

【Python | 边学边敲边记】第二次:深度&&广度优先算法


一、前言
以后尽量每天更新一篇,也是自己的一个学习打卡!加油!今天给大家分享的是,Python里深度/广度优先算法介绍及实现。
二、深度、广度优先算法简介
1.深度优先搜索(DepthFirstSearch)
深度优先搜索的主要特征就是,假设一个顶点有不少相邻顶点,当我们搜索到该顶点,我们对于它的相邻顶点并不是现在就对所有都进行搜索,而是对一个顶点继续往后搜索,直到某个顶点,他周围的相邻顶点都已经被访问过了,这时他就可以返回,对它来的那个顶点的其余顶点进行搜索。
深度优先搜索的实现可以利用递归很简单地实现。
2.广度优先搜索(BreadthFirstSearch)
广度优先搜索相对于深度优先搜索侧重点不一样,深度优先好比是一个人走迷宫,一次只能选定一条路走下去,而广度优先搜索好比是一次能够有任意多个人,一次就走到和一个顶点相连的所有未访问过的顶点,然后再从这些顶点出发,继续这个过程。
具体实现的时候我们使用先进先出队列来实现这个过程:
首先将起点加入队列,然后将其出队,把和起点相连的顶点加入队列,
将队首元素v出队并标记他
将和v相连的未标记的元素加入队列,然后继续执行步骤2直到队列为空
广度优先搜索的一个重要作用就是它能够找出最短路径,这个很好理解,因为广度优先搜索相当于每次从一个起点开始向所有可能的方向走一步,那么第一次到达目的地的这个路径一定是最短的,而到达了之后由于这个点已经被访问过而不会再被访问,这个路径就不会被更改了。
三、看代码,边学边敲边记深度优先、广度优先算法
1'''
2date : 2018.7.29
3author : 极简XksA
4goal : 深度/广度优先算法
5'''
6
7# 深度优先: 根左右 遍历
8# 广度优先: 层次遍历,一层一层遍历
9
10# 深度优先: 根左右 遍历 (递归实现)
11def depth_tree(tree_node):
12 if tree_node is not None:
13 print(tree_node._data)
14 if tree_node._left is not None:
15 return depth_tree(tree_node._left) # 递归遍历
16 if tree_node._right is not None:
17 return depth_tree(tree_node._right) # 递归遍历
18
19# 广度优先: 层次遍历,一层一层遍历(队列实现)
20def level_queue(root):
21 if root is None:
22 return
23 my_queue = []
24 node = root
25 my_queue.append(node) # 根结点入队列
26 while my_queue:
27 node = my_queue.pop() # 出队列
28 print(node.elem) # 访问结点
29 if node.lchild is not None:
30 my_queue.append(node.lchild) # 入队列
31 if node.rchild is not None:
32 my_queue.append(node.rchild) # 入队列
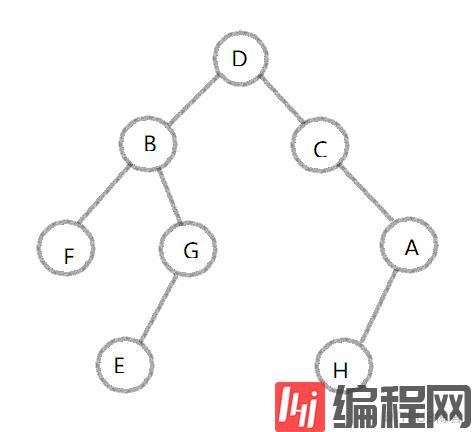
方法一:列表法
1# 树的数据结构设计
2# 1.列表法
3# 简述:列表里包含三个元素:根结点、左结点、右结点
4my_Tree = [
5 'D', # 根结点
6 ['B',
7 ['F',[],[]],
8 ['G',['E',[],[]],[]]
9 ], # 左子树
10 ['C',
11 [],
12 ['A',['H',[],[]],[]]
13 ] # 右子树
14]
15
16# 列表操作函数
17# pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
18# insert() 函数用于将指定对象插入列表的指定位置,没有返回值。
19
20# 深度优先: 根左右 遍历 (递归实现)
21def depth_tree(tree_node):
22 if tree_node:
23 print(tree_node[])
24 # 访问左子树
25 if tree_node[1]:
26 depth_tree(tree_node[1]) # 递归遍历
27 # 访问右子树
28 if tree_node[2]:
29 depth_tree(tree_node[2]) # 递归遍历
30depth_tree(my_Tree)
31# result:
32# D B F G E C A H
33
34# 广度优先: 层次遍历,一层一层遍历(队列实现)
35def level_queue(root):
36 if not root:
37 return
38 my_queue = []
39 node = root
40 my_queue.append(node) # 根结点入队列
41 while my_queue:
42 node = my_queue.pop() # 出队列
43 print(node[]) # 访问结点
44 if node[1]:
45 my_queue.append(node[1]) # 入队列
46 if node[2]:
47 my_queue.append(node[2]) # 入队列
48level_queue(my_Tree)
49# result :
50# D B C F G A E H
方法二:构造类节点法
1#2.构造类
2# Tree类,类变量root 为根结点,为str类型
3# 类变量right/left 为左右节点,为Tree型,默认为空
4class Tree:
5 root = ''
6 right = None
7 left = None
8 # 初始化类
9 def __init__(self,node):
10 self.root = node
11
12 def set_root(self,node):
13 self.root = node
14
15 def get_root(self):
16 return self.root
17
18# 初始化树
19# 设置所有根结点
20a = Tree('A')
21b = Tree('B')
22c = Tree('C')
23d = Tree('D')
24e = Tree('E')
25f = Tree('F')
26g = Tree('G')
27h = Tree('H')
28# 设置节点之间联系,生成树
29a.left = h
30b.left = f
31b.right = g
32c.right = a
33d.left = b
34d.right = c
35g.left = e
36
37# 深度优先: 根左右 遍历 (递归实现)
38def depth_tree(tree_node):
39 if tree_node is not None:
40 print(tree_node.root)
41 if tree_node.left is not None:
42 depth_tree(tree_node.left) # 递归遍历
43 if tree_node.right is not None:
44 depth_tree(tree_node.right) # 递归遍历
45depth_tree(d) # 传入根节点
46# result:
47# D B F G E C A H
48
49# 广度优先: 层次遍历,一层一层遍历(队列实现)
50def level_queue(root):
51 if root is None:
52 return
53 my_queue = []
54 node = root
55 my_queue.append(node) # 根结点入队列
56 while my_queue:
57 node = my_queue.pop() # 出队列
58 print(node.root) # 访问结点
59 if node.left is not None:
60 my_queue.append(node.left) # 入队列
61 if node.right is not None:
62 my_queue.append(node.right) # 入队列
63level_queue(d)
64# result :
65# D B C F G A E H
四、后言
可能大家会好奇,深度优先算法、广度优先算法对爬虫有什么用,不用好奇,慢慢后面就会懂得了。提前透露:几乎所有网站都有首页、XXX、XXX、XXX…在每个分页下,又有很多分页,这样所有url之间的联系实际上就可以比喻成一棵树,当我们想要系统爬取时,为了不重复爬取,对这颗树的遍历就尤为重要了,这里说到的深度优先、广度优先为最常用的遍历算法。
边敲边学边做,坚持学习分享。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












