

全网多种方法分析解决HTTP Status 404资源未找到的错误,TCP的3次握手,dns域名解析,发起http请求以及cookie和session的区别


文章目录
1. 文章引言
正赶上最近ChatGPT很火,于是借助ChatGPT来解释HTTP Status 404,如下所示:

HTTP Status 404:
The HTTP Status 404 means that the requested resource was not found on the server. This is commonly used in response to a failed HTTP request and can be caused by mistyping an URL, spelling mistakes, or trying to access a file or resource that no longer exists.
可惜的是,ChatGPT给出的是英文的解释,我们不妨翻译成中文,如下所示:
HTTP状态404表示在服务器上找不到请求的资源。这通常用于响应失败的 HTTP 请求,可能是由于键入错误的URL、拼写错误或尝试访问不再存在的文件或资源引起的。
根据翻译可知,如果我们请求的资源在服务器中不存在,或者资源虽然存在,但我们发送的请求(URL)在服务器没有找到该所需资源,便会报出404的错误。
404错误也是互联网上最常见的错误之一,该错误消息可能与server not found(无法找到服务器)或其他类似消息产生混淆。
2. 简述URL
上文提到了URL,出现404最常见的的是路径(URL)错误。
那么什么是URL,它有怎么样的魅力?接下来我便分析它。
URL的全称是Uniform Resource Locator,中文翻译是统一资源定位符,又叫统一资源定位器、定位地址、URL地址,俗称网页地址或简称网址。
正如其名,就是用于定位服务的资源在哪?发送的Request去哪里找,然后,服务器再做出逻辑响应(Response)。
- 统一资源定位符的标准格式如下:
[协议类型]://[服务器地址]:[端口号]/[资源层级UNIX文件路径][文件名]?[查询]#[片段ID]
- 统一资源定位符的完整格式如下:
[协议类型]://[访问资源需要的凭证信息]@[服务器地址]:[端口号]/[资源层级UNIX文件路径][文件名]?[查询]#[片段ID]
比如此URL:http://127.0.0.1:8081/user/list?kerword=test&username=jack,其中格式如下:
-
http是协议 -
127.0.0.1是服务器地址 -
8081是服务器上的端口号 -
/user/list是路径 -
其中
/分隔目录和子目录。 -
?kerword=test&username=jack是查询。
?分隔实际的URL和参数,这里很容易出错。
&用于参数间的分隔符,= 等于(不是赋值)。
除此之外,还有+表示空格,#表示书签。
数据(除了数字)都会转换成以UTF8的URL编码。
格式需要注意的地方:
-
一般使用
Tomcat和nginx等服务器启动的项目,需要查看端口是否正确。 -
协议名
http/https,域名或者ip地址是否有误? -
/分割符,以/区别路径中的每一个目录名称。这样我们我们可以根据URL一层层的去查找我们项目的目录,分析出现404可能的原因是否为路径错误或者资源不存在。 -
&表示的参数可以预估其值是否达到预期
3. http完整请求
我们为什么了解http请求呢?
了解http请求的过程有助于我们理解web的大体运行流程。
总体流程如下:
-
先域名解析
-
然后发起
TCP的3次握手 -
其次建立
TCP,连接后发起http请求 -
再次服务器响应
http请求,浏览器得到html代码 -
接着浏览器解析
html代码,并请求html代码中的资源(如js、css、图片等) -
最后浏览器对页面进行渲染呈现给用户。
接下来,我便详细讲解它们都干些什么?
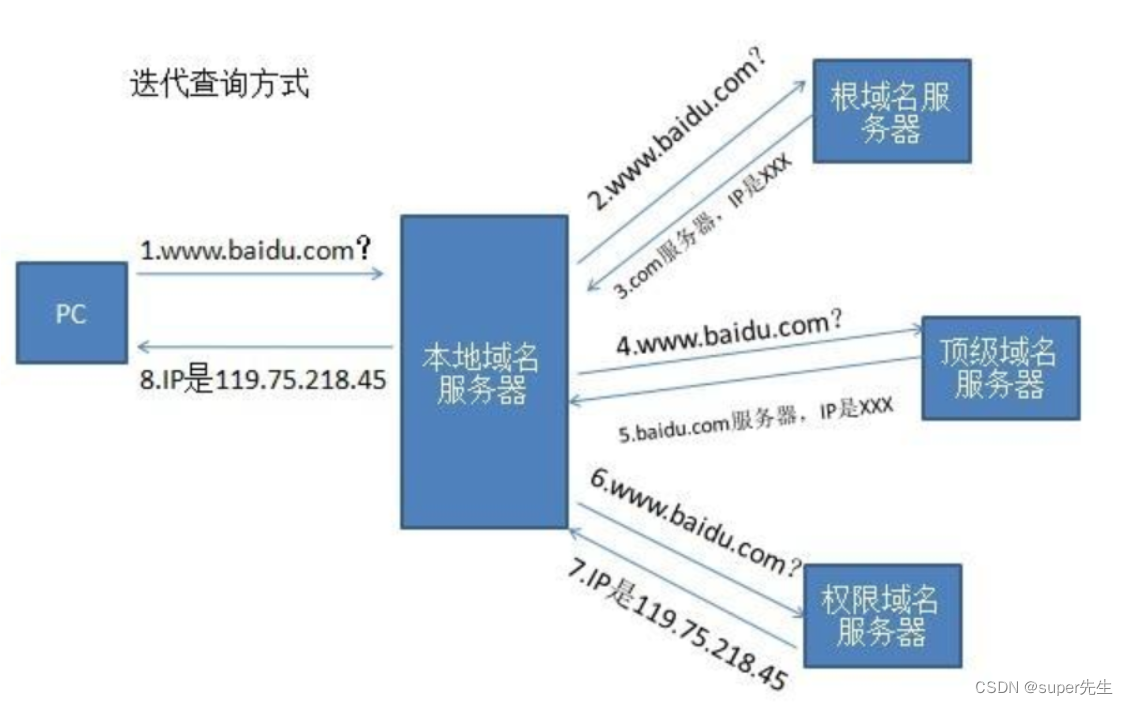
3.1 DNS域名解析
dns是什么?
它使用UDP传输的方式,将主机域名转换为ip地址,属于应用层协议,。
dns工作原理:
-
主机向本地域名服务器的查询一般都是采用递归查询。
-
本地域名服务器向根域名服务器的查询的迭代查询。
-
当用户输入域名时,浏览器先检查自己的缓存中是否存在这个域名映射的
ip地址,有则解析结束。 -
若没命中,则检查操作系统缓存(如
Windows的hosts)中有没有解析过的结果,有则解析结束。 -
若无命中,则请求本地域名服务器解析(
LDNS)。 -
若
LDNS没有命中,就直接跳到根域名服务器请求解析。根域名服务器返回给LDNS一个主域名服务器地址。 -
此时
LDNS再发送请求给上一步返回的gTLD( 通用顶级域), 接受请求的gTLD查找并返回这个域名对应的Name Server的地址。 -
Name Server根据映射关系表找到目标ip,返回给LDNS。 -
LDNS缓存这个域名和对应的ip, 把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束。
-
dns解析的整体流程如下图所示:
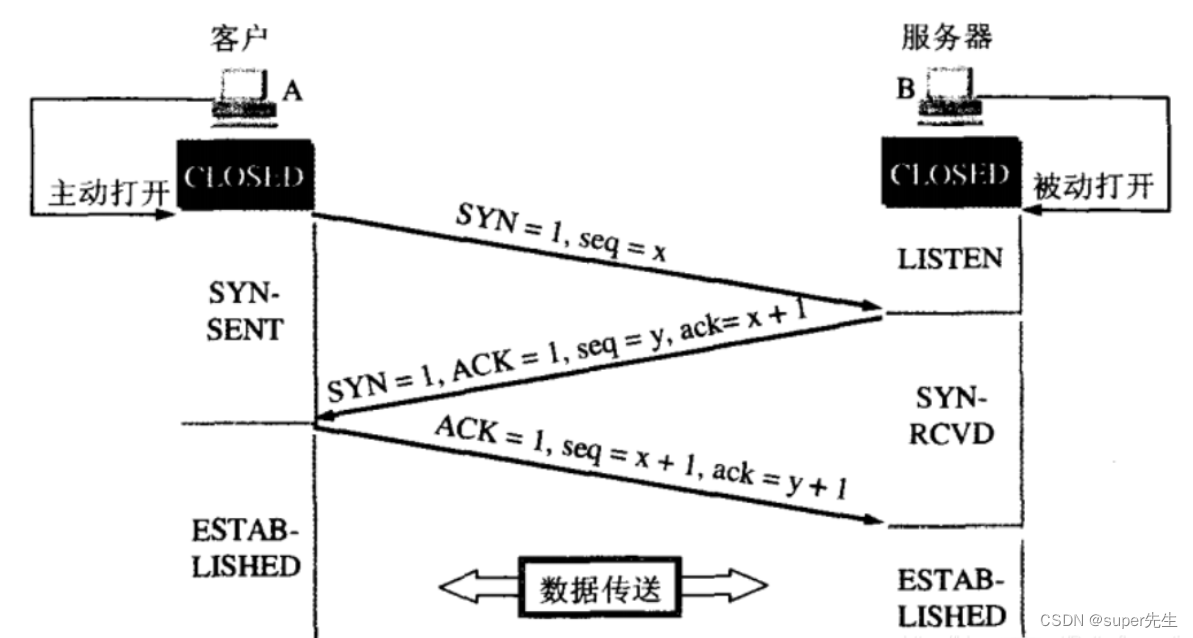
3.2 TCP的3次握手
tcp为什么要三次握手?是为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
三次握手过程如下:
-
第一次握手:建立连接时,客户端发送
syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认。 -
第二次握手:服务器收到
syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态。 -
第三次握手:客户端收到服务器的
SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据,如下图所示:
有人问会不会因为丢包而导致404错误?可能性极小,这里不得不提TCP是如何保证可靠传输的 (与上面三次握手协议都是校招面试的重点),如下所示:
-
三次握手
-
将数据截断为合理的长度。应用数据被分割成
TCP认为最适合发送的数据块(按字节编号,合理分片) -
超时重发。当
TCP发出一个段后,它启动一个定时器,如果不能及时收到一个确认就重发 -
确认应答:对于收到的请求,给出确认响应
-
校验和:校验出包有错,丢弃报文段,不给出响应
-
序列号:对失序数据进行重新排序,然后才交给应用层
-
丢弃重复数据:对于重复数据 , 能够丢弃重复数据
-
流量控制。
TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出 -
拥塞控制。当网络拥塞时,减少数据的发送
3.3 发起http请求
http是一个无状态的请求/响应协议,但是这不能满足现在的业务。
因此,出现了用于保存状态的cookie和session。
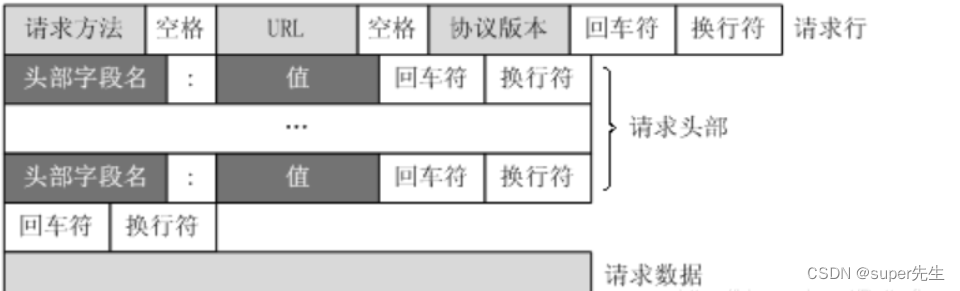
一个完整的HTTP请求报文包括请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。如下图所示:
当然,我们也可以打开浏览器(如chrome,edge,火狐等)的调试模式:
-
F12进入到调试模式 -
找到
Network(edge浏览器叫做网络) -
查看信息。
【注意】如果你的F12不生效,可以尝试使用fn + F12。若这样还不生效,可以点击鼠标右键,找到并单击检查即可。
打开浏览器的调试模式后,你会看到很多请求信息或响应信息,我们也可以基于它们进行开发操作,如下图所示:
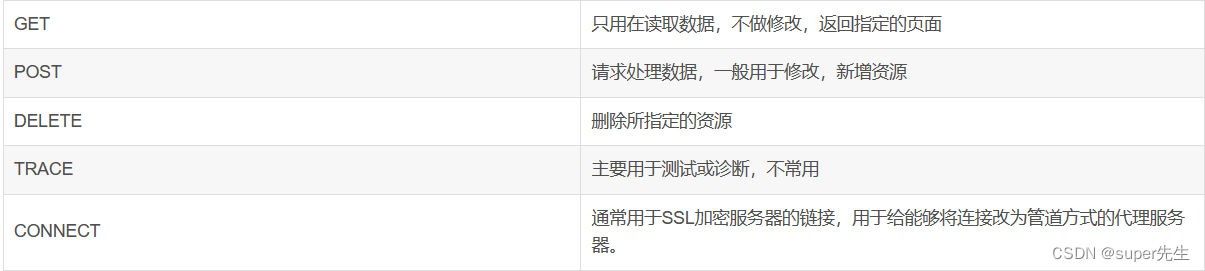
我们再了解HTTP请求的常见方法:GET,POST,DELETE,TRACE ,CONNECT 。
3.4 浏览器解析html代码
浏览器在解析html代码时,并请求html代码中的资源(如js、css、图片等)。
html页面主要由dom、css、javascript等部分构成,还可能引入img、iframe等其他资源。
浏览器接收到html代码,可能是一份完整的文档,也可能是一个chunk,即开始解析。
解析过程是先构建dom树,再根据dom树构建渲染树,最后浏览器将渲染树绘制到页面上。
3.5 浏览器对页面进行渲染呈现给用户
什么是渲染?
渲染在电脑绘图中是指用软件从模型生成图像的过程,也就是将我们html的逻辑转换成我们肉眼可见的对象。
具体参看博客:浏览器渲染过程与性能优化
4. 解决404错误的方法
- 目录不能被引用。
可以在Eclipse的包资源管理器(Package Explorer)检查文件存放的位置。
由于META-INF和WEB-INF文件夹下的内容不对外发布,如果你引用了带这两个目录的文件,肯定是不允许,如下URL地址就是错误的:
http://localhost:8081/testProject/WEB-INF/index.html-
URL输入错误,如下为排错方法:-
先查看
URL的IP地址和端口号是否书写正确。 -
其次查看上下文路径是否正确,比如
Project -> Properties -> MyElipse -> Web -> Web Context-root,检查这个路径名称是否书写正确。 -
最后检查一下文件名称是否书写正确。
-
-
未部署
Web应用 -
Tomcat器中web.xml中的问题
假如,你的web应用程序有多个jsp页面,当你点击web应用程序的虚拟根目录时,可能会出现404错误。
此时,你只需要修改Tomcat服务器中web.xml,如下代码所示:
<init-param> <param-name>listparam-name> <param-value>falseparam-value> init-param>如果在6.0.18版本error:The requested resource () is not available. 总是无法访问/myapp/*.jsp文件,可以将 /ROOT中build.xml文件copy一份到myapp。
【注意】把里面所有的ROOT用myapp代替, 应该就OK。
-
WEB-INF下面必须要有几个固定的文件夹和文件-
web.xml该web app的配置文件 -
lib该web app用到的库文件 -
classes存放编译好的servlet
-
请注意这些名字,我曾经把classes写成class,查错查了半宿还没解决。
所以,写这些时千万要仔细,要不会浪费更多的精力去查错。
- 如果运行的是
servlet(.class)文件,而非.jsp文件,需在web.xml中加上以下字段:
<servlet> <servlet-name>TestServletservlet-name> <servlet-class>TestServletservlet-class> servlet> <servlet-mapping> <servlet-name>TestServletservlet-name> <url-pattern>/TestServleturl-pattern> servlet-mapping>其中,TestServlet改为你要运行的文件名。
【注意】web.xml是WEB-INF下面的。
struts.xml配置错误
可能是你的Action值写错,或者链接URL写错。
比如commons-lang3-3.1.jar文件到WEB-INF/lib目录下,struts2最新的web开发包如下:
当然,如果你的是maven项目,直接在pom.xml中引入jar包即可,如下所示:
<dependency> <groupId>org.apache.commonsgroupId> <artifactId>commons-lang3artifactId> <version>3.7version>dependency>- 检查同一个项目,是否启动了多个
java服务
有时,后台没有关闭之前的服务,你又重新启动,可能会报错404。
5. 补充知识点
5.1 cookie和session的区别
-
存储的位置不同:
-
cookie:存放在客户端 -
session:存放在服务端,session存储的数据比较安全
-
-
存储的数据类型不同:两者都是
key-value的结构,但针对value的类型是有差异的:-
cookie:value只能是字符串类型 -
session:value是Object类型
-
-
存储的数据大小限制不同:
-
cookie:大小受浏览器的限制,很多是是4K的大小 -
session:理论上受当前内存的限制
-
-
生命周期的控制,
cookie的生命周期随着浏览器关闭而消亡。-
cookie的生命周期是累计的,从创建时,就开始计时,30分钟后,cookie生命周期结束 -
session的生命周期是间隔的,从创建时,开始计时如在30分钟,没有访问session,那么session生命周期被销毁
-
来源地址:https://blog.csdn.net/lvoelife/article/details/129051408
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













