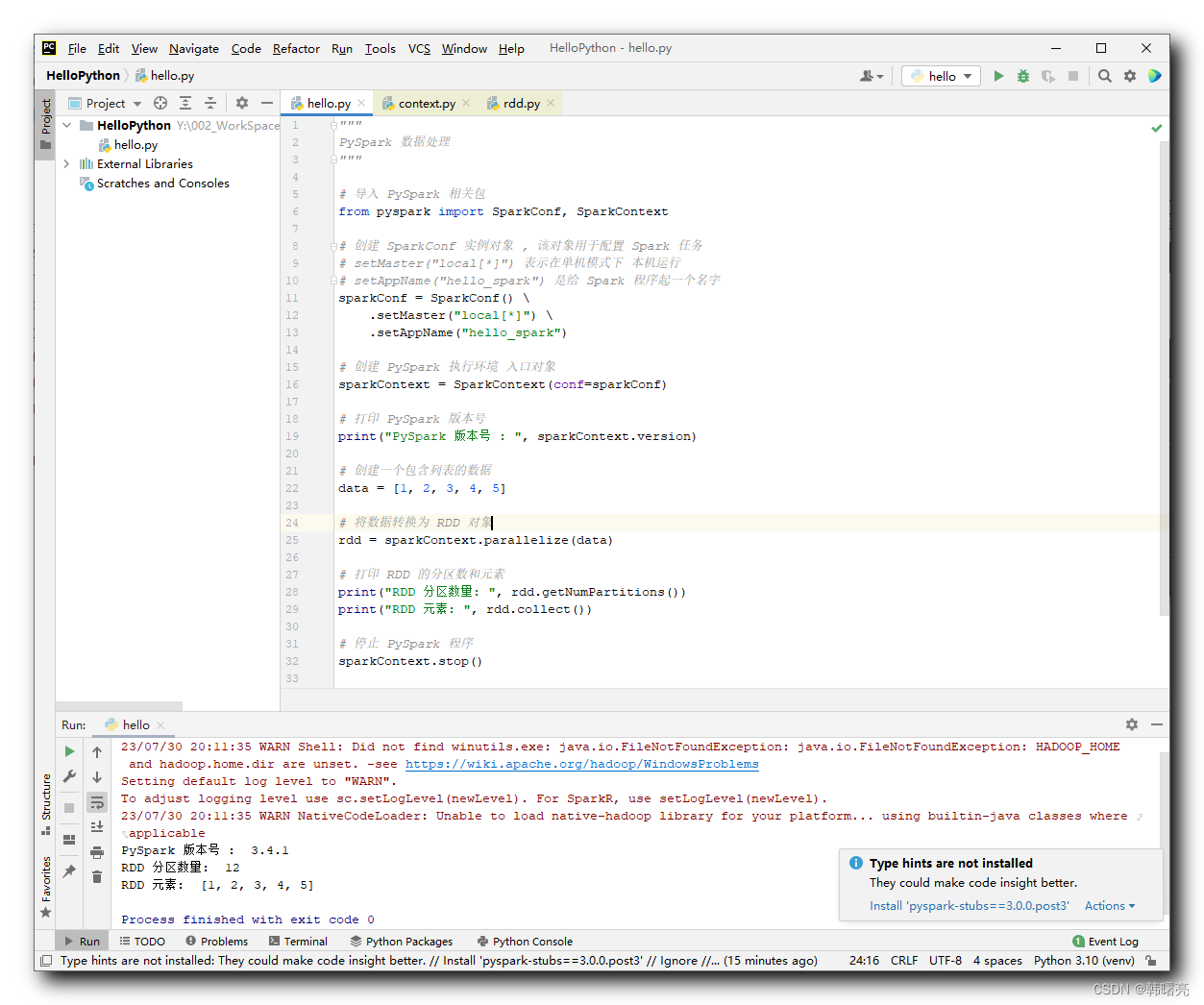
RDD介绍1.RDD概念以及特性RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度
2024-11-16
Spark RDD常用算子是什么类型的
小编给大家分享一下Spark RDD常用算子是什么类型的,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!Spark RDD常用算子:Value类型Spark之所以比
2024-11-16
阿里云函数计算服务ECS一种新型云计算应用模型
在云计算领域,随着技术的发展和需求的增长,越来越多的企业和用户开始关注云计算服务。而阿里云函数计算服务ECS,则是一种新型云计算应用模型,它为用户提供了更灵活、更高效的服务体验。在本文中,我们将详细介绍ECS的特点、优势以及使用方法。一、阿里云函数计算服务ECS的特点弹性扩展:ECS可以根据需求自动扩展资源,满足
2024-11-16
大数据Hadoop之——计算引擎Spark
目录一、概述1)Spark特点2)Spark适用场景二、Spark核心组件三、Spark专业术语详解1)Application:Spark应用程序2)Driver:驱动程序3)Cluster Manager:资源管理器4)Executor:执行器5)Worke
2024-11-16
Spark 两种方法计算分组取Top N
Spark 分组取Top N运算大数据处理中,对数据分组后,取TopN是非常常见的运算。下面我们以一个例子来展示spark如何进行分组取Top的运算。1、RDD方法分组取TopNfrom pyspark import SparkContextsc = Spar
2024-11-16
[离线计算-Spark|Hive] HDFS小文件处理
本文主要介绍小文件的处理方法思路,以及通过阅读源码和相关资料学习hudi 如何在写入时智能的处理小文件问题新思路.Hudi利用spark 自定义分区的机制优化记录分配到不同文件的能力,达到小文件的合并处理. 背景HDFS 小文件过多会对hadoop 扩展
2024-11-16
如何解析Apache Spark 统一内存管理模型
今天就跟大家聊聊有关如何解析Apache Spark 统一内存管理模型,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。Apache Spark 统一内存管理模型详解下面将对 Spark
2024-11-16
pytorch怎么获得模型的计算量和参数量
这篇文章给大家分享的是有关pytorch怎么获得模型的计算量和参数量的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。方法1 自带pytorch自带方法,计算模型参数总量total = sum([param.nele
2024-11-16
怎么理解spark的计算器与广播变量
这篇文章给大家介绍怎么理解spark的计算器与广播变量,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。一.计算器1.官网2.解释计数器只支持加,计算器字task里面3.测试4.结果截图WEBUI4.应用场景数据很多有的数
2024-11-16
阿里云原生服务器一种新型云计算服务器模型
阿里云原生服务器是一种新型的云计算服务器模型,旨在提供高效、灵活、可靠的计算资源,以满足各类应用场景的需求。本文将详细介绍阿里云原生服务器的特性、优势以及如何使用。阿里云原生服务器的特性:高效:阿里云原生服务器采用先进的处理器和存储技术,能够提供高效的计算和存储性能。灵活:阿里云原生服务器支持多种操作系统和应用程
2024-11-16









![[离线计算-Spark|Hive] HDFS小文件处理](/upload/202205/01/pemawbbryho.jpg)













![[mysql]mysql8修改root密码](https://static.528045.com/imgs/58.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





