

Kubernetes中Nginx服务启动失败如何排查


这篇文章主要介绍“Kubernetes中Nginx服务启动失败如何排查”,在日常操作中,相信很多人在Kubernetes中Nginx服务启动失败如何排查问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Kubernetes中Nginx服务启动失败如何排查”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
❌pod节点启动失败,nginx服务无法正常访问,服务状态显示为ImagePullBackOff。
[root@m1 ~]# kubectl get podsNAME READY STATUS RESTARTS AGEnginx-f89759699-cgjgp 0/1 ImagePullBackOff 0 103m查看nginx服务的Pod节点详细信息。
[root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgpName: nginx-f89759699-cgjgpNamespace: defaultPriority: 0Service Account: defaultNode: n1/192.168.200.84Start Time: Fri, 10 Mar 2023 08:40:33 +0800Labels: app=nginx pod-template-hash=f89759699Annotations: <none>Status: PendingIP: 10.244.3.20IPs: IP: 10.244.3.20Controlled By: ReplicaSet/nginx-f89759699Containers: nginx: Container ID: Image: nginx Image ID: Port: <none> Host Port: <none> State: Waiting Reason: ImagePullBackOff Ready: False Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-zk8sj (ro)Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: default-token-zk8sj: Type: Secret (a volume populated by a Secret) SecretName: default-token-zk8sj Optional: falseQoS Class: BestEffortNode-Selectors: <none>Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300sEvents: Type Reason Age From Message ---- ------ ---- ---- ------- Normal BackOff 57m (x179 over 100m) kubelet Back-off pulling image "nginx" Normal Pulling 7m33s (x22 over 100m) kubelet Pulling image "nginx" Warning Failed 2m30s (x417 over 100m) kubelet Error: ImagePullBackOff发现,获取nginx镜像失败。可能是由于Docker服务引起的。
于是,检查Docker是否正常启动
systemctl status docker发现,docker服务启动失败????,手动尝试重新启动。
systemctl restart docker但是,重启docker服务失败,出现如下报错信息。
[root@m1 ~]# systemctl restart dockerJob for docker.service failed because the control process exited with error code.See "systemctl status docker.service" and "journalctl -xe" for details.执行systemctl restart docker命令失效。
接着,当执行docker version命令时,发现未能连接到Docker daemon
[root@m1 ~]# docker versionClient: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:03:11 2022 OS/Arch: linux/amd64 Context: default Experimental: trueCannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?于是,再次通过执行systemctl status docker命令,查看docker服务未能启动,阅读输出报错信息,如下所示。
[root@m1 ~]# systemctl status docker● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: failed (Result: exit-code) since Fri 2023-03-10 10:28:16 CST; 4min 35s ago Docs: https://docs.docker.com Main PID: 2221 (code=exited, status=1/FAILURE)Mar 10 10:28:13 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILUREMar 10 10:28:13 m1 systemd[1]: docker.service: Failed with result 'exit-code'.Mar 10 10:28:13 m1 systemd[1]: Failed to start Docker Application Container Engine.Mar 10 10:28:16 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart.Mar 10 10:28:16 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.Mar 10 10:28:16 m1 systemd[1]: Stopped Docker Application Container Engine.Mar 10 10:28:16 m1 systemd[1]: docker.service: Start request repeated too quickly.Mar 10 10:28:16 m1 systemd[1]: docker.service: Failed with result 'exit-code'.Mar 10 10:28:16 m1 systemd[1]: Failed to start Docker Application Container Engine.[root@m1 ~]#通过上述输出显示,Docker 服务进程的启动失败,状态为 1/FAILURE。
✅接下来,尝试通过以下步骤来排查和解决问题:
1️⃣查看 Docker 服务日志:使用以下命令查看 Docker 服务日志,以便更详细地了解失败原因。
sudo journalctl -u docker.service
2️⃣ 通过输出Ddocker日志分析,提取到了相关报错信息片段,发现是配置daemon中的/etc/docker/daemon.json配置文件出错导致的。
Mar 10 10:20:17 m1 systemd[1]: Starting Docker Application Container Engine...Mar 10 10:20:17 m1 dockerd[1572]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character '"' after object key:value pairMar 10 10:20:17 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILUREMar 10 10:20:17 m1 systemd[1]: docker.service: Failed with result 'exit-code'.Mar 10 10:20:17 m1 systemd[1]: Failed to start Docker Application Container Engine.Mar 10 10:20:19 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart.Mar 10 10:20:19 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 2.Mar 10 10:20:19 m1 systemd[1]: Stopped Docker Application Container Engine.3️⃣此时,查看daemon配置文件/etc/docker/daemon.json是否配置正确。
[root@m1 ~]# cat /etc/docker/daemon.json{ # 设置 Docker 镜像的注册表镜像源为阿里云镜像源。 "registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"] # 指定 Docker 守护进程使用 systemd 作为 cgroup driver。 "exec-opts": ["native.cgroupdriver=systemd"]}咋一看,配置信息没有什么问题,都是正确的,但仔细一看,就会发现应该在"registry-mirrors"选项的结尾添加逗号。犯了缺少逗号(,)导致的语法错误,终于找到了问题根源。
修改后:
[root@m1 ~]# cat /etc/docker/daemon.json{ "registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"]}[root@m1 ~]# cat /etc/docker/daemon.json{ "registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"]}按下:wq报错退出。
4️⃣ 重新加载系统并重新启动Docker服务
systemctl daemon-reloadsystemctl restart dockersystemctl status docker5️⃣检查docker版本信息是否输出正常
[root@m1 ~]# docket version-bash: docket: command not found[root@m1 ~]# docker versionClient: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:03:11 2022 OS/Arch: linux/amd64 Context: default Experimental: trueServer: Docker Engine - Community Engine: Version: 20.10.17 API version: 1.41 (minimum version 1.12) Go version: go1.17.11 Git commit: a89b842 Built: Mon Jun 6 23:01:29 2022 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.6.6 GitCommit: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 runc: Version: 1.1.2 GitCommit: v1.1.2-0-ga916309 docker-init: Version: 0.19.0 GitCommit: de40ad0[root@m1 ~]# docker infoClient: Context: default Debug Mode: false Plugins: app: Docker App (Docker Inc., v0.9.1-beta3) buildx: Docker Buildx (Docker Inc., v0.8.2-docker) scan: Docker Scan (Docker Inc., v0.17.0)Server: Containers: 20 Running: 8 Paused: 0 Stopped: 12 Images: 20 Server Version: 20.10.17 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Native Overlay Diff: true userxattr: false Logging Driver: json-file Cgroup Driver: systemd Cgroup Version: 1 Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog Swarm: inactive Runtimes: io.containerd.runc.v2 io.containerd.runtime.v1.linux runc Default Runtime: runc Init Binary: docker-init containerd version: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 runc version: v1.1.2-0-ga916309 init version: de40ad0 Security Options: seccomp Profile: default Kernel Version: 4.18.0-372.9.1.el8.x86_64 Operating System: Rocky Linux 8.6 (Green Obsidian) OSType: linux Architecture: x86_64 CPUs: 2 Total Memory: 9.711GiB Name: m1 ID: 4YIS:FHSB:YXRI:CED5:PJSJ:EAS2:BCR3:GJJF:FDPK:EDJH:DVKU:AIYJ Docker Root Dir: /var/lib/docker Debug Mode: false Registry: https://index.docker.io/v1/ Labels: Experimental: false Insecure Registries: 127.0.0.0/8 Registry Mirrors: https://w2kavmmf.mirror.aliyuncs.com/ Live Restore Enabled: false至此,Docker服务重启成功,pod节点恢复正常,Nginx服务能够正常访问。
[root@m1 ~]# kubectl get podsNAME READY STATUS RESTARTS AGEnginx-f89759699-cgjgp 1/1 Running 0 174m查看pod详细信息,显示正常。
[root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgpName: nginx-f89759699-cgjgpNamespace: defaultPriority: 0Service Account: defaultNode: n1/192.168.200.84Start Time: Fri, 10 Mar 2023 08:40:33 +0800Labels: app=nginx pod-template-hash=f89759699Annotations: <none>Status: RunningIP: 10.244.3.20IPs: IP: 10.244.3.20Controlled By: ReplicaSet/nginx-f89759699Containers: nginx: Container ID: docker://88bdc2bfa592f60bf99bac2125b0adae005118ae8f2f271225245f20b7cfb3c8 Image: nginx Image ID: docker-pullable://nginx@sha256:aa0afebbb3cfa473099a62c4b32e9b3fb73ed23f2a75a65ce1d4b4f55a5c2ef2 Port: <none> Host Port: <none> State: Running Started: Fri, 10 Mar 2023 10:37:42 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-zk8sj (ro)Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-zk8sj: Type: Secret (a volume populated by a Secret) SecretName: default-token-zk8sj Optional: falseQoS Class: BestEffortNode-Selectors: <none>Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300sEvents: Type Reason Age From Message ---- ------ ---- ---- ------- Normal BackOff 58m (x480 over 171m) kubelet Back-off pulling image "nginx"[root@m1 ~]#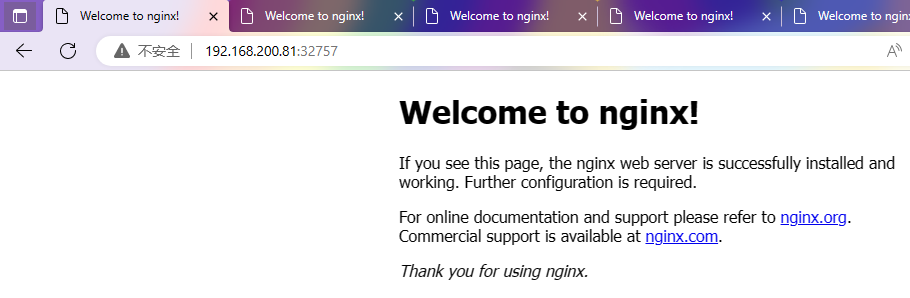
到此,关于“Kubernetes中Nginx服务启动失败如何排查”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341

















