

Kubernetes安装报错怎么解决

本篇内容主要讲解“Kubernetes安装报错怎么解决”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Kubernetes安装报错怎么解决”吧!
kubeadm init初使化报错
[root@k8s01 ~]# kubeadm init --kubernetes-version=v1.13.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=Swap
[init] Using Kubernetes version: v1.13.3
[preflight] Running pre-flight checks
[WARNING Swap]: running with swap on is not supported. Please disable swap
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.2. Latest validated version: 18.06
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.13.3: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-controller-manager:v1.13.3: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
解决方法:
[root@k8s01 ~]# cat 12.sh
#!/bin/bash
docker pull mirrorgooglecontainers/kube-apiserver:v1.13.3
docker pull mirrorgooglecontainers/kube-controller-manager:v1.13.3
docker pull mirrorgooglecontainers/kube-scheduler:v1.13.3
docker pull mirrorgooglecontainers/kube-proxy:v1.13.3
docker pull mirrorgooglecontainers/pause:3.1
docker pull mirrorgooglecontainers/etcd:3.2.24
docker pull coredns/coredns:1.2.6
docker tag mirrorgooglecontainers/kube-proxy:v1.13.3 k8s.gcr.io/kube-proxy:v1.13.3
docker tag mirrorgooglecontainers/kube-scheduler:v1.13.3 k8s.gcr.io/kube-scheduler:v1.13.3
docker tag mirrorgooglecontainers/kube-apiserver:v1.13.3 k8s.gcr.io/kube-apiserver:v1.13.3
docker tag mirrorgooglecontainers/kube-controller-manager:v1.13.3 k8s.gcr.io/kube-controller-manager:v1.13.3
docker tag mirrorgooglecontainers/etcd:3.2.24 k8s.gcr.io/etcd:3.2.24
docker tag coredns/coredns:1.2.6 k8s.gcr.io/coredns:1.2.6
docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
docker rmi mirrorgooglecontainers/kube-apiserver:v1.13.3
docker rmi mirrorgooglecontainers/kube-controller-manager:v1.13.3
docker rmi mirrorgooglecontainers/kube-scheduler:v1.13.3
docker rmi mirrorgooglecontainers/kube-proxy:v1.13.3
docker rmi mirrorgooglecontainers/pause:3.1
docker rmi mirrorgooglecontainers/etcd:3.2.24
docker rmi coredns/coredns:1.2.6:q
[root@k8s01 ~]# ./12.sh
关闭swap交换分区
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
解决方法:
[root@k8s1 ~]# echo "KUBELET_EXTRA_ARGS=--fail-swap-> /etc/sysconfig/kubelet
[root@k8s1 ~]# vim /etc/fstab
#UUID=c5f6d686-6b5a-48ae-92c0-df2f44b6402b swap swap defaults 0 0 --注释swap
[root@k8s1 ~]#
k8s从节点pod不能显示
[root@k8s2 ~]# kubectl get pods
The connection to the server localhost:8080 was refused - did you specify the right host or port?
[root@k8s2 ~]#
解决方法:
[root@k8s1 ~]# scp -r /etc/kubernetes/admin.conf root@k8s2:/etc/kubernetes/ --将admin.conf文件拷贝到其它从节点
[root@k8s2 ~]# vim /root/.bash_profile --在各个从节点添加环境变量
export KUBECONFIG=/etc/kubernetes/admin.conf
[root@k8s2 ~]# source /root/.bash_profile
使用Harbor上传镜像报错
[root@node1 ~]# docker login http://192.168.8.10
Username: admin
Password:
Error response from daemon: Get https://192.168.8.10/v2/: dial tcp 192.168.8.10:443: connect: connection refused
解决方法:
[root@node1 harbor]# vim /usr/lib/systemd/system/docker.service --修改参数
ExecStart=/usr/bin/dockerd -H fd:// --insecure-registry=192.168.8.10
[root@node1 harbor]# systemctl daemon-reload
[root@node1 harbor]# systemctl restart docker
[root@node1 harbor]# ps -ef | grep -i docker
root 808561 1884 0 16:08 ? 00:00:00 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/5f13be571995f00b5ec00b8941f612bbf0b5429ae183ab0553e579d31c43f300 -address /run/containerd/containerd.sock -containerd-binary /usr/bin/containerd -runtime-root /var/run/docker/runtime-runc
root 874547 1 6 16:50 ? 00:00:00 /usr/bin/dockerd -H fd:// --insecure-registry=192.168.8.10
[root@node1 harbor]# docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------------------------------------
harbor-adminserver /harbor/start.sh Up
harbor-core /harbor/start.sh Up
harbor-db /entrypoint.sh postgres Up 5432/tcp
harbor-jobservice /harbor/start.sh Up
harbor-log /bin/sh -c /usr/local/bin/ ... Up 127.0.0.1:1514->10514/tcp
harbor-portal nginx -g daemon off; Up 80/tcp
nginx nginx -g daemon off; Up 0.0.0.0:443->443/tcp, 0.0.0.0:4443->4443/tcp, 0.0.0.0:80->80/tcp
redis docker-entrypoint.sh redis ... Up 6379/tcp
registry /entrypoint.sh /etc/regist ... Up 5000/tcp
registryctl /harbor/start.sh Up
[root@node1 harbor]# docker login 192.168.8.10
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@node1 harbor]#
在kubernetes添加节点后提示CNI问题
[root@k8s1 ~]# kubectl describe pods ecs-web-desktop-7cbc98dcdb-nw4fw -n ecs-local-area
Normal SuccessfulMountVolume 8h kubelet, ecsnode03 MountVolume.SetUp succeeded for volume "volume-data"
Normal SuccessfulMountVolume 8h kubelet, ecsnode03 MountVolume.SetUp succeeded for volume "setenv-sh"
Normal SuccessfulMountVolume 8h kubelet, ecsnode03 MountVolume.SetUp succeeded for volume "default-token-69l45"
Warning FailedCreatePodSandBox 8h (x11 over 8h) kubelet, ecsnode03 Failed create pod sandbox: rpc error: code = Unknown desc = NetworkPlugin cni failed to set up pod "ecs-web-desktop-7cbc98dcdb-nw4fw_ecs-local-area" network: could not initialize etcdv3 client: open /etc/cni/etcd/pki/calico-etcd-client.crt: no such file or directory
Normal SandboxChanged 8h (x123 over 8h) kubelet, ecsnode03 Pod sandbox changed, it will be killed and re-created.
Normal Scheduled 7m default-scheduler Successfully assigned ecs-web-desktop-7cbc98dcdb-nw4fw to ecsnode03
解决方法:
是因为master节点etcd没有新节点数据信息,过5分钟就可以了。
安装kubenetes到成功后CoreDNS频繁重启(原因是Iptables规则乱了)
[root@k8s01 yum.repos.d]# kubectl get pods -n kube-system | grep coredns
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-8vc5h 0/1 CrashLoopBackOff 3 7m42s
coredns-5c98db65d4-vq9j5 0/1 CrashLoopBackOff 3 7m42s
[root@k8s01 yum.repos.d]# kubectl logs pods coredns-5c98db65d4-8vc5h -n kube-system
Error from server (NotFound): pods "pods" not found
[root@k8s01 yum.repos.d]# kubectl logs coredns-5c98db65d4-8vc5h -n kube-system
E0907 06:44:40.045232 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:317: Failed to list *v1.Endpoints: Get https://10.96.0.1:443/api/v1/endpoints?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
E0907 06:44:40.045232 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:317: Failed to list *v1.Endpoints: Get https://10.96.0.1:443/api/v1/endpoints?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
log: exiting because of error: log: cannot create log: open /tmp/coredns.coredns-5c98db65d4-8vc5h.unknownuser.log.ERROR.20190907-064440.1: no such file or directory
[root@k8s01 yum.repos.d]#
解决方法:
[root@k8s01 yum.repos.d]# iptables -F
[root@k8s01 yum.repos.d]# iptables -Z
[root@k8s01 yum.repos.d]# systemctl restart kubelet
[root@k8s01 yum.repos.d]# systemctl restart docker
[root@k8s01 yum.repos.d]# kubectl get pods -n kube-system | grep coredns
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-8vc5h 1/1 Running 7 12m
coredns-5c98db65d4-vq9j5 1/1 Running 8 12m
[root@k8s01 yum.repos.d]#
集群coredns组件挂起状态(flannel组件未初使化,需要重新安装)
[root@k8s01 ~]# kubectl get pods -n kube-system | grep -i coredns
coredns-5644d7b6d9-8wvgt 0/1 ContainerCreating 0 79m
coredns-5644d7b6d9-pzr7g 0/1 ContainerCreating 0 79m
[root@k8s01 ~]# journalctl -u kubelet -f
Oct 19 14:46:20 k8s01 kubelet[653]: E1019 14:46:20.701679 653 pod_workers.go:191] Error syncing pod e641b551-7f22-40fa-b847-658f6c7696fa ("tiller-deploy-8557598fbc-6jfp7_kube-system(e641b551-7f22-40fa-b847-658f6c7696fa)"), skipping: network is not ready: runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Oct 19 14:46:20 k8s01 kubelet[653]: E1019 14:46:20.702091 653 pod_workers.go:191] Error syncing pod bd45bbe0-8529-4ee4-9fcf-90528178dc0d ("coredns-5c98db65d4-rtktb_kube-system(bd45bbe0-8529-4ee4-9fcf-90528178dc0d)"), skipping: network is not ready: runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Oct 19 14:46:20 k8s01 kubelet[653]: E1019 14:46:20.702396 653 pod_workers.go:191] Error syncing pod 87d24c8c-bba8-420b-8901-9e2b8bc339ac ("coredns-5644d7b6d9-8wvgt_kube-system(87d24c8c-bba8-420b-8901-9e2b8bc339ac)"), skipping: network is not ready: runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
解决方法:
[root@k8s01 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[root@k8s01 ~]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged configured
clusterrole.rbac.authorization.k8s.io/flannel unchanged
clusterrolebinding.rbac.authorization.k8s.io/flannel unchanged
serviceaccount/flannel unchanged
configmap/kube-flannel-cfg configured
daemonset.apps/kube-flannel-ds-amd64 configured
daemonset.apps/kube-flannel-ds-arm64 configured
daemonset.apps/kube-flannel-ds-arm configured
daemonset.apps/kube-flannel-ds-ppc64le configured
daemonset.apps/kube-flannel-ds-s390x configured
[root@k8s01 ~]# kubectl get pods -n kube-system | grep -i coredns
coredns-5644d7b6d9-8wvgt 1/1 Running 0 92m
coredns-5644d7b6d9-pzr7g 1/1 Running 0 92m
[root@k8s01 ~]#
在k8s集群中apiserver占用很高的CPU资源,导致频繁重启。
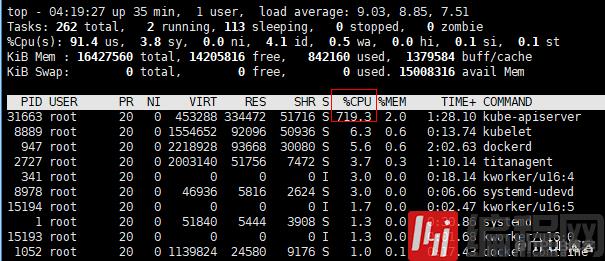
[root@ecsmaster01 ~]# kubectl get nodes
The connection to the server 172.31.129.93:6443 was refused - did you specify the right host or port?
[root@ecsmaster01 ~]#
解决方法:
(1).服务器时间不对
[root@ecsmaster01 ~]# date
Fri Oct 25 05:04:24 CST 2019
[root@ecsmaster01 ~]# ntpdate time1.aliyun.com
25 Oct 13:04:46 ntpdate[5017]: step time server 203.107.6.88 offset 28800.550337 sec
[root@ecsmaster01 ~]# date
Fri Oct 25 13:04:54 CST 2019
[root@ecsmaster01 ~]#
(2).查看系统日志(从日志查看出与etcd pod有关)
[root@ecsmaster01 ~]# tail -200f /var/log/messages
Oct 25 05:04:43 localhost kernel: XFS (dm-5): Unmounting Filesystem
Oct 25 05:04:43 localhost dockerd: time="2019-10-25T05:04:43.961739020+08:00" level=error msg="Handler for POST /v1.24/containers/c2d922d8a203383725b819e497272b25b8e8db315d03a75540b6fbfb3a3ed565/stop returned error: Container c2d922d8a203383725b819e497272b25b8e8db315d03a75540b6fbfb3a3ed565 is already stopped"
Oct 25 05:04:44 localhost kernel: XFS (dm-2): Unmounting Filesystem
Oct 25 05:04:44 localhost dockerd: time="2019-10-25T05:04:44.187195506+08:00" level=error msg="Handler for POST /v1.24/containers/create returned error: Conflict. The name \"/k8s_POD_etcd-ecsmaster01_kube-system_fb87a1f1730f1fe65cd7ce2b1d5a84b8_3\" is already in use by container a468c762916792739e99fc48a85c4a24ce848e09c430be1da99a44576266e548. You have to remove (or rename) that container to be able to reuse that name."
Oct 25 05:04:44 localhost kubelet: W1025 05:04:44.187756 8889 helpers.go:284] Unable to create pod sandbox due to conflict. Attempting to remove sandbox "a468c762916792739e99fc48a85c4a24ce848e09c430be1da99a44576266e548"
Oct 25 05:04:44 localhost systemd-udevd: inotify_add_watch(7, /dev/dm-2, 10) failed: No such file or directory
Oct 25 05:04:44 localhost kubelet: E1025 05:04:44.481171 8889 remote_runtime.go:92] RunPodSandbox from runtime service failed: rpc error: code = Unknown desc = failed to create a sandbox for pod "etcd-ecsmaster01": Error response from daemon: Conflict. The name "/k8s_POD_etcd-ecsmaster01_kube-system_fb87a1f1730f1fe65cd7ce2b1d5a84b8_3" is already in use by container a468c762916792739e99fc48a85c4a24ce848e09c430be1da99a44576266e548. You have to remove (or rename) that container to be able to reuse that name.
Oct 25 05:04:44 localhost kubelet: E1025 05:04:44.481217 8889 kuberuntime_sandbox.go:54] CreatePodSandbox for pod "etcd-ecsmaster01_kube-system(fb87a1f1730f1fe65cd7ce2b1d5a84b8)" failed: rpc error: code = Unknown desc = failed to create a sandbox for pod "etcd-ecsmaster01": Error response from daemon: Conflict. The name "/k8s_POD_etcd-ecsmaster01_kube-system_fb87a1f1730f1fe65cd7ce2b1d5a84b8_3" is already in use by container a468c762916792739e99fc48a85c4a24ce848e09c430be1da99a44576266e548. You have to remove (or rename) that container to be able to reuse that name.
(3).杀死etcd,apiserver进程
[root@ecsmaster01 ~]# ps -ef | grep etcd
[root@ecsmaster01 ~]# kill 6577
[root@ecsmaster01 ~]# ps -ef | grep apiserver
[root@ecsmaster01 ~]# kill 11737
[root@ecsmaster01 ~]# systemctl restart kubelet
(4).问题解决
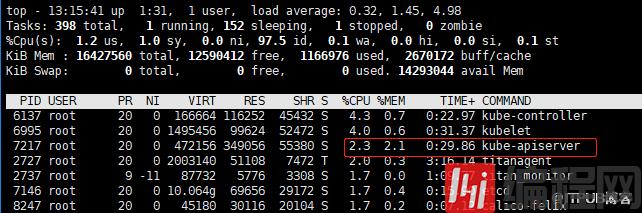
[root@ecsmaster01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ecsmaster01 Ready master 70d v1.10.0
ecsnode01 Ready <none> 70d v1.10.0
[root@ecsmaster01 ~]#
使用kubectl查看不到节点,apiserver进程没有
[root@k8s01 ~]# kubectl get nodes
The connection to the server 192.168.54.128:6443 was refused - did you specify the right host or port?
[root@k8s01 ~]# ps -ef | grep etcd
root 5833 4841 0 13:47 pts/0 00:00:00 grep --color=auto etcd
[root@k8s01 ~]# ps -ef | grep apiserver
root 5911 4841 0 13:47 pts/0 00:00:00 grep --color=auto apiserver
[root@k8s01 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Sat 2019-10-26 13:38:53 CST; 9min ago
Docs: https://kubernetes.io/docs/
Main PID: 657 (kubelet)
Memory: 104.3M
CGroup: /system.slice/kubelet.service
└─657 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --cgroup-driver=cgroupfs --network-plugin=cni --pod-inf...
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.472872 657 reflector.go:123] k8s.io/kubernetes/pkg/kubelet/config/apiserver.go:46: Failed to list *v1.Pod: Get https://192.168.54.128:6443/api/v1/pods?fieldSel...onnection refused
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.480930 657 kubelet.go:2267] node "k8s01" not found
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.581915 657 kubelet.go:2267] node "k8s01" not found
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.674114 657 reflector.go:123] k8s.io/kubernetes/pkg/kubelet/kubelet.go:450: Failed to list *v1.Service: Get https://192.168.54.128:6443/api/v1/services?limit=50...onnection refused
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.682619 657 kubelet.go:2267] node "k8s01" not found
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.783349 657 kubelet.go:2267] node "k8s01" not found
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.871726 657 reflector.go:123] k8s.io/kubernetes/pkg/kubelet/kubelet.go:459: Failed to list *v1.Node: Get https://192.168.54.128:6443/api/v1/nodes?fieldSelector=...onnection refused
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.884269 657 kubelet.go:2267] node "k8s01" not found
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.913384 657 controller.go:135] failed to ensure node lease exists, will retry in 7s, error: Get https://192.168.54.128:6443/apis/coordination.k8s.io/v1/namespac...onnection refused
Oct 26 13:48:07 k8s01 kubelet[657]: E1026 13:48:07.984757 657 kubelet.go:2267] node "k8s01" not found
Hint: Some lines were ellipsized, use -l to show in full.
[root@k8s01 ~]#
解决方法:
[root@k8s01 docker]# docker images --查看镜像时没有镜像
REPOSITORY TAG IMAGE ID CREATED SIZE
[root@k8s01 ~]# cat 16.sh
#!/bin/bash
# download k8s 1.15.2 images
# get image-list by 'kubeadm config images list --kubernetes-version=v1.15.2'
# gcr.azk8s.cn/google-containers == k8s.gcr.io
images=(
kube-apiserver:v1.16.0
kube-controller-manager:v1.16.0
kube-scheduler:v1.16.0
kube-proxy:v1.16.0
pause:3.1
etcd:3.3.15-0
coredns:1.6.2
)
for imageName in ${images[@]};do
docker pull gcr.azk8s.cn/google-containers/$imageName
docker tag gcr.azk8s.cn/google-containers/$imageName k8s.gcr.io/$imageName
docker rmi gcr.azk8s.cn/google-containers/$imageName
done
[root@k8s01 ~]# sh 16.sh --拉取镜像
[root@k8s01 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.16.0 b305571ca60a 5 weeks ago 217MB
k8s.gcr.io/kube-proxy v1.16.0 c21b0c7400f9 5 weeks ago 86.1MB
k8s.gcr.io/kube-controller-manager v1.16.0 06a629a7e51c 5 weeks ago 163MB
k8s.gcr.io/kube-scheduler v1.16.0 301ddc62b80b 5 weeks ago 87.3MB
k8s.gcr.io/etcd 3.3.15-0 b2756210eeab 7 weeks ago 247MB
k8s.gcr.io/coredns 1.6.2 bf261d157914 2 months ago 44.1MB
k8s.gcr.io/pause 3.1 da86e6ba6ca1 22 months ago 742kB
[root@k8s01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s01 Ready master 48d v1.16.0
k8s02 Ready <none> 48d v1.16.0
k8s03 Ready <none> 8d v1.16.0
[root@k8s01 ~]#
到此,相信大家对“Kubernetes安装报错怎么解决”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341



















