

MySQL之聚簇索引与非聚簇索引


MySQL之聚簇索引与非聚簇索引
索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,主要讨论InnoDB和MyISAM两个存储引擎的索引实现方式。
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体细节依赖于其实现方式。
- 定义:索引中键值的逻辑顺序与数据行的物理顺序相同,一个表中只能有一个聚簇索引。
就比如,聚集索引就像是新华字典的拼音目录,而每个字存放的页码就是我们的数据物理地址;拼音目录对应的A-Z的字顺序,和字典实际存储的字的顺序A-Z也是一样的。
- 定义:索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
非聚集索引也叫辅助索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
- 何时使用聚簇索引与非聚簇索引
![在这里插入图片描述]()
- 聚簇索引和非聚簇索引的关系
聚簇索引是将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
非聚簇索引是将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置。
聚簇索引是物理有序的;非聚簇索引是逻辑有序,物理无序,在mysql中数据存储顺序就是聚簇索引的顺序,所以一个表只有一个聚簇索引,其他索引都是非聚簇的 - 聚簇索引的优缺点
优点:
1.数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
2.聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
1.插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
2.更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
3.二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
![MySQL之聚簇索引与非聚簇索引]()

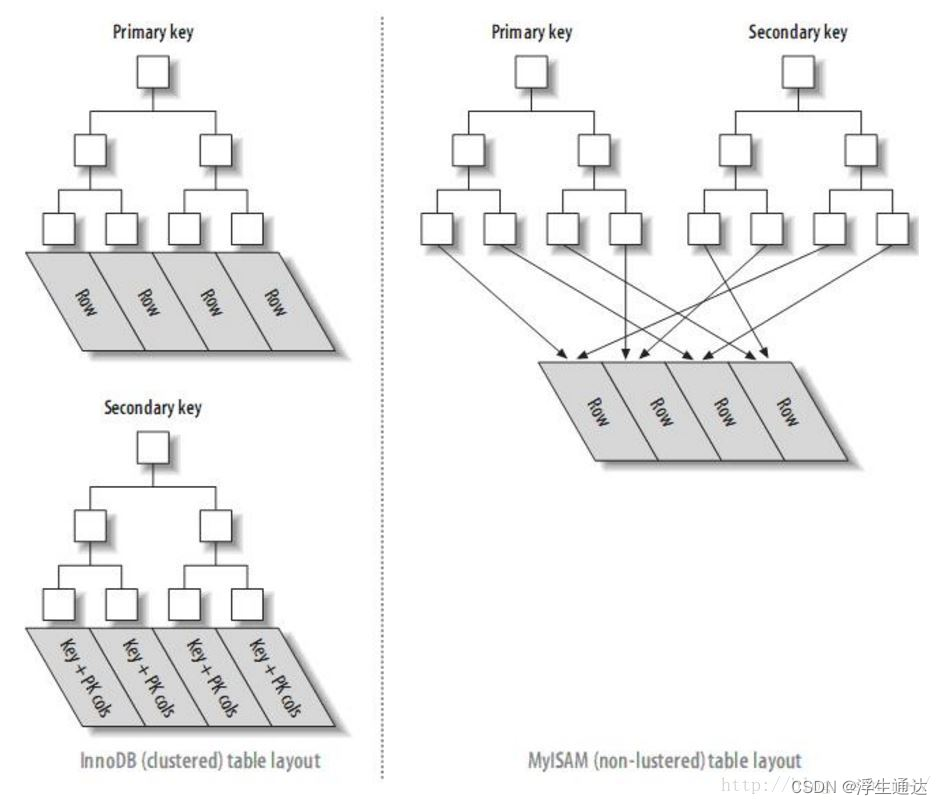
InnoDB索引实现
InnoDB使用B+Tree作为索引结构。
-
InnoDB的主键索引
表数据文件本身就是按B+Tree组织的一个索引结构,聚簇索引就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分;
Innodb通过主键聚集数据,如果没有定义主键,innodb会选择非空的唯一索引代替。如果没有这样的索引,innodb会隐式的定义一个主键来作为聚簇索引。如果你已经设置了主键为聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
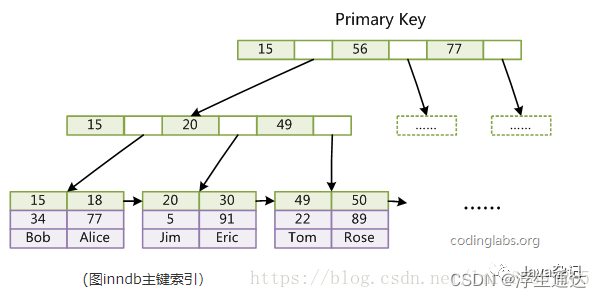
![在这里插入图片描述]()
(图inndb主键索引)是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。 -
InnoDB的辅助索引
InnoDB的所有辅助索引都引用主键作为data域。例如:
![在这里插入图片描述]()
InnoDB 表是基于聚簇索引建立的。因此InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
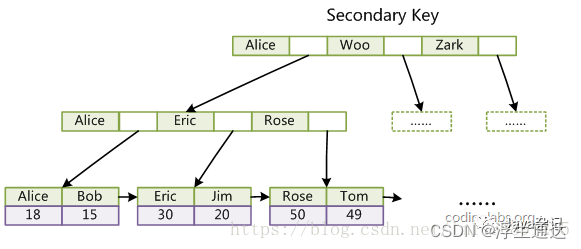
InnoDB的主键索引的叶子节点存储的是行数据,辅助索引的叶子节点存储的是主键列和索引。
MyISAM索引实现
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
- MyISAM的主键索引
MyISAM引擎也使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:
![在这里插入图片描述]()
- MyISAM的辅助索引
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复:
![在这里插入图片描述]()
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。

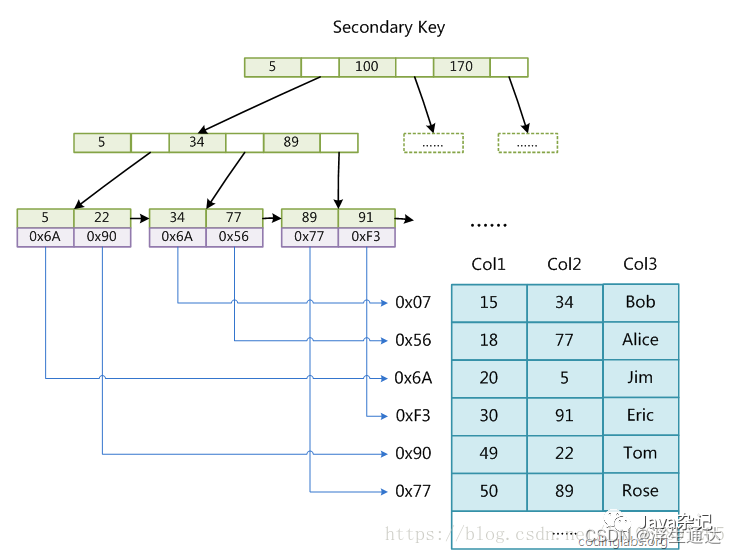
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
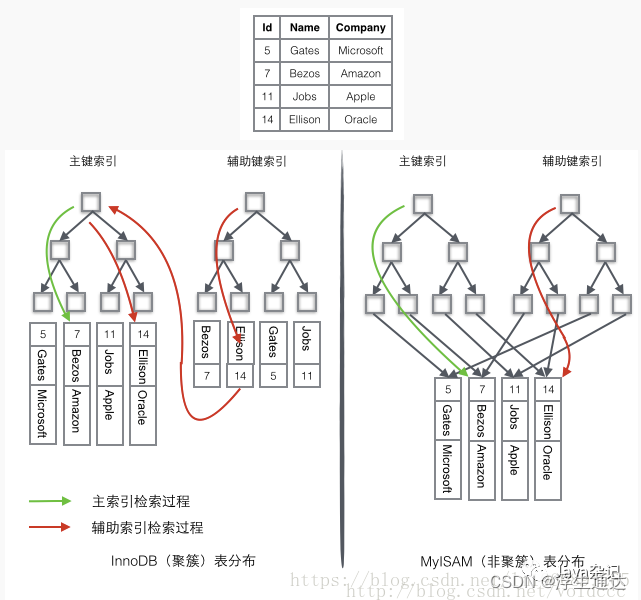
InnoDB中为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
主键索引是聚集索引还是非聚集索引?
在Innodb下主键索引是聚集索引,在Myisam下主键索引是非聚集索引
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
来源地址:https://blog.csdn.net/weixin_43851772/article/details/129684626
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341





![[mysql]mysql8修改root密码](https://static.528045.com/imgs/47.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









