

【Python】Python读写.xlsx文件(基本操作、空值补全等)

短信预约 -IT技能 免费直播动态提醒
")
【Python】Python读写.xlsx文件(Pandas)
文章目录
1. 介绍
本文介绍如何使用使用 pandas 库来读取xlsx文件中的数据。
- 需要安装openpyxl库才可以读取xlsx文件,使用pip install openpyxl。
- 当然也可以用其他的库,比如openpyxl、xlrd,可以参考:
2. Pandas读写xlsx文件
2.1 基本操作
2.1.1 实现任务
-
读取前n行数据
-
读取指定数据(指定行指定列)
-
获取文件行号和列标题
-
将数据转换为字典形式
-
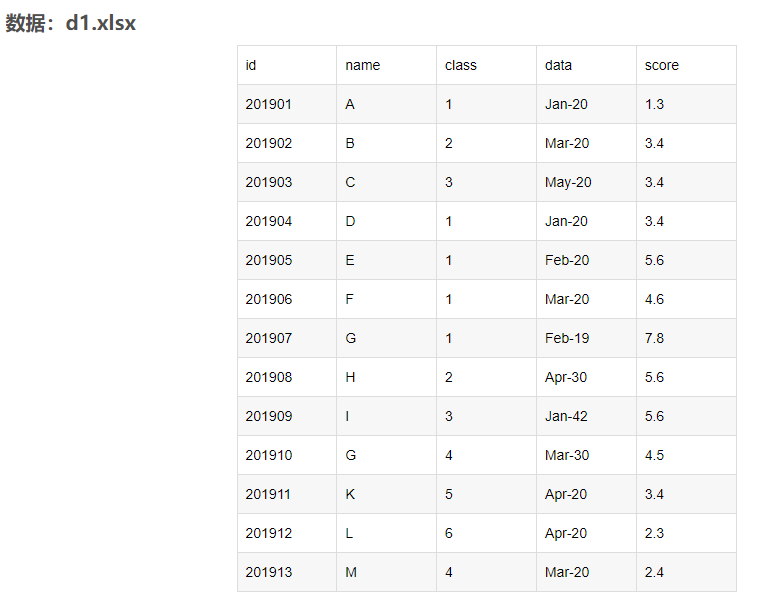
原数据:
![在这里插入图片描述]()
2.1.2 代码
import pandas as pd#1.读取前n行所有数据df1=pd.read_excel('d1.xlsx')#读取xlsx中的第一个sheetdata1=df1.head(10)#读取前10行所有数据data2=df1.values#list【】 相当于一个矩阵,以行为单位#data2=df.values() 报错:TypeError: 'numpy.ndarray' object is not callableprint("获取到所有的值:\n{0}".format(data1))#格式化输出print("获取到所有的值:\n{0}".format(data2)) #2.读取特定行特定列data3=df1.iloc[0].values#读取第一行所有数据data4=df1.iloc[1,1]#读取指定行列位置数据:读取(1,1)位置的数据data5=df1.iloc[[1,2]].values#读取指定多行:读取第一行和第二行所有数据data6=df1.iloc[:,[0]].values#读取指定列的所有行数据:读取第一列所有数据print("数据:\n{0}".format(data3))print("数据:\n{0}".format(data4))print("数据:\n{0}".format(data5))print("数据:\n{0}".format(data6)) #3.获取xlsx文件行号、列号print("输出行号列表{}".format(df1.index.values))#获取所有行的编号:0、1、2、3、4print("输出列标题{}".format(df1.columns.values))#也就是每列的第一个元素 #4.将xlsx数据转换为字典data=[]for i in df1.index.values:#获取行号的索引,并对其遍历 #根据i来获取每一行指定的数据,并用to_dict转成字典 row_data=df1.loc[i,['id','name','class','data','score',]].to_dict() data.append(row_data)print("最终获取到的数据是:{0}".format(data)) #iloc和loc的区别:iloc根据行号来索引,loc根据index来索引。#所以1,2,3应该用iloc,4应该有loc2.1.3 结果
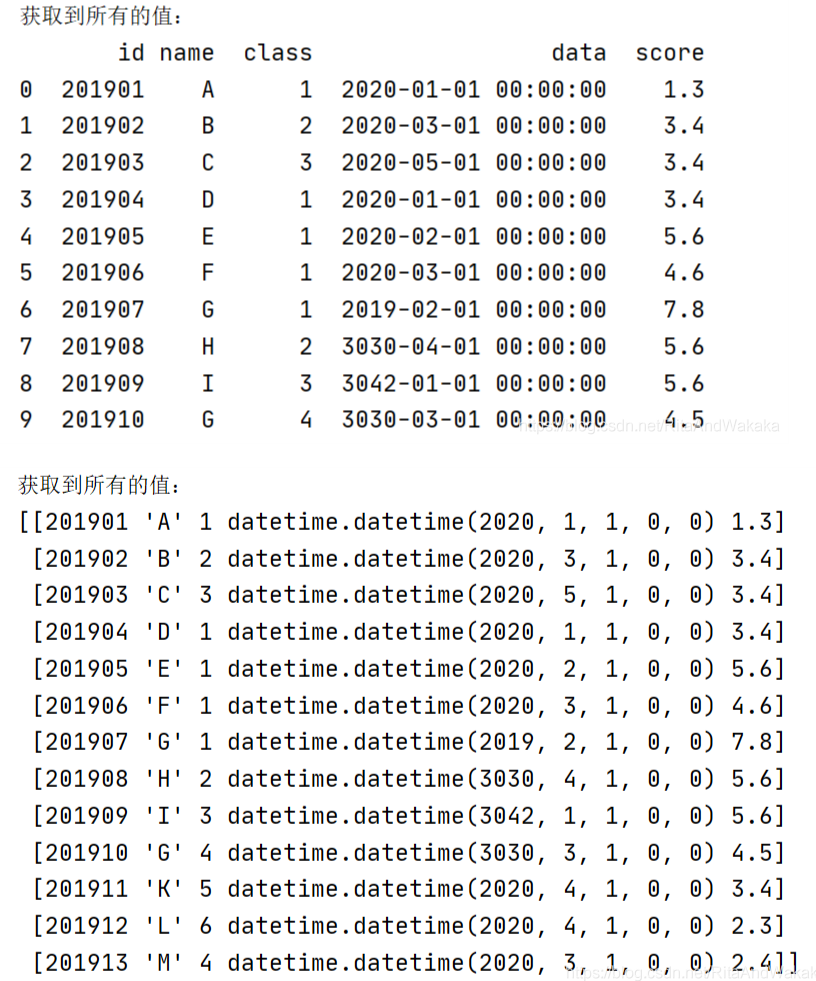

2.2 进阶操作
准备工作(导入包、数据)
#导入必备数据分析库import pandas as pdimport numpy as np#导入excel数据文件df = pd.DataFrame(pd.read_excel("TMao.xlsx")) #导入csv数据文件# df = pd.DataFrame(pd.read_csv("Attributes.csv",header=1,sep=',')) #表示第一行为字段名2.2.1 写操作
df2.to_excel(writer, ‘Sheet’, index=False)
# 任务:输出满足成绩大于等于90的数据writer = pd.ExcelWriter('C:/Users/enuit/Desktop/out_test.xlsx')temp = []for i in range(len(df.index.values)): if df.iloc[i, 3] >= 90: temp.append(df.iloc[i].values)df2 = pd.DataFrame(data=temp, columns=df.columns.values)# 不写index会输出索引df2.to_excel(writer, 'Sheet', index=False)writer.save()2.2.2 查看数据表的基本信息
根据需要对数据进行总体上的查看,建议不要全部执行,而是一条一条依次执行查看效果。
#维度查看:返回几行几列,注意不要加()df.shape#查看列名称:类似于SQL中的descdf.columns#数据表基本信息(维度、列名称、数据格式、所占空间等)df.info#查看每一列数据的格式df.dtypes#某一列数据的格式df['订单付款时间'].dtypedf['订单金额'].dtype2.2.2 空值的与缺失值(NAN、NAT)
- 空值:在pandas中的空值是"",也叫空字符串;
- 缺失值:在dataframe中为NAN或者NAT(缺失时间),在series中为none或者nan
1)查看所有值是否为空值
- (所有值全部列出来,不实用的操作,这里简单介绍一下用法)
#查看是否为空值df.isnull()#某一列的空值df["订单付款时间"].isnull()2)判断是否存在空值
# 查看所有值中是否存在空值df.isnull().any()# 判断某列是否存在空值df["订单付款时间"].isnull().any() #或者.values# 打印空值行的数据if df["订单付款时间"].isnull().any(): print(df[df.isnull().values==True]) print(df[df.isna().values==True])3)唯一值查看
#查看某一列的唯一值df["订单金额"].unique()#查看数据表的值df.values#查看前几行/后几行的数据df.head() #默认前5行df.tail(10) #指定数值10,查看后10行的数据2.2.3 数据清洗
1)空值的处理
- (1)删除含有空值的行或列:用dropna()时可以同时剔除Nan和NaT
- axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
- how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
- thresh:一行或一列中至少出现了thresh个才删除。
- subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
- inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
# 准备工作df.isnull().any() #查看哪一列有空值,发现是<订单付款时间>列print(df[df['订单付款时间'].isna().values==True]) #输出<订单付款时间>列存在空值的行#清洗空值df2 = df.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False) #删除含有空值的行或列 df2['订单付款时间'].isna().any() #查看是否还存在空值#再次查看df2.shape- (2)若发现dropna()后仍然存在空值,则有可能其中并不是空值,而是空字符串,这里就可以将空字符串替换成空值再进行dropna()操作
df.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)df['订单付款时间'].dropna()- (3)填充含有空值的行或列(ffill / bfill)
- value:需要用什么值去填充缺失值
- axis:确定填充维度,从行开始或是从列开始
- method:ffill:用缺失值前面的一个值代替缺失值,如果axis=1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现
- limit:确定填充的个数,如果limit=2,则只填充两个缺失值。
df.isna().any() #查看原数据表是否存在空值df3 = df.fillna(method='ffill',axis=0,inplace=False,limit=None,downcast=None)df3.isna().any() #查看填充后的数据表是否存在空值#用均值填充空值(mean方法)df['订单金额'].fillna(df[订单金额].mean())2)格式转换
- (1)清除空格字符strip:调用map函数对str对象进行空格去除,若去除逗号可以用map(str.strip(‘,’))
df['收货地址']=df['收货地址'].map(str.strip()) - (2)大小写转换lower/upper
df['编码']=df['编码'].strip().lower() #大写同理,upper()- (3)更改数据格式astype
df['订单金额'].astype('int') #int整数类型,同理float浮点型3)更改列名即字段名
df.rename(columns={'实付金额':'实付'}) #把实付金额,改成 实付4)保留一个重复值
df['收货地址'].drop_duplicates() #删除列中后出现的值df['收货地址'].drop_duplicates(keep='last') #删除列中先出现的值,即保留最后一个值5)数据替换
把收货地址中的 四川 改为 四川省
df['收货地址'].replace('四川', '四川省') 3. 参考
【1】https://blog.csdn.net/RitaAndWakaka/article/details/108366203
【2】https://blog.csdn.net/Viewinfinitely/article/details/124728721
来源地址:https://blog.csdn.net/qq_51392112/article/details/130116437
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












