大厂实践-哈啰-记录一次elasticsearch的查询性能优化


再分享一篇哈啰单车技术团队对ElasticSearch的查询性能优化的分析文章。
问题: 慢查询
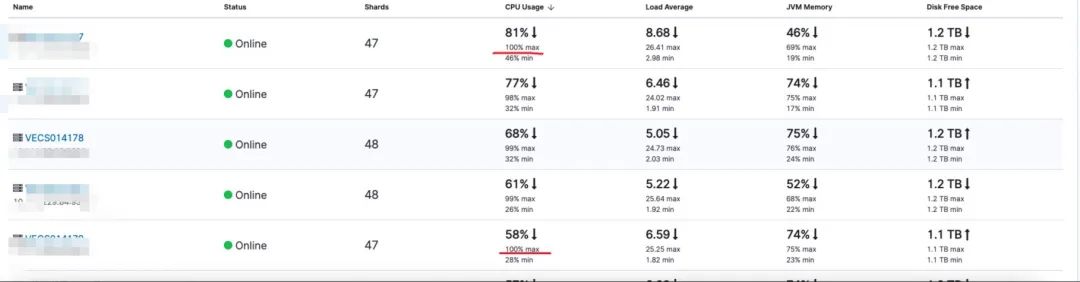
搜索平台的公共集群,由于业务众多,对业务的es查询语法缺少约束,导致问题频发。业务可能写了一个巨大的查询直接把集群打挂掉,但是我们平台人力投入有限,也不可能一条条去审核业务的es查询语法,只能通过后置的手段去保证整个集群的稳定性,通过slowlog分析等,下图中cpu已经100%了。
昨天刚好手头有一点点时间,就想着能不能针对这些情况,把影响最坏的业务抓出来,进行一些改善,于是昨天花了2小时分析了一下,找到了一些共性的问题,可以通过平台来很好的改善这些情况。

首先通过slowlog抓到一些耗时比较长的查询,例如下面这个索引的查询耗时基本都在300ms以上:
{
"from": 0,
"size": 200,
"timeout": "60s",
"query": {
"bool": {
"must": \[
{
"match": {
"source": {
"query": "5",
"operator": "OR",
"prefix\_length": 0,
"fuzzy\_transpositions": true,
"lenient": false,
"zero\_terms\_query": "NONE",
"auto\_generate\_synonyms\_phrase\_query": "false",
"boost": 1
}
}
},
{
"terms": {
"type": \[
"21"
\],
"boost": 1
}
},
{
"match": {
"creator": {
"query": "0d754a8af3104e978c95eb955f6331be",
"operator": "OR",
"prefix\_length": 0,
"fuzzy\_transpositions": "true",
"lenient": false,
"zero\_terms\_query": "NONE",
"auto\_generate\_synonyms\_phrase\_query": "false",
"boost": 1
}
}
},
{
"terms": {
"status": \[
"0",
"3"
\],
"boost": 1
}
},
{
"match": {
"isDeleted": {
"query": "0",
"operator": "OR",
"prefix\_length": 0,
"fuzzy\_transpositions": "true",
"lenient": false,
"zero\_terms\_query": "NONE",
"auto\_generate\_synonyms\_phrase\_query": "false",
"boost": 1
}
}
}
\],
"adjust\_pure\_negative": true,
"boost": 1
}
},
"\_source": {
"includes": \[
\],
"excludes": \[\]
}
}
这个查询比较简单,翻译一下就是:
```sql
SELECT guid FROM xxx WHERE source=5 AND type=21 AND creator='0d754a8af3104e978c95eb955f6331be' AND status in (0,3) AND isDeleted=0;
慢查询分析
这个查询问题还挺多的,不过不是今天的重点。比如这里面不好的一点是还用了模糊查询fuzzy_transpositions,也就是查询ab的时候,ba也会被命中,其中的语法不是今天的重点,可以自行查询,我估计这个是业务用了SDK自动生成的,里面很多都是默认值。
第一反应是当然是用filter来代替match查询,一来filter可以缓存,另外避免这种无意义的模糊匹配查询,但是这个优化是有限的,并不是今天讲解的关键点,先忽略。
错用的数据类型
我们通过kibana的profile来进行分析,耗时到底在什么地方?es有一点就是开源社区很活跃,文档齐全,配套的工具也非常的方便和齐全。
可以看到大部分的时间都花在了PointRangQuery里面去了,这个是什么查询呢?为什么这么耗时呢?这里就涉及到一个es的知识点,那就是对于integer这种数字类型的处理。在es2.x的时代,所有的数字都是按keyword处理的,每个数字都会建一个倒排索引,这样查询虽然快了,但是一旦做范围查询的时候。比如 type>1 and type<5就需要转成 type in (1,2,3,4,5)来进行,大大的增加了范围查询的难度和耗时。
之后es做了一个优化,在integer的时候设计了一种类似于b-tree的数据结构,加速范围的查询,详细可以参考(https://elasticsearch.cn/article/446)
所以在这之后,所有的integer查询都会被转成范围查询,这就导致了上面看到的isDeleted的查询的解释。那么为什么范围查询在我们这个场景下,就这么慢呢?能不能优化。
明明我们这个场景是不需要走范围查询的,因为如果走倒排索引查询就是O(1)的时间复杂度,将大大提升查询效率。由于业务在创建索引的时候,isDeleted这种字段建成了Integer类型,导致最后走了范围查询,那么只需要我们将isDeleted类型改成keyword走term查询,就能用上倒排索引了。
实际上这里还涉及到了es的一个查询优化。类似于isDeleted这种字段,毫无区分度的倒排索引的时候,在查询的时候,es是怎么优化的呢?
多个Term查询的顺序问题
实际上,如果有多个term查询并列的时候,他的执行顺序,既不是你查询的时候,写进去的顺序。

例如上面这个查询,他既不是先执行source=5再执行type=21按照你代码的顺序执行过滤,也不是同时并发执行所有的过滤条件,然后再取交集。es很聪明,他会评估每个filter的条件的区分度,把高区分度的filter先执行,以此可以加速后面的filter循环速度。比如creator=0d754a8af3104e978c95eb955f6331be查出来之后10条记录,他就会优先执行这一条。
怎么做到的呢?其实也很简单,term建的时候,每一个term在写入的时候都会记录一个词频,也就是这个term在全部文档里出现的次数,这样我们就能判断当前的这个term他的区分度高低了。
为什么PointRangeQuery在这个场景下非常慢
上面提到了这种查询的数据结构类似于b-tree,他在做范围查询的时候,非常有优势,Lucene将这颗B-tree的非叶子结点部分放在内存里,而叶子结点紧紧相邻存放在磁盘上。当作range查询的时候,内存里的B-tree可以帮助快速定位到满足查询条件的叶子结点块在磁盘上的位置,之后对叶子结点块的读取几乎都是顺序的。
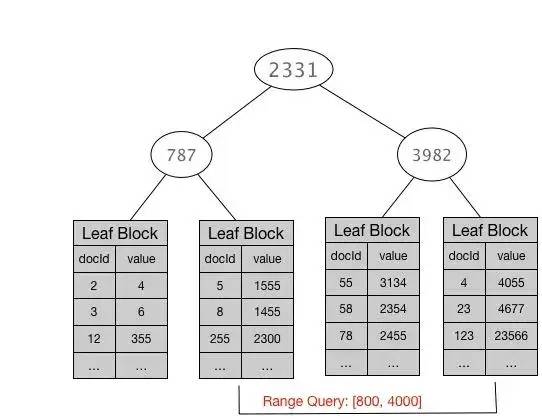
总结就是这种结构适合范围查询,且磁盘的读取是顺序读取的。但是在我们这种场景之下,term查询可就麻烦了,数值型字段的TermQuery被转换为了PointRangeQuery。这个Query利用Block k-d tree进行范围查找速度非常快,但是满足查询条件的docid集合在磁盘上并非向Postlings list那样按照docid顺序存放,也就无法实现postings list上借助跳表做蛙跳的操作。
要实现对docid集合的快速advance操作,只能将docid集合拿出来,做一些再处理。这个处理过程在org.apache.lucene.search.PointRangeQuery#createWeight这个方法里可以读取到。这里就不贴冗长的代码了,主要逻辑就是在创建scorer对象的时候,顺带先将满足查询条件的docid都选出来,然后构造成一个代表docid集合的bitset,这个过程和构造Query cache的过程非常类似。之后advance操作,就是在这个bitset上完成的。所有的耗时都在构建bitset上,因此可以看到耗时主要在build_scorer上了。
验证
找到原因之后,就可以开始验证了。将原来的integer类型全部改成keyword类型,如果业务真的有用到范围查询,应该会报错。通过搜索平台的平台直接修改配置,修改完成之后,重建索引就生效了。
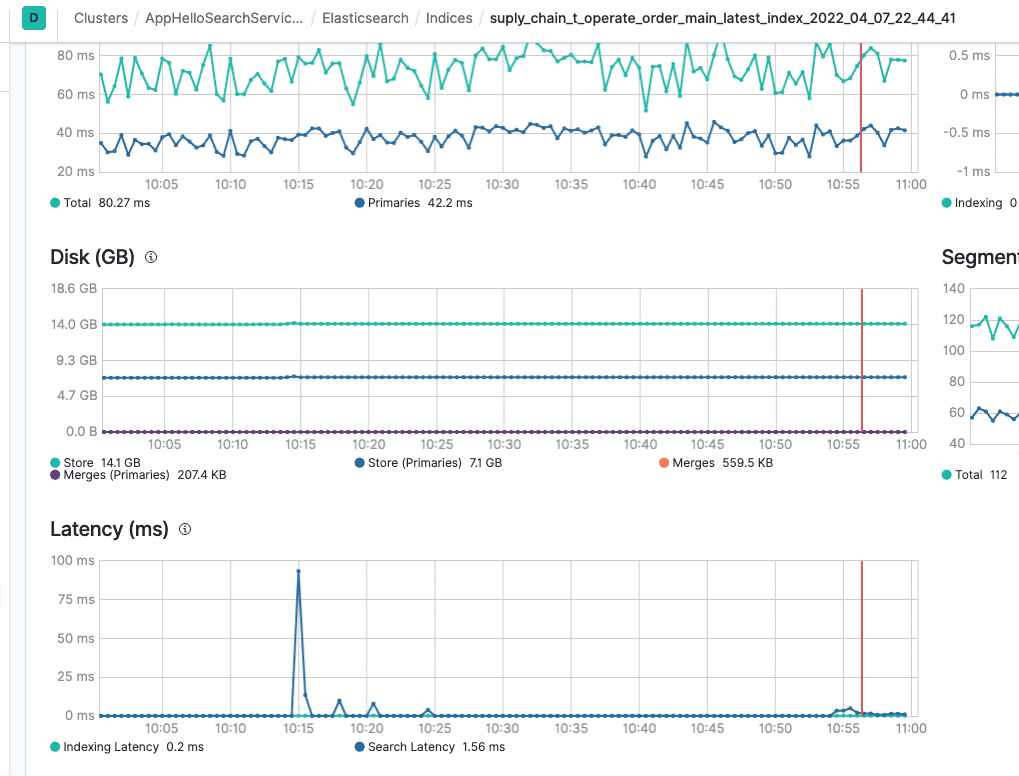
索引切换之后的效果也非常的明显,通过kibana的profile分析可以看到,之前需要接近100ms的PointRangQuery现在走倒排索引,只需要0.5ms的时间。
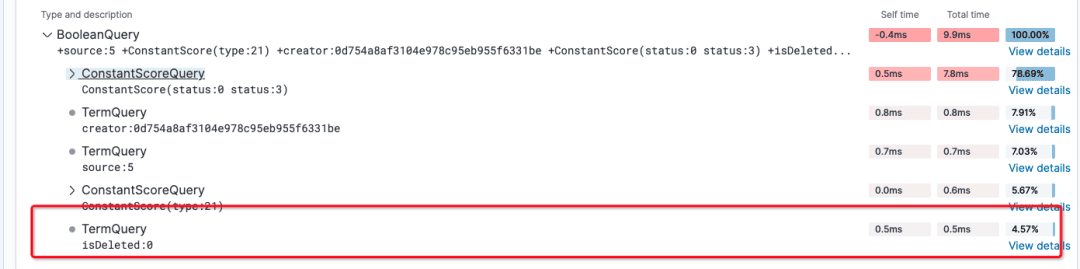
之前这个索引的平均latency在100ms+,这个是es分片处理的耗时,从搜索行为开始,到搜索行为结束的打点,不包含网络传输时间和连接建立时间,单纯的分片内的函数的处理时间的平均值,正常情况在10ms左右。
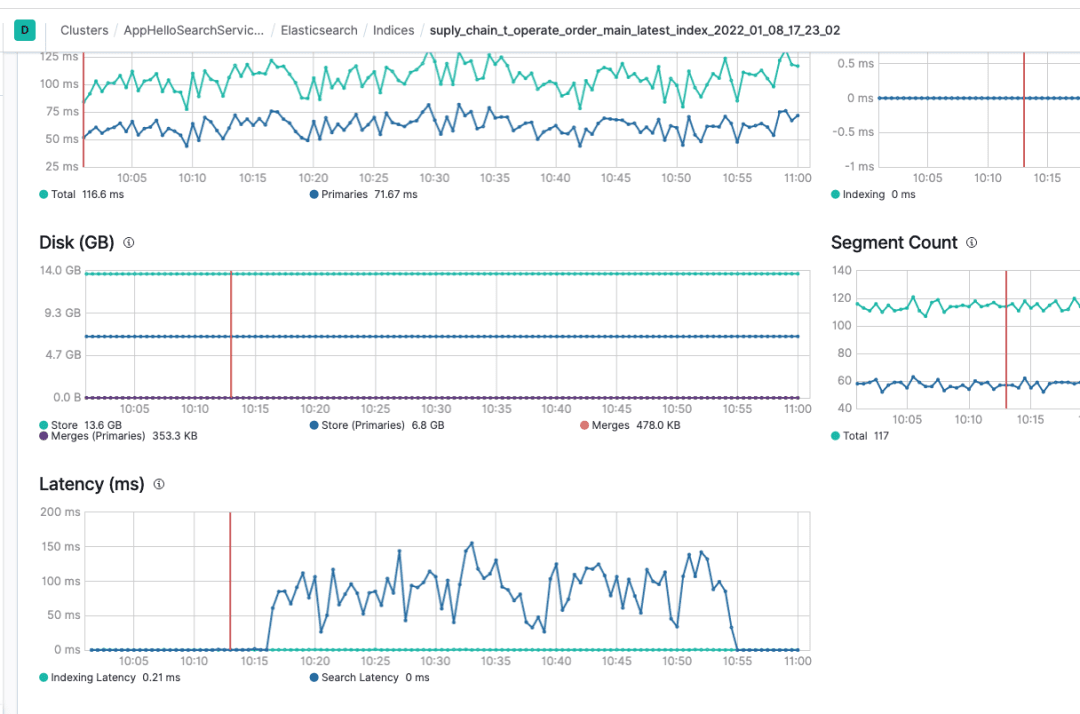
经过调整之后的耗时降到了10ms内。
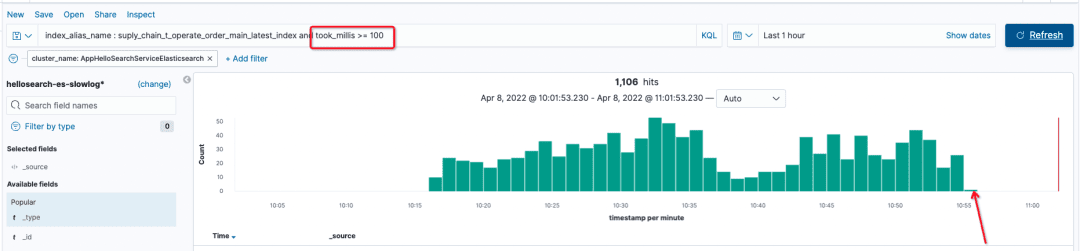
通过监控查看慢查询的数量,立即减少到了0。
未来
后续将通过搜索平台侧的能力来保证业务的查询,所有的integer我们会默认你记录的是状态值,不需要进行范围查询,默认将会修改为keyword类型,如果业务确实需要范围查询,则可以通过后台再修改回integer类型,这样可以保证在业务不了解es机制的情况下,也能拥有较好的性能,节省机器计算资源。
目前还遇到了很多问题需要优化。例如重建索引的时候,机器负载太高。公共集群的机器负载分布不均衡的问题,业务的查询和流量不可控等各种各样的问题,要节省机器资源就一定会面对这种各种各样的问题,除非土豪式做法,每个业务都拥有自己的机器资源,这里面有很多很多颇具技术挑战的事情。
实际上,在这一块还是非常利于积累经验,对于es的了解和成长也非常快,在查问题的过程中,对于搜索引擎的使用和了解会成长的非常快。不仅如此,很多时候,我们用心的看到生产的问题,持续的跟踪,一定会有所收获。大家遇到生产问题的时候,务必不要放过任何细节,这个就是你收获的时候,比你写100行的CRUD更有好处。
文章来源
转载说明:
- 作者:任天兵
- 版权声明:本文为哈啰技术团队的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
- 原文链接:https://mp.weixin.qq.com/s?__biz=MzI3OTE3ODk4MQ==&mid=2247486047&idx=1&sn=b3ab21da891df124c03e628eb3851b4c&chksm=eb4af1d5dc3d78c3be8995c0e16674f47598f907185dac03919f0c4d0a26ea4a71a0543390bf&scene=132#wechat_redirect
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341