

机器学习中怎么评估分类效果


这篇文章将为大家详细讲解有关机器学习中怎么评估分类效果,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
给你一个问题,假如老板让另一个同事去检查一万张纸币中,有多少是真币,有多少是假币,然后这个同事给老板汇报了结果:这一万张纸币中,有2千张是真币,有8千张是假币。现在,老板让你来评估这个同事的汇报结果,你会怎么做?
你重新把一万张纸币再用机器过一遍再做对比,或者把这个同事的2千张真币与8千张假币再过一遍,这都是可以的。但是,假如不允许你这样做呢,比如一万张纸币变成了1百万张,不可能给你时间再全部来一遍,那你怎么做?
抽查啊。
似乎就这一招,那么要怎么抽查才能合理地评估同事汇报的结果呢?
一般的做法是这样的,先在2千张真币上抽查:“你说这些都是真币,哪到底有多少是真的呢?” 这个比例,在数据分析中,叫Precision,精度或精准度。如果100%是真的,那当然是最好的。但即使精准度是100%,也不能说明这个汇报结果就ok了,因为,另外8千张“假币”中也有可能全是真币啊。
所以,还要在8千张假币中抽查:“你说都是假的,哪到底有多少是假的呢?” 这个比例,也能说明问题,假如抽了一百张,结果有90张都是真币(只有10%真是假币),那说这8千张都是假币就显得很不可信。这个比例,小程觉得它也叫作精准度,就是“你说的假中,到底有多少是假”,值越大越好。
那除了精准度,是不是就够了呢?
看起来是够了,因为,精准度反应了“判是非”的能力。以上面的例子来说,比如判断为真币的精度是98%,那就意味着只有2%的假币被误判为真币了,所以我把假币判断为真币的可能性是很低的(假设2%在业界是很低的:-)。再比如,假设判断为假币的精度是95%,那就意味着只有5%的真币给误判成假币了。在这种情况下,把假的判断成真的,或把真的判断成假的,比例都很低。这不就完了吗?这说明“判是非”的能力很强啊,这个预测系统是可信的啊,它不会把真假误判啊,你给它一堆纸币,它就能给你分辨真假,不会出错啊。
但是,这里有一个前提,这个系统要在判断后,你才知道是不是判断对了。如果这个系统对所有纸币都不判断,或者者1万张纸币中只判断了1千张,那你还指望它做什么?它是很准啊,但是,它只有判断出来的才很准,还有很多是没有判断出来的!但话说回来,其实只要很准(精度高),就有使用市场的,这个后面再说。
所以,这里还有一个指标,叫Sensitivity灵敏度,也叫Recall召回率。
召回率,反映了“找回”的能力,比如我给系统1千张真币,它能找出800张真币,那80%就是召回率。如果它的召回率是10%,那说明只找回了100张,还有900张是怎么回事?这时,有两个可能,一是判断不出来,比如这900张我就是判断不出来,所以就找不回来,另一个可能,就是误判了,比如900张我都误判为假币了。但是,误判说明什么?误判说明精度差啊,所以如果精度很高,那就只有一种可能,就是判断不出来。
所以,精度跟召回率都要看,精度反应了靠不靠谱(说什么是什么),召回率反应了能不能找到数据(覆盖了多少样本)。
不管是精度还是召回率,都只是一个数字,而为了得到这个数字,一般都是经过很多样本的预测考验才得出来的,所以把这些样本都反应出来就显得很必要了,这表明,我的“率”是有由来的。这时候,“混淆矩阵”就出场了。
混淆矩阵,也叫差错矩阵,名字都是从鬼文翻译过来的(由此可见,含义才是最重要的,鬼知道翻译到的是什么)。混淆矩阵是一张表格,一边是真实值,一边是预测值,横竖怎么摆都行,看下面这个图就明白了:
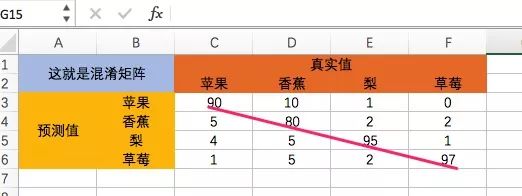
“混淆”表明了分类的能力,以上图为例,苹果的召回率(在一堆苹果中能捞回多少苹果的能力)是:90/(90+5+4+1)=90%,而香蕉、梨与草莓的召回率分别为80%、95%、97%。小程每个分类刚好用了100个真实值,为了方便心算能力不好的你。由此可见,右对角线上的值就是召回值,也就是判断准确的值。
再看精度,这里行表示了精度,比如苹果的精度是:90/(90+10+1+0)=89%,香蕉的精度是:80/(5+80+2+2)=89.9%,梨跟草莓分别是90.4%、92.4%。
然后,召回率跟精度一起来看,
苹果、 香蕉、 梨、 草莓
90% 80% 95% 97%
89% 89.9% 90.4% 92.4%
草莓的召回率跟精度都是最高的,让我们恭喜它!
除了召回率跟精度,对于分类器(上面预测苹果香蕉就是分类器)效果评估,还有两个指标,一个叫总的准确率,就是拿判断准确的值(右对角线上的值)相加,再除以总的样本数量,这里就是(90+80+95+97)/400=90.5%,另一个叫特异度,比如对于苹果,就是真的不是苹果的样本中,判断不是苹果的比例。但小程觉得这两个指标的参考意义不大。
从一张样本表,抽象出每个分类的召回率跟精度,如果再把抽象一下,就是每个分类的F1Score,它是召回率跟精度的整合:F1Score=2*精度*召回/(精度+召回),上面的例子,苹果的F1Score=2*90%*89%/(90%+89%)=89.49%。
基本上,也就是用精度、召回率来描述分类器的质量了,最多再加个F1Score。
让我们再深入一点,问你一个问题,精度高可以用于什么场景?召回率高又可以用于什么场景?
精度高,就是不出错啰,说是什么就是什么,那可以用于分类,比如给一批样本过来,样本里面有ABCD几个分类,精度高的情况下,就可以指出哪些样本是A,哪些样本是B,等等。如果精度高,但召回率低,一样可以用于分类,只是,有很多A类的样本没有找出来(谁让你判断不出来),其它分类也一样。
召回率高,但精度低,那就是分类是不靠谱的,说是A结果可能是B,那就不要分类了,这时,因为召回率高,那可以用于筛选已有的分类,比如说有一批样本基本是A类,只是里面可能有一些B跟C,那就可以用这个分类器来筛选了,相当于纠错,因为召回率高,所以基本把A给找回来,其它的扔掉。
召回率高,精度也高,也既可用于分类,也可用于已有分类(真的分好了的)的筛选。
那如果召回率低,精度也低呢?那就是废的,用人工好了!
关于“机器学习中怎么评估分类效果”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














