

SETNX分布锁详解

前提
为何要使用分布式锁?
其实使用分布式锁的目的与平常使用synchronized锁,Lock锁的目的一致,就是为了确保多线程并发时,在某些业务场景中让这些线程串行执行。
通常在一个JVM中让线程串行执行是比较容易实现的,例如synchronized锁,Lock锁等。但是现在为了应对更大的并发量,通常会将服务拆分或者搭建集群,此时synchronized锁,Lock锁就无法让处于不同服务器中的线程互斥,或者说让处于不同JVM中的线程互斥。此时就需要使用分布式锁让这些不同服务中的线程互斥,从而串行执行。
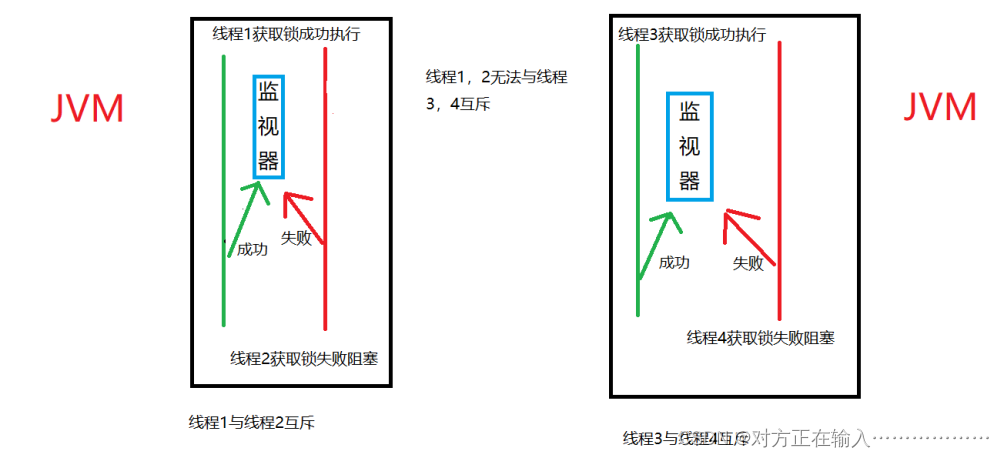
那什么是分布式锁?
分布式锁:在分布式系统下或者集群模式下能够实现多个线程之间互斥并且可见。
分布式锁的思想就是让处于不同服务器中的线程共同使用同一把锁,从而保证这些线程在某些场景下串行执行
分布式锁有那些?
说到分布式锁其实还是有很多的,像mysql分布式锁,redis分布式锁,zookeeper分布式锁等
现在我们采用Redis作为分布式锁,那么将上述图片的中的两个监视器换为一个redis在外部,那么图片就形象生动的出现在脑海中,脑补
SETNX命令的特性
SETNX:向Redis中添加一个key,只用当key不存在的时候才添加并返回1,存在则不添加返回0。并且这个命令是原子性的。
使用SETNX作为分布式锁时,添加成功表示获取到锁,添加失败表示未获取到锁。至于添加的value值无所谓可以是任意值(根据业务需求),只要保证多个线程使用的是同一个key,所以多个线程添加时只会有一个线程添加成功,就只会有一个线程能够获取到锁。而释放锁锁只需要将锁删除即可。
总结:
- 获取锁:通过setnx添加
- 释放锁:通过del将锁删除
SETNX分布式锁
设置过期时间防止死锁
假设线程1通过SETNX获取到锁并且正常执行然后释放锁那么一切ok,其它线程也能获取到锁。但是线程1现在"耍脾气"了,线程1抱怨说"工作太久有点累需要休息一下,你们想要获取锁等着吧,等我把活干完你们再来获取锁"。此时其它线程就无法向下继续执行,因为锁在线程1手中。这种长期不释放锁情况就有可能造成死锁。
为了防止像线程1这种"耍脾气"的现象发生,我们可以设置key的过期时间来解决。设置过期时间过后其它线程可不会惯着线程1,其它线程表示你要休息可以,休息了指定时间把锁让出来然后拍拍屁股走人,没人惯着你。
Redis命令:
在添加时存在则添加,不存在则不添加。同时设置过期时间,单位秒SET key value NX EX time原命令及其参数 SET key value [NX | XX] [GET] [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | KEEPTTL]JAVA代码:
//通过java代码实现SETNX同时设置过期时间//key--键 value--值 time--过期时间 TimeUnit--时间单位枚举stringRedisTemplate.opsForValue().setIfAbsent(key, value , time, TimeUnit);SETNX分布式锁时误删情况
情况一
设置过期时间线程1被治得服服帖帖,此时线程1又开始不当人了。线程1想既然你抢我得锁,等你获得锁后我就将锁删除毕竟我还要有备用钥匙,让你也锁不住,让其它线程也执行。
线程1休息的时间超过了过期时间,此时锁会自动释放。线程2现在脱颖而出抢到了锁然后开心的继续执行。但是现在线程1醒了,发现线程2抢走了锁。线程1表示小子胆挺肥啊,敢抢我的锁,等我执行完了就将你锁删除,让其它"哥们"也进来。此时就会发生蝴蝶效应,线程1删除了线程2的锁,线程2删除了线程3的锁,直到最后一个"哥们:wc,我锁了?"。当然线程是无感知,其实线程1乃至其它线程都不知道删除的是别人的锁,全部线程都以为删除的是自己的锁。直到最后一个线程无锁可删。
这种误删锁的情况让锁的存在荡然无存,本来应该串行执行的线程,在一定程度上都开始并发执行了。
那么误删情况该如何解决了?
我们可以给锁加上线程标识,只有锁是当前线程的才能删除,否则不能删除。在添加key的时候,key的value存储当前线程的标识,这个标识只要保证唯一即可。可以使用UUID或者一个自增数据。在删除锁的时候,将线程标识取出来进行判断,如果相同就表示锁是自己的能够删除,否则不能删除。
获取锁:
//获取线程前缀,同时也是线程表示。通过UUID唯一性private static final String ID_PREFIX= UUID.randomUUID().toString(true)+"-";//与线程id组合public boolean tryLock(long timeOut) { //获取线程id String id =ID_PREFIX+ Thread.currentThread().getId(); //获取锁 Boolean absent = stringRedisTemplate.opsForValue().setIfAbsent(key, id , timeOut, TimeUnit.SECONDS); return Boolean.TRUE.equals(absent); }释放锁:
public void unLock() {//获取存储的线程标识 String value = stringRedisTemplate.opsForValue().get(key); //当前线程的线程标识 String id =ID_PREFIX+ Thread.currentThread().getId(); //线程标识相同则删除否,则不删除 if (id.equals(value)){ stringRedisTemplate.delete(key); } }情况二
加入线程标识后,线程一不能随便删除其它线程的锁,但是线程1又开始不当人了。线程1表示判断线程标识和释放锁的操作我可以分开执行,这又不是一个原子性的操作,线程1干完活以后就准备去释放锁,当线程1判断锁是自己的后表示开锁太累了,休息一会在开。此时其它线程就想无所谓,反正过期时间一到锁就会自动释放。但是线程1已经判断了锁是自己的以后就不会执行判断锁的操作(线程1已经执行了if判断,只是没有执行方法体),当线程2获得锁后,线程1仍然能删除线程2的锁。
特别说明:
- 线程1执行的时间片到了就会发生线程切换
- JVM执行垃圾回收,因为垃圾回收会暂停用户线程,让垃圾回收线程单独执行。尽管现在的CMS,G1垃圾回收器能够做到并发收集,但是CMS和G1的初始标记以及CMS的重新标记,G1的最终标记仍然需要STW(Stop The World)
public void unLock() { String value = stringRedisTemplate.opsForValue().get(key); //在此处发生垃圾回收,线程1暂停并且超过了过期时间,线程2先获得了锁 String id =ID_PREFIX+ Thread.currentThread().getId(); if (id.equals(value)){ //在此处发生垃圾回收,线程1暂停并且超过了过期时间,线程2先获得锁 stringRedisTemplate.delete(key); } }此时就需要将判断锁的操作和删除锁的操作作为一个整体执行,要么全部成功,要么全部失败,保证删除锁的原子性。
Lua脚本解决多条命令原子性问题
关于Lua语言参考此链接:Lua
导致线程1删除线程2锁的原因就是判断锁和删除锁的操作不是原子性的。此时可以使用Lua脚本保证多条命令的原子性。
Redis提供的函数:
redis.call('命令名称', 'key', '其它参数', ...)例如:redis.call('set','name','jack')---->set name jackLua脚本: 会将key存储在KEYS数组中,会将value存储在ARVG数组中。下标从1开始
if (redis.call('get',KEYS[1])==ARGV[1]) then return redis.call('DEL',KEYS[1])end return 0JAVA:通过execute()方法执行Lua脚本,DefaultRedisScript加载脚本
private static final DefaultRedisScript<Long> DEFAULT_REDIS_SCRIPT; static { DEFAULT_REDIS_SCRIPT=new DefaultRedisScript<Long>(); DEFAULT_REDIS_SCRIPT.setLocation(new ClassPathResource("unlock.lua")); DEFAULT_REDIS_SCRIPT.setResultType(Long.class); } public void unLock() { stringRedisTemplate.execute(DEFAULT_REDIS_SCRIPT, Collections.singletonList(RedisConstants.KEY_PREFIX + name),ID_PREFIX+ Thread.currentThread().getId()); }最后
文中提及SETNX作为分布式锁的原理以及存在的问题都是学习过程中的总结。
SETNX分布锁锁存在的问题:
- 重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
- 不可重试:是指目前的分布式只能尝试一次,合理的情况是:当线程在获得锁失败后,应该能再次尝试获得锁。
- 超时释放:加锁时增加了过期时间,可以防止死锁,但是如果卡顿的时间超长,虽然采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
- 主从一致性: 如果Redis提供了主从集群,当向集群写数据时,主机需要异步的将数据同步给从机,如果在同步过去之前,主机宕机了,就会出现死锁问题。
来源地址:https://blog.csdn.net/qq_47288175/article/details/127441620
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341











