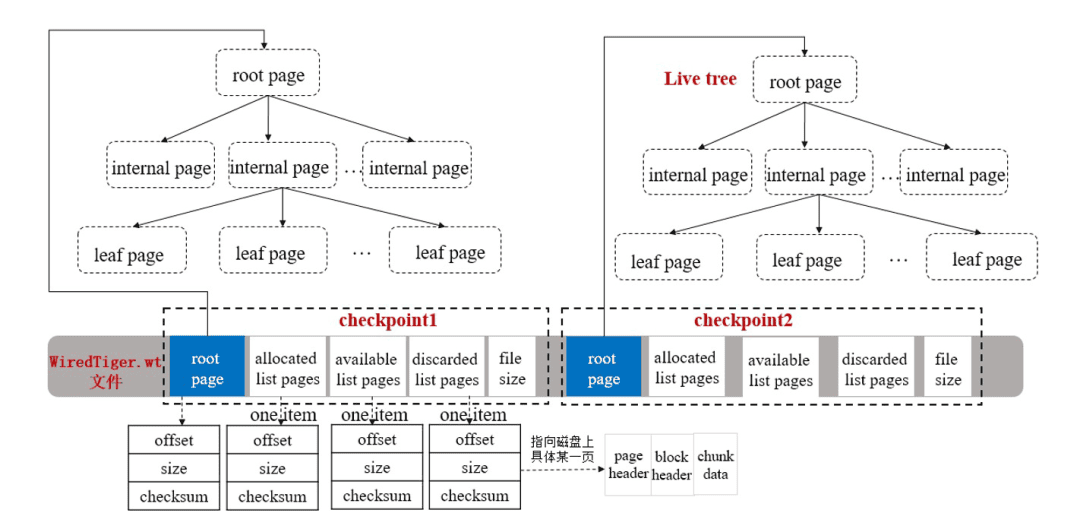
mongo进阶-wt引擎-page生命周期


通过前文我们了解到数据以page为单位加载到cache; 有必要系统的分析一页page的生命周期、状态以及相关参数的配置,这对后续MongoDB的性能调优和故障问题的定位和解决有帮助。
为什么要了解Page生命周期
通过前文我们了解到数据以page为单位加载到cache、cache里面又会生成各种不同类型的page及为不同类型的page分配不同大小的内存、eviction触发机制和reconcile动作都发生在page上、page大小持续增加时会被分割成多个小page,所有这些操作都是围绕一个page来完成的。
因此,有必要系统的分析一页page的生命周期、状态以及相关参数的配置,这对后续MongoDB的性能调优和故障问题的定位和解决有帮助。
Page的生命周期
Page的典型生命周期如下图所示:
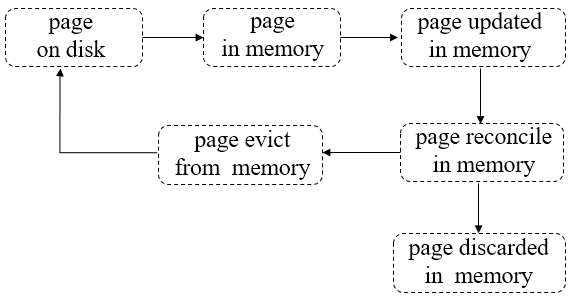
pages从磁盘读到内存;
pages在内存中被修改;
被修改的脏pages在内存被reconcile,完成后将discard这些pages。
pages被选中,加入淘汰队列,等待被evict线程淘汰出内存;
evict线程会将“干净“的pages直接从内存丢弃(因为相对于磁盘page来说没做任何修改),将经过reconcile处理后的磁盘映像写到磁盘再丢弃“脏的”pages。
pages的状态是在不断变化的,因此,对于读操作来说,它首先会检查pages的状态是否为WT_REF_MEM,然后设置一个hazard指针指向要读的pages,如果刷新后,pages的状态仍为WT_REF_MEM,读操作才能继续处理。
与此同时,evict线程想要淘汰pages时,它会先锁住pages,即将pages的状态设为WT_REF_LOCKED,然后检查pages上是否有读操作设置的hazard指针,如有,说明还有线程正在读这个page则停止evict,重新将page的状态设置为WT_REF_MEM;如果没有,则pages被淘汰出去。
Page的各种状态
针对一页page的每一种状态,详细描述如下:
WT_REF_DISK: 初始状态,page在磁盘上的状态,必须被读到内存后才能使用,当page被evict后,状态也会被设置为这个。
WT_REF_DELETED: page在磁盘上,但是已经从内存B-Tree上删除,当我们不在需要读某个leaf page时,可以将其删除。
WT_REF_LIMBO: page的映像已经被加载到内存,但page上还有额外的修改数据在lookasidetable上没有被加载到内存。
WT_REF_LOOKASIDE: page在磁盘上,但是在lookasidetable也有与此page相关的修改内容,在page可读之前,也需要加载这部分内容。
当对一个page进行reconcile时,如果系统中还有之前的读操作正在访问此page上修改的数据,则会将这些数据保存到lookasidetable;当page再被读时,可以利用lookasidetable中的数据重新构建内存page。
WT_REF_LOCKED: 当page被evict时,会将page锁住,其它线程不可访问。
WT_REF_MEM: page已经从磁盘读到内存,并且能正常访问。
WT_REF_READING: page正在被某个线程从磁盘读到内存,其它的读线程等待它被读完,不需要重复去读。
WT_REF_SPLIT: 当page变得过大时,会被split,状态设为WT_REF_SPLIT,原来指向的page不再被使用。
Page的大小参数
无论将数据从磁盘读到内存,还是从内存写到磁盘,都是以page为单位调度的,但是在磁盘上一个page到底多大?是否是最小分割单元?以及内存里面的各种page的大小对存储引擎的性能是否有影响?本节将围绕这些问题,分析与page大小相关的参数是如何影响存储引擎性能的。 总的来说,涉及到的关键参数和默认值如下表所示:
| 参数名称 | 默认配置值 | 含义 |
|---|---|---|
| allocation_size | 4KB | 磁盘上最小分配单元 |
| memory_page_max | 5MB | 内存中允许的最大page值 |
| internal_page_max | 4KB | 磁盘上允许的最大internal page值 |
| leaf_page_max | 32KB | 磁盘上允许的最大leaf page值 |
| internal_key_max | 1/10*internal_page | internal page上允许的最大key值 |
| leaf_key_max | 1/10*leaf_page | leaf page上允许的最大key值 |
| leaf_key_value | 1/2*leaf_page | leaf page上允许的最大value值 |
| split_pct | 75% | reconciled的page的分割百分比 |
详细说明如下:
- allocation_size:
MongoDB磁盘文件的最小分配单元(由WiredTiger自带的块管理模块来分配),一个page的可以由一个或多个这样的单元组成;默认值是4KB,与主机操作系统虚拟内存页的大小相当,大多数场景下不需要修改这个值。
- memory_page_max:
WiredTigerCache里面一个内存page随着不断插入修改等操作,允许增长达到的最大值,默认值为5MB。当一个内存page达到这个最大值时,将会被split成较小的内存pages且通过reconcile将这些pages写到磁盘pages,一旦完成写到磁盘,这些内存pages将从内存移除。
需要注意的是:split和reconcile这两个动作都需要获得page的排它锁,导致应用程序在此page上的其它写操作会等待,因此设置一个合理的最大值,对系统的性能也很关键。
如果值太大,虽然spilt和reconcile发生的机率减少,但一旦发生这样的动作,持有排它锁的时间会较长,导致应用程序的插入或修改操作延迟增大;
如果值太小,虽然单次持有排它锁的时间会较短,但是会导致spilt和reconcile发生的机率增加。
- internal_page_max:
磁盘上internalpage的最大值,默认为4KB。随着reconcile进行,internalpage超过这个值时,会被split成多个pages。
这个值的大小会影响磁盘上B-Tree的深度和internalpage上key的数量,如果太大,则internalpage上的key的数量会很多,通过遍历定位到正确leaf page的时间会增加;如果太小,则B-Tree的深度会增加,也会影响定位到正确leaf page的时间。
- leaf_page_max:
磁盘上leaf page的最大值,默认为32KB。随着reconcile进行,leaf page超过这个值时,会被split成多个pages。
这个值的大小会影响磁盘的I/O性能,因为我们在从磁盘读取数据时,总是期望一次I/O能多读取一点数据,所以希望把这个参数调大;但是太大,又会造成读写放大,因为读出来的很多数据可能后续都用不上。
- internal_key_max:
internalpage上允许的最大key值,默认大小为internalpage初始值的1/10,如果超过这个值,将会额外存储。导致读取key时需要额外的磁盘I/O。
- leaf_key_max:
leaf page上允许的最大key值,默认大小为leaf page初始值的1/10,如果超过这个值,将会额外存储。导致读取key时需要额外的磁盘I/O。
- leaf_value_max:
leaf page上允许的最大value值(保存真正的集合数据),默认大小为leaf page初始值的1/2,如果超过这个值,将会额外存储。导致读取value时需要额外的磁盘I/O。
- split_pct:
内存里面将要被reconciled的 page大小与internal_page_max或leaf_page_max值的百分比,默认值为75%,如果内存里面被reconciled的page能够装进一个单独的磁盘page上,则不会发生spilt,否则按照该百分比值*最大允许的page值分割新page的大小。
Page无锁及压缩
https://blog.csdn.net/weixin_45583158/article/details/100143033
参考文章
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341