

用Python调用OpenAI API做有趣的事


GPT 迭代过程概要表:
| 版本 | 发布时间 | 训练方案 | 参数量 | 是否开放接口 |
|---|---|---|---|---|
| GPT(GPT-1) | 2018 年 6 月 | 无监督学习 | 1.17 亿 | 是 |
| GPT-2 | 2019 年 2 月 | 多任务学习 | 15 亿 | 是 |
| GPT-3 | 2020 年 5 月 | 海量参数 | 1,750 亿 | 是 |
| GPT-3.5 | 2022 年 12 月 | 针对对话场景优化 | 1,750 亿 | 是 |
| GPT-4 | 2023 年 3 月 | 万亿参数 | 100万亿 | 否 |
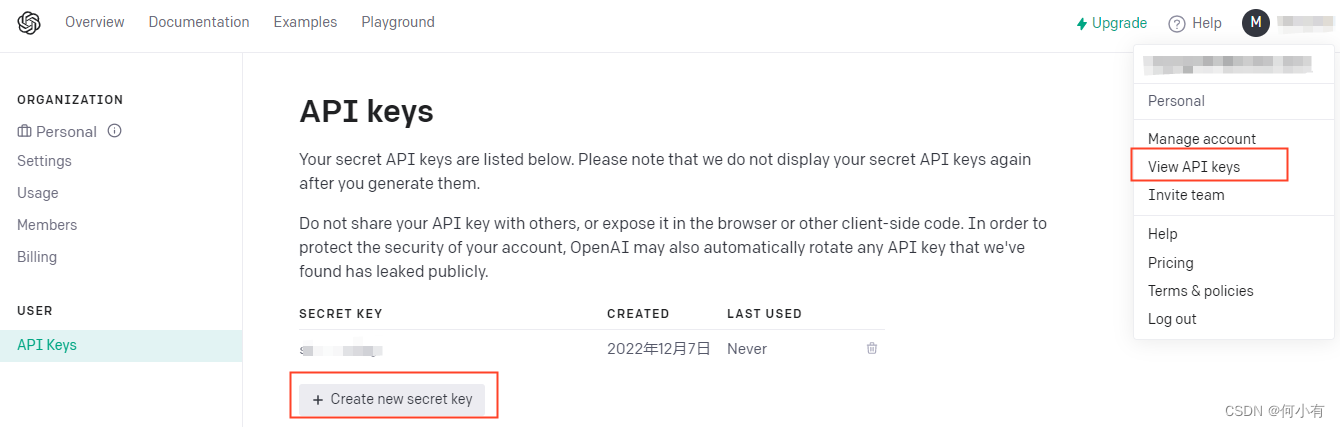
获取 API KEY
获得可用 OpenAI 账号后, View API keys -> API Keys 页面,点击 Create new secret key 获取一个 openai.api_key 再继续后面的内容。
使用 Python 调用 OpenAI API 的方式非常便捷,只需安装 OpenAI 提供的 openai 库就可以调用其 API 服务:
pip install openaiGPT - 3.5 API
将模型 ID 设置为 gpt-3.5-turbo 即可调用,快速调用代码如下:
import openaiopenai.api_key = 'xx-xxxxxxxx'# 通过 `系统(system)` 角色给 `助手(assistant)` 角色赋予一个人设messages = [{'role': 'system', 'content': '你是一个乐于助人的诗人。'}]# 在 messages 中加入 `用户(user)` 角色提出第 1 个问题messages.append({'role': 'user', 'content': '作一首诗,要有风、要有肉,要有火锅、要有雾,要有美女、要有驴!'})# 调用 API 接口response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages,)# 在 messages 中加入 `助手(assistant)` 的回答messages.append({ 'role': response['choices'][0]['message']['role'], 'content': response['choices'][0]['message']['content'],})# 在 messages 中加入 `用户(user)` 角色提出第 2 个问题messages.append({'role': 'user', 'content': '好诗!好诗!'})# 调用 API 接口response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages,)# 在 messages 中加入 `助手(assistant)` 的回答messages.append({ 'role': response['choices'][0]['message']['role'], 'content': response['choices'][0]['message']['content'],})# 查看整个对话print(messages)整个对话 messages 的内容:
messages= [ { 'role': 'system', 'content': '你是一个乐于助人的诗人。' }, { 'role': 'user', 'content': '作一首诗,要有风、要有肉,要有火锅、要有雾,要有美女、要有驴!' }, { 'role': 'assistant', 'content': '天地间万物生,\n有风与肉相承,\n火锅酒透心,\n烟雾裹美人。\n\n驴儿踏 古路,\n风中草木舞,\n美女倚门檐,\n虽无风却动人。\n\n火锅汤沸腾,\n辣味令人咳,\n但见驴儿笑,\n真好一趟行。\n\n愿伴佳人笑语间,\n品尽浓情佳酿,\n敬心献驴蹄,\n唯愿岁月长。' }, { 'role': 'user', 'content': '好诗!好诗!' }, { 'role': 'assistant', 'content': '谢 谢夸奖,希望能一直为您带来愉悦!' },]逐字打印的流式处理
在调用 OpenAI API 时,同步类型的接口响应会很慢,抛开网络因素,主要的延迟和等待是在 AI 模型的响应生成过程中。因此,我们可以通过流式请求方式,实时获取 AI 模型的生成响应,从而提升用户等待体验:
import openaidef gpt_35_api_stream(api_key: str, messages: list): """为提供的对话消息创建新的回答 (流式传输) Args: messages (list): 完整的对话消息 api_key (str): OpenAI API 密钥 Returns: tuple: (results, error_desc) """ try: openai.api_key = api_key response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages, stream=True, ) completion = {'role': '', 'content': ''} for event in response: if event['choices'][0]['finish_reason'] == 'stop': print(f'收到的完成数据: {completion}') break for delta_k, delta_v in event['choices'][0]['delta'].items(): print(f'流响应数据: {delta_k} = {delta_v}') completion[delta_k] += delta_v messages.append(completion) # 直接在传入参数 messages 中追加消息 return (True, '') except Exception as err: return (False, f'OpenAI API 异常: {err}')if __name__ == '__main__': messages = [{'role': 'system','content': '你是一个乐于助人的诗人。'},{'role': 'user','content': '作一首诗,要有风、要有肉,要有火锅、要有雾,要有美女、要有驴!'},] print(gpt_35_api_stream('xx-xxxxxxxx', messages)) print(messages)上面的代码如果顺利,控制台会打印的内容如下:
流响应数据: role = assistant流响应数据: content = 风流响应数据: content = 吹流响应数据: content = 肉流响应数据: content = 片流响应数据: content = 香流响应数据: content = 味流响应数据: content = 飘流响应数据: content = ,流响应数据: content = 火流响应数据: content = 锅流响应数据: content = 烧流响应数据: content = 着流响应数据: content = 美流响应数据: content = 女流响应数据: content = 腰流响应数据: content = 。流响应数据: content = 雾流响应数据: content = 气流响应数据: content = 蒸流响应数据: content = 腾流响应数据: content = 驴流响应数据: content = 哼流响应数据: content = 叫流响应数据: content = ,流响应数据: content = 山流响应数据: content = 河流响应数据: content = 秀流响应数据: content = 丽流响应数据: content = 如流响应数据: content = 画流响应数据: content = 桥流响应数据: content = 。流响应数据: content = 人流响应数据: content = 生流响应数据: content = 短流响应数据: content = 暂流响应数据: content = 不流响应数据: content = 易流响应数据: content = 过流响应数据: content = ,流响应数据: content = 幸流响应数据: content = 有流响应数据: content = 滋流响应数据: content = 味流响应数据: content = 浓流响应数据: content = 如流响应数据: content = 浆流响应数据: content = 。流响应数据: content = 今流响应数据: content = 宵流响应数据: content = 共流响应数据: content = 享流响应数据: content = 美流响应数据: content = 食流响应数据: content = 节流响应数据: content = ,流响应数据: content = 欢流响应数据: content = 聚流响应数据: content = 一流响应数据: content = 堂流响应数据: content = 把流响应数据: content = 酒流响应数据: content = 浇流响应数据: content = 。收到的完成数据: {'role': 'assistant', 'content': '风吹肉片香味飘,\n\n火锅烧着美女腰。\n\n雾气蒸腾驴哼叫,\n\n山河秀丽如画桥。\n\n人生短暂不易过,\n\n幸有滋味浓如浆。\n\n今宵共享美食节,\n\n欢聚一堂把酒浇。'}(True, '')[{'role': 'system', 'content': '你是一个乐于助人的诗人。'}, {'role': 'user', 'content': '作一首诗,要有风、要有肉,要有火锅、要有雾,要有美女、要有驴!'}, {'role': 'assistant', 'content': '风吹肉片香味飘,\n\n火锅烧着美女腰。\n\n雾气蒸腾驴哼叫,\n\n山河秀丽如画桥。\n\n人生短暂不易过,\n\n幸有滋味浓如浆。\n\n今宵共享美食节,\n\n欢聚一堂把酒浇。'}]GPT - 3 API
OpenAI 文本编写
调用 openai.Completion.create 函数需要了解几个基本参数:
model: 要使用的模型的 ID,访问 OpenAI Docs Models 页面可以查看全部可用的模型prompt: 生成结果的提示文本,即你想要得到的内容描述max_tokens: 生成结果时的最大 tokens 数,不能超过模型的上下文长度,可以把结果内容复制到 OpenAI Tokenizer 来了解 tokens 的计数方式temperature: 控制结果的随机性,如果希望结果更有创意可以尝试 0.9,或者希望有固定结果可以尝试 0.0top_p: 一个可用于代替temperature的参数,对应机器学习中 nucleus sampling,如果设置 0.1 意味着只考虑构成前 10% 概率质量的 tokensfrequency_penalty: [控制字符的重复度] -2.0 ~ 2.0 之间的数字,正值会根据新 tokens 在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性(以恐怖故事为例)= -2.0:当早上黎明时,我发现我家现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在现在(频率最高字符是 “现”,占比 44.79%)= -1.0:他总是在清晨漫步在一片森林里,每次漫游每次每次游游游游游游游游游游游游游游游游游游游游游游游游游游游游游(频率最高字符是 “游”,占比 57.69%)= 0.0:当一道阴森的风吹过早晨的小餐馆时,一个被吓得发抖的人突然出现在门口,他的嘴唇上挂满血迹,害怕的店主决定给他一份早餐,却发现他的早餐里满是血渍。(频率最高字符是 “的”,占比 8.45%)= 1.0:一个熟睡的女孩被一阵清冷的风吹得不由自主地醒了,她看到了早上还未到来的黑暗,周围只有像诉说厄运般狂风呼啸而过。(频率最高字符是 “的”,占比 5.45%)= 2.0:每天早上,他都会在露台上坐着吃早餐。柔和的夕阳照耀下,一切看起来安详寂静。但是有一天,当他准备端起早食的时候发现胡同里清冷的风扑进了他的意识中并带来了不安全感…… (频率最高字符是 “的”,占比 4.94%)
presence_penalty: [控制主题的重复度] -2.0 ~ 2.0 之间的数字,正值会根据到目前为止是否出现在文本中来惩罚新 tokens,从而增加模型谈论新主题的可能性(以云课堂的广告文案为例)= -2.0:家长们,你们是否为家里的孩子学业的发展而发愁?担心他们的学习没有取得有效的提高?那么,你们可以放心,可以尝试云课堂!它是一个为从幼儿园到高中的学生提供的一个网络平台,可以有效的帮助孩子们提高学习效率,提升学习成绩,帮助他们在学校表现出色!让孩子们的学业发展更加顺利,家长们赶紧加入吧!(抓住一个主题使劲谈论)= -1.0:家长们,你们是否还在为孩子的学习成绩担忧?云课堂给你们带来了一个绝佳的解决方案!我们为孩子提供了专业的学习指导,从幼儿园到高中,我们都能帮助孩子们在学校取得更好的成绩!让孩子们在学习中更轻松,更有成就感!加入我们,让孩子们拥有更好的学习体验!(紧密围绕一个主题谈论)= 0.0:家长们,你们是否担心孩子在学校表现不佳?云课堂将帮助您的孩子更好地学习!云课堂是一个网络平台,为从幼儿园到高中的学生提供了全面的学习资源,让他们可以在学校表现出色!让您的孩子更加聪明,让他们在学校取得更好的成绩,快来云课堂吧!(相对围绕一个主题谈论)= 1.0:家长们,你们的孩子梦想成为最优秀的学生吗?云课堂就是你们的答案!它不仅可以帮助孩子在学校表现出色,还能够提供专业教育资源,助力孩子取得更好的成绩!让你们的孩子一路走向成功,就用云课堂!(避免一个主题谈论的太多)= 2.0:家长们,您有没有想过,让孩子在学校表现出色可不是一件容易的事?没关系!我们为您提供了一个优质的网络平台——云课堂!无论您的孩子是小学生、初中生还是高中生,都能够通过云课堂找到最合适的学习方法,帮助他们在学校取得优异成绩。快来体验吧!(最大程度避免谈论重复的主题)
stop: 最大长度为 4 的字符串列表,一旦生成的 tokens 包含其中的内容,将停止生成并返回结果
故事创作
输入 prompt 内容:
主题: 早餐 风两句话的恐怖故事:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='主题: 早餐 风\n两句话的恐怖故事:', temperature=0.8, max_tokens=120, top_p=1.0, frequency_penalty=0.5, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
传说当晨风吹过的时候,一个可怕的早餐怪物就会出现,它会从你的厨房里抓走你的食物,然后吞下它们!
餐厅评论
输入 prompt 内容:
根据这些笔记写一篇餐厅评论名称:大头鱼烧烤茄子很棒,很吵,服务态度好,价格便宜。评论:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='根据这些笔记写一篇餐厅评论\n名称:大头鱼烧烤\n茄子很棒,很吵,服务态度好,价格便宜。\n评论:', temperature=0.5, max_tokens=300, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
我最近去了大头鱼烧烤,真的很棒!服务态度很好,价格也很便宜。我尤其喜欢他们的茄子,味道非常棒!唯一缺点就是有点吵,但是这也是一家烧烤店的常态,所以我还是很满意的。总而言之,我强烈推荐大头鱼烧烤!
广告文案
输入 prompt 内容:
为以下产品写一则创意广告,在微博上针对家长进行宣传:产品:云课堂是一个网络平台,帮助从幼儿园到高中的学生在学校表现出色。完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='为以下产品写一则创意广告,在微博上针对家长进行宣传:\n产品:云课堂是一个网络平台,帮助从幼儿园到高中的学生在学校表现出色。', temperature=0.5, max_tokens=300, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
家长们,你们的孩子是否想要在学校表现出色?云课堂是一个网络平台,可以帮助从幼儿园到高中的学生提高学习成绩,让他们在学校里取得更好的成绩。云课堂拥有丰富的资源,专业的老师,精心设计的课程,可以帮助孩子们更好地理解学习内容,提高学习效率。让你的孩子在学校表现出色,就选择云课堂吧!
会议记录
输入 prompt 内容:
将我的速记转换成会议纪要张三:利润增长50%李四:新服务器上线了王五:需要更多时间来修复BUG李四:可以帮忙赵六:Beta测试即将完成完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='将我的速记转换成会议纪要\n张三:利润增长50%\n李四:新服务器上线了\n王五:需要更多时间来修复BUG\n李四:可以帮忙\n赵六:Beta测试即将完成', temperature=0.0, max_tokens=300, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
会议纪要:
- 张三报告,公司利润增长了50%。
- 李四报告,新服务器已经上线。
- 王五报告,需要更多时间来修复BUG,李四表示可以提供帮助。
- 赵六报告,Beta测试即将完成。
面试问题
输入 prompt 内容:
为我面试一位Python后台开发创建一个包含8个问题的清单:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='为我面试一位Python后台开发创建一个包含8个问题的清单:', temperature=0.5, max_tokens=500, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
- 请描述你对Python后台开发的了解。
- 你有使用过哪些Python Web框架?
- 你是如何处理数据库的?
- 你曾经处理过大型数据集吗?
- 你有使用过什么样的API?
- 你有使用过Python中的任务调度模块吗?
- 你有使用过Python中的日志模块吗?
- 你有使用过Python中的安全和加密模块吗?
头脑风暴
输入 prompt 内容:
集思广益,提出一些结合AI和自动化测试的想法:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='集思广益,提出一些结合AI和自动化测试的想法:', temperature=0.6, max_tokens=500, top_p=1.0, frequency_penalty=1.0, presence_penalty=1.0,)print(response.choices[0].text)响应的结果文本:
- 使用AI技术来自动生成测试用例:通过分析已有的代码及其行为,AI 可以自动生成覆盖所有可能情况的测试用例。
- 让 AI 来优化测试套件:通过将历史上失败的样例和新出现的样例作为特征数据集,AI 可以学习并改进当前的测试套件。
- 使用 AI 来预测应用性能:通过利用数据采集、日志分析和即时监控来帮助开发人员了解如何优化应用性能。
- 通过 AI 来实现对大量信息中快速定高限和低限: 通过场景建立、数学优化方法、回归方法等, AI 系统可以帮助开发者在一定限度之内尽快找出合理考虑各要素之间关系, 精准地定高低界限。
论文大纲
输入 prompt 内容:
为一篇关于《浮士德》中魔鬼形象及其矛盾性的文章创建一个大纲:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='为一篇关于《浮士德》中魔鬼形象及其矛盾性的文章创建一个大纲:', temperature=0.3, max_tokens=600, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
I. 引言
A. 《浮士德》的背景
B. 主要角色
II. 魔鬼形象
A. 魔鬼的外表
B. 魔鬼的性格特征
III. 魔鬼的矛盾性
A. 对人类的态度
B. 对浮士德的态度
IV. 结论
A. 魔鬼的矛盾性
B. 对浮士德的影响
学习笔记
输入 prompt 内容:
研究中国古代文论时我应该知道的5个要点是什么?完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='研究中国古代文论时我应该知道的5个要点是什么?', temperature=0.3, max_tokens=800, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
- 中国古代文论的发展史:从《诗经》到《文心雕龙》,介绍中国古代文论的发展历程。
- 中国古代文论的主要思想:介绍中国古代文论的主要思想,如儒家文论、道家文论、墨家文论、法家文论等。
- 中国古代文论的主要著作:介绍中国古代文论的主要著作,如《论语》、《孟子》、《庄子》、《诗经》、《文心雕龙》等。
- 中国古代文论的影响:介绍中国古代文论对中国文学、文化、思想等方面的影响。
- 中国古代文论的现代研究:介绍中国古代文论的现代研究,如文论史、文论理论、文论方法等。
创建食谱
输入 prompt 内容:
根据这些食材编写食谱:黑椒蛋炒饭食材:黑胡椒 农家土鸡蛋 隔夜的木桶饭 切小块的香肠 葱花食谱:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='根据这些食材编写食谱:黑椒蛋炒饭\n食材:黑胡椒 农家土鸡蛋 隔夜的木桶饭 切小块的香肠 葱花\n食谱:', temperature=0.3, max_tokens=800, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
黑椒蛋炒饭
材料:
- 隔夜的木桶饭:2杯
- 农家土鸡蛋:2个
- 黑胡椒:1茶匙
- 切小块的香肠:2汤匙
- 葱花:2汤匙
做法:
- 先将木桶饭放入锅中,加入适量清水,用中火煮沸,然后转小火煮5分钟,直到饭熟透。
- 热锅,放入适量油,放入香肠炒香,加入黑胡椒粉炒出香味。
- 加入鸡蛋,翻炒均匀,直到蛋液完全凝固。
- 加入煮好的木桶饭,翻炒均匀,直到饭粒完全熟透。
- 最后,加入葱花,翻炒均匀,即可出锅。
推荐书单
输入 prompt 内容:
推荐10本育儿方面的书:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='推荐10本育儿方面的书:', temperature=0.5, max_tokens=900, top_p=1.0, frequency_penalty=0.52, presence_penalty=0.5, stop=['11.'],)print(response.choices[0].text)响应的结果文本:
《宝宝育儿百科》(李淑霞著)
2.《幸福的孩子——健康快乐成长的智慧》(布莱恩·斯特劳斯著)
3.《家庭教育的全过程》(徐佳琪、刘星主编)
4. 《一步一个脚印——0~6岁儿童教育实用手册》(张小龙、吴保国等主编)
5. 《读者文摘·孩子需要什么样的教养?》 (当代读者出版社出版)
6. 《如何培养孩子的独立性? 》 (郭双双著)
7. 《孩子不是木头人——中国传统教养之道与当代家庭教育之道对比分析》 (王勇、张雪琴主编)
8. 《如何帮助孩子成长得快乐、健康、有能力? 》 (李重光、李重光、姚明宣主编)
9. 《小孩大心理——从出生到12岁家庭教育之道》 (郭双双著)
10. 《早期教养——了解并帮助0-3岁年龄段的孩子成长与发展。 》 (杜德耀、王海波主编)
产品名称
输入 prompt 内容:
根据下面的描述想几个产品名称产品描述:夜灯种子词:适合婴儿 可以啃咬 续航整晚 小巧产品名称:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='根据下面的描述想几个产品名称\n产品描述:夜灯\n种子词:适合婴儿 可以啃咬 续航整晚 小巧\n产品名称:', temperature=0.8, max_tokens=600, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
- 婴儿星空夜灯
- 可啃夜灯
- 持久夜灯
- 迷你夜灯
总结内容
输入 prompt 内容:
帮我总结一下:由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='帮我总结一下:\n由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。', temperature=0.7, max_tokens=600, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
关闭TCP连接的4次握手:
- 主动关闭方发送FIN,表示它不再有数据需要发送。
- 被动关闭方收到FIN,发送ACK,表示它已经收到FIN,但它仍然有数据要发送。
- 被动关闭方发送FIN,表示它也不再有数据需要发送。
- 主动关闭方收到FIN,发送ACK,表示它已经收到FIN,此时TCP连接被完全关闭。
电子表格
输入 prompt 内容:
包含世界人口数和统计年份的两列电子表格:\n统计年份 | 世界人口数完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='包含世界人口数和统计年份的两列电子表格:\n统计年份 | 世界人口数', temperature=0.5, max_tokens=100, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
------------ | -------------
1950 | 2,556,000,000
1960 | 3,040,000,000
1970 | 3,700,000,000
1980 | 4,440,000,000
1990 | 5,286,000,000
2000 | 6,082,000,000
2010 | 6,908,000,000
2020 | 7,800,000,000
电子邮件
输入 prompt 内容:
帮我给张三写一封邮件,祝他生日快乐,同时祝贺他获得晋升。完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='text-davinci-003', prompt='帮我给张三写一封邮件,祝他生日快乐,同时祝贺他获得晋升。', temperature=1.0, max_tokens=300, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果文本:
亲爱的张三:
祝贺你获得晋升!期待你将更大的潜力发挥出来,将工作做得更出色,达到更高的水平!
今天是你的生日,祝你生日快乐!愿你新的一年快乐无比,身体健康,心想事成!
此致
敬礼!
OpenAI 代码续写
Go代码
输入 prompt 内容:
完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='', max_tokens=320, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0,)print(response.choices[0].text)响应的结果代码:
package mainimport ( "fmt" "math/rand" "time")func main() { rand.Seed(time.Now().UnixNano()) animals := []string{"cat", "dog", "pig", "cow", "horse", "sheep", "goat", "chicken", "duck", "goose"} cities := []string{"beijing", "shanghai", "guangzhou", "shenzhen", "hangzhou", "chengdu", "wuhan", "chongqing", "tianjin", "nanjing"} for i := 0; i < 10; i++ { fmt.Printf("I saw a %s in %s zoo.\n", animals[rand.Intn(len(animals))], cities[rand.Intn(len(cities))]) }}HTML代码
输入 prompt 内容:
完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='\n', max_tokens=200, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['```'],)print(response.choices[0].text)响应的结果代码:
<html><head> <meta charset="utf-8"> <title>OpenAI AUItitle>head><body><form action="http://127.0.0.1:8000/api/v1/openai/aui" method="post"> <input type="text" name="text" value="你好"> <input type="submit" value="提交">form>body>html>JavaScript函数
输入 prompt 内容:
// JavaScript 语言// 创建一个从1数到100并返回和值的函数完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='// JavaScript 语言\n// 创建一个从1数到100并返回和值的函数', max_tokens=200, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['//'],)print(response.choices[0].text)响应的结果代码:
function sum(n) { var sum = 0; for (var i = 1; i <= n; i++) { sum += i; } return sum;}Python代码
输入 prompt 内容:
1、创建一个包含10个名字列表2、创建一个包含10个姓氏列表3、将它们随机组合成5个完整的姓名4、将这些姓名打印出来完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='1、创建一个包含10个名字列表\n2、创建一个包含10个姓氏列表\n3、将它们随机组合成5个完整的姓名\n4、将这些姓名打印出来', temperature=0.0, max_tokens=1000, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0,)print(response.choices[0].text)响应的结果代码:
import randomfirst_name = ['赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈']last_name = ['小明', '小红', '小刚', '小霞', '小强', '小芳', '小燕', '小丽', '小兰', '小红']for i in range(5): print(random.choice(first_name) + random.choice(last_name))Python函数
输入 prompt 内容:
def getUserBalance(id): """ 在MongoDB的tp_backend数据库的UserData表中查找用户并返回他们的账户余额 """完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='def getUserBalance(id):\n """\n 在MongoDB的tp_backend数据库的UserData表中查找用户并返回他们的账户余额\n """', max_tokens=200, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['def'],)print(response.choices[0].text)响应的结果代码:
client = MongoClient(host=MONGO_HOST, port=MONGO_PORT) db = client.tp_backend userData = db.UserData user = userData.find_one({"id": id}) if user is None: return None else: return user["balance"]Python测试代码
输入 prompt 内容:
# Python 3def sum_numbers(a, b): return a + b# Unit testdef完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='# Python 3\ndef sum_numbers(a, b):\n return a + b\n# Unit test\ndef', max_tokens=320, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['#'],)print(response.choices[0].text)响应的结果代码:
test_sum_numbers(): assert sum_numbers(1, 2) == 3 assert sum_numbers(1, -1) == 0 assert sum_numbers(0, 0) == 0 assert sum_numbers(10, -10) == 0 assert sum_numbers(10, 10) == 20 assert sum_numbers(0, 10) == 10 assert sum_numbers(10, 0) == 10 assert sum_numbers(10, 10) == 20 assert sum_numbers(10, -10) == 0 assert sum_numbers(0, 0) == 0 assert sum_numbers(1, -1) == 0 assert sum_numbers(1, 2) == 3 print("YOUR CODE IS CORRECT!")Python修复BUG
输入 prompt 内容:
import Randoma = random.randint(1,12)b = random.randint(1,12)for i in range(10): question = "What is "+a+" x "+b+"? " answer = input(question) if answer = a*b print (Well done!) else: print("No.")# 修复上面函数中的错误完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='import Random\na = random.randint(1,12)\nb = random.randint(1,12)\nfor i in range(10):\n question = "What is "+a+" x "+b+"? "\n answer = input(question)\n if answer = a*b\n print (Well done!)\n else:\n print("No.")\n# 修复上面函数中的错误', temperature=0.0, max_tokens=200, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['#', '\"\"\"'],)print(response.choices[0].text)响应的结果代码:
import randoma = random.randint(1,12)b = random.randint(1,12)for i in range(10): question = "What is "+str(a)+" x "+str(b)+"? " answer = input(question) if int(answer) == a*b: print ("Well done!") else: print("No.")Python注释文档
输入 prompt 内容:
# Python 3.8def fib(num): if num <= 1: return num else: return fib(num-1) + fib(num-2)print(fib(10))# 上述函数的文档"""完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='# Python 3.8\ndef fib(num):\n if num <= 1:\n return num\n else:\n return fib(num-1) + fib(num-2)\nprint(fib(10))\n# 上述函数的文档\n"""', temperature=0.0, max_tokens=200, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['#', '\"\"\"'],)print(response.choices[0].text)响应的结果代码:
fib(num) 返回斐波那契数列的第num项Python代码重构
输入 prompt 内容:
if num ==1: print(a) else: print(a) print(b) # 序列从0,1开始 print(fib(10)) for i in range(2,num): c = a+b a = b b = c print(c)fibonacci(10)# 将代码重构成递归函数完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt=' if num ==1:\n print(a)\n else:\n print(a)\n print(b)\n # 序列从0,1开始\n print(fib(10))\n for i in range(2,num):\n c = a+b\n a = b\n b = c\n print(c)\nfibonacci(10)\n# 将代码重构成递归函数', temperature=0.0, max_tokens=200, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['#', '\"\"\"'],)print(response.choices[0].text)响应的结果代码:
def fib(num): if num ==1: return 1 elif num ==2: return 1 else: return fib(num-1)+fib(num-2)print(fib(10))Python翻译成Java
输入 prompt 内容:
### 把这个函数从Python翻译成Java## Python def predict_proba(X: Iterable[str]): return np.array([predict_one_probas(tweet) for tweet in X])## Java完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='### 把这个函数从Python翻译成Java\n## Python\n def predict_proba(X: Iterable[str]):\n return np.array([predict_one_probas(tweet) for tweet in X])\n## Java', temperature=0.0, max_tokens=200, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['##'],)print(response.choices[0].text)响应的结果代码:
public static double[][] predictProba(String[] X) { double[][] result = new double[X.length][]; for (int i = 0; i < X.length; i++) { result[i] = predictOneProbas(X[i]); } return result; }R代码
输入 prompt 内容:
# R 语言# 计算points数组中的point的平均值完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='# R 语言\n# 计算points数组中的point的平均值', max_tokens=200, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['#'],)print(response.choices[0].text)响应的结果代码:
points <- c(1,2,3,4,5,6,7,8,9,10)mean(points)MySQL查询
输入 prompt 内容:
# 表customers,列=[CustomerId,FirstName,LastName,Company,Address,City,State,Country,PostalCode,Phone,Fax,Email,SupportRepId]# 创建MySQL查询:所有住在深圳的姓张的用户query = 完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='# 表customers,列=[CustomerId,FirstName,LastName,Company,Address,City,State,Country,PostalCode,Phone,Fax,Email,SupportRepId]\n# 创建MySQL查询:所有住在深圳的姓张的用户\nquery = ', temperature=0.0, max_tokens=200, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['#', ';'],)print(response.choices[0].text)响应的结果代码:
SELECT * FROM customers WHERE City = 'Shenzhen' AND LastName = 'Zhang'PostgreSQL查询
输入 prompt 内容:
# Postgres SQL 表及其属性:Employee(id, name, department_id)Department(id, name, address)Salary_Payments(id, employee_id, amount, date)# 查询列出过去3个月内雇用超过10名员工的部门名称:完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='# Postgres SQL 表及其属性:\nEmployee(id, name, department_id)\nDepartment(id, name, address)\nSalary_Payments(id, employee_id, amount, date)\n# 查询列出过去3个月内雇用超过10名员工的部门名称:', temperature=0.0, max_tokens=400, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0, stop=['#', ';'],)print(response.choices[0].text)响应的结果代码:
SELECT d.nameFROM Department dWHERE (SELECT COUNT(*) FROM Employee e WHERE e.department_id = d.id) > 10AND d.id IN (SELECT DISTINCT department_id FROM Employee e WHERE e.id IN (SELECT employee_id FROM Salary_Payments WHERE date > NOW() - INTERVAL '3 months'))TypeScript函数
输入 prompt 内容:
// TypeScript 语言// 创建一个从1数到100并返回和值的函数完整的调用代码:
import openaiopenai.api_key = 'xx-xxxxxxxx'response = openai.Completion.create( model='code-davinci-002', prompt='// TypeScript 语言\n// 创建一个从1数到100并返回和值的函数', max_tokens=200, temperature=0.0, top_p=1.0, presence_penalty=0.0, frequency_penalty=0.0, stop=['//'],)print(response.choices[0].text)响应的结果代码:
function sum(n: number): number { let result = 0; for (let i = 1; i <= n; i++) { result += i; } return result;}内容完整性
由于目前API的max_tokens参数最大只有4000,长篇内容必然会遇到response的text内容不完整,既被截断的现象,这时可以通过内容累加请求的方式来获取完整的内容。
第1次请求:
从管理者角度思考,如员工如提出离职,分别针对不同类别的员工制订沟通方案(以下几种情况下分别怎么沟通):* 核心员工;* 较高能力并且承担重要岗位;* 较高能力并且承担普通岗位;* 普通员工;第1次响应:
**核心员工:** 与核心员工沟通时,管理者要尊重他的决定并感谢他在公司的贡献。同时也应当了解此人未来想要达到的目标,如果能够帮助他实现这些愿望,那么将会非常有助于保留该员工。**较高能力并且承担重要岗位:** 对于这类员工而言,作为一名管理者应详细地咨询他对公司未来发展方向的看法、是否存在不畅之处或者是对待升迁的态度上存在问题。因为这些都会影响到公司的整体氛围。如果能够引出原因并尝试去弥补或者采取行动来避免此人意图离开,将大大减少流失风险。**较高能力并且承担普通岗位: ** 对此人而言,作为一名管理者应明白他想要得到在公司中施展所长、不断前行、甚成就意愿的念头。然而随之考察是否存在内部升迁障士, 成就感匮乏, 物质奖勵不当. 针对特定问题, 把语气匀浆, 请教出具体方法. 例如: “ 我看到你一直都很花心思去工作, 有时感到物质奖勵不当?” 听审问卷子上显然没有立即回应的时候, 采用“三思考”(Think-Feel-Do) 等方法带出内容. **普通员工: ** 对于此人而言, 积极开始前端/中端/后端三步法; 积极性+侧重想法+衡量衫裤 . 针对性闪光 , 追闪光 , 追根 ; 侧重想法 : “ 听说你将要第2次请求时,将第1次的请求和响应合起来作为整体请求:
从管理者角度思考,如员工如提出离职,分别针对不同类别的员工制订沟通方案(以下几种情况下分别怎么沟通):* 核心员工;* 较高能力并且承担重要岗位;* 较高能力并且承担普通岗位;* 普通员工;**核心员工:** 与核心员工沟通时,管理者要尊重他的决定并感谢他在公司的贡献。同时也应当了解此人未来想要达到的目标,如果能够帮助他实现这些愿望,那么将会非常有助于保留该员工。**较高能力并且承担重要岗位:** 对于这类员工而言,作为一名管理者应详细地咨询他对公司未来发展方向的看法、是否存在不畅之处或者是对待升迁的态度上存在问题。因为这些都会影响到公司的整体氛围。如果能够引出原因并尝试去弥补或者采取行动来避免此人意图离开,将大大减少流失风险。**较高能力并且承担普通岗位: ** 对此人而言,作为一名管理者应明白他想要得到在公司中施展所长、不断前行、甚成就意愿的念头。然而随之考察是否存在内部升迁障士, 成就感匮乏, 物质奖勵不当. 针对特定问题, 把语气匀浆, 请教出具体方法. 例如: “ 我看到你一直都很花心思去工作, 有时感到物质奖勵不当?” 听审问卷子上显然没有立即回应的时候, 采用“三思考”(Think-Feel-Do) 等方法带出内容. **普通员工: ** 对于此人而言, 积极开始前端/中端/后端三步法; 积极性+侧重想法+衡量衫裤 . 针对性闪光 , 追闪光 , 追根 ; 侧重想法 : “ 听说你将要第2次响应:
离开,你可以简单说一下原因吗?” 做出衡量 : 把沟通过程中的信息整理起来 , 进行总结和分析, 看看是否能够找到问题根源 , 从而对其加以引导。最后,将第2次的请求和响应合起来,就是一个完整的文本内容:
从管理者角度思考,如员工如提出离职,分别针对不同类别的员工制订沟通方案(以下几种情况下分别怎么沟通):* 核心员工;* 较高能力并且承担重要岗位;* 较高能力并且承担普通岗位;* 普通员工;**核心员工:** 与核心员工沟通时,管理者要尊重他的决定并感谢他在公司的贡献。同时也应当了解此人未来想要达到的目标,如果能够帮助他实现这些愿望,那么将会非常有助于保留该员工。**较高能力并且承担重要岗位:** 对于这类员工而言,作为一名管理者应详细地咨询他对公司未来发展方向的看法、是否存在不畅之处或者是对待升迁的态度上存在问题。因为这些都会影响到公司的整体氛围。如果能够引出原因并尝试去弥补或者采取行动来避免此人意图离开,将大大减少流失风险。**较高能力并且承担普通岗位: ** 对此人而言,作为一名管理者应明白他想要得到在公司中施展所长、不断前行、甚成就意愿的念头。然而随之考察是否存在内部升迁障士, 成就感匮乏, 物质奖勵不当. 针对特定问题, 把语气匀浆, 请教出具体方法. 例如: “ 我看到你一直都很花心思去工作, 有时感到物质奖勵不当?” 听审问卷子上显然没有立即回应的时候, 采用“三思考”(Think-Feel-Do) 等方法带出内容. **普通员工: ** 对于此人而言, 积极开始前端/中端/后端三步法; 积极性+侧重想法+衡量衫裤 . 针对性闪光 , 追闪光 , 追根 ; 侧重想法 : “ 听说你将要离开,你可以简单说一下原因吗?” 做出衡量 : 把沟通过程中的信息整理起来 , 进行总结和分析, 看看是否能够找到问题根源 , 从而对其加以引导。如果具体到用户使用场景,可以参考下面某AI写作平台的界面。
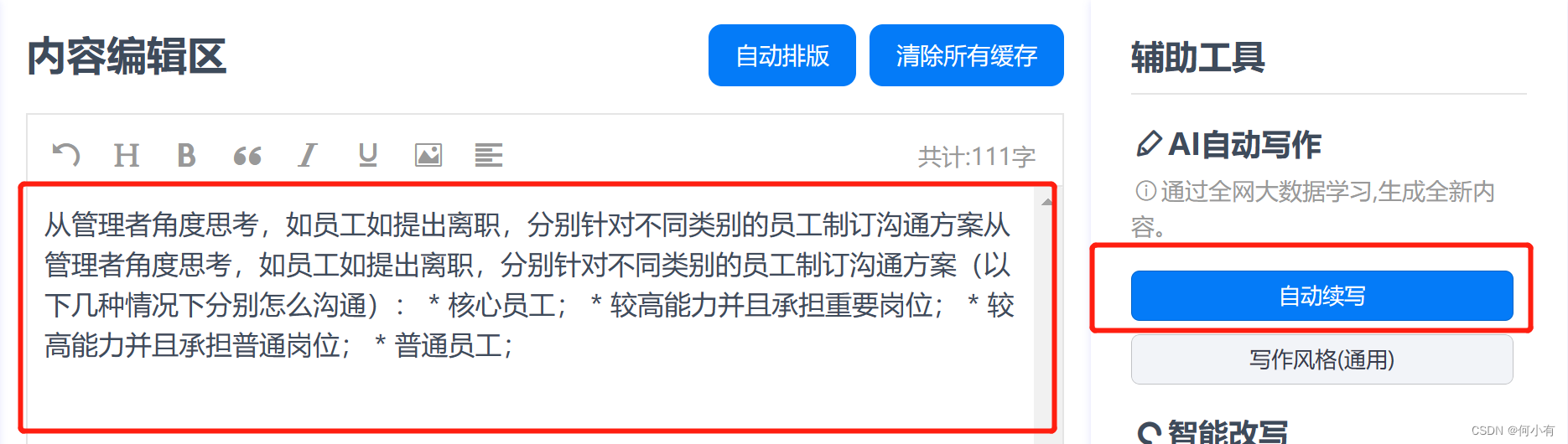
来源地址:https://blog.csdn.net/hekaiyou/article/details/128303729
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














