

mysql详解之B+树的查询时间复杂度

前言
B+ 树搜索时间复杂度到底是什么(这篇文章分析了全网各种关于b+树时间复杂度相关博客的结论,总结并分析了他们结论差异的原因)。
本文在此基础上,对文中的结论做了进一步思考(如果对解题过程不感兴趣,可以直接看最后的总结)。
正题
在这篇文章中,得知B+树在内存里的时间复杂度是:
O( log 2 m ⋅ log m n ) O(\log_2^m \cdot \log_m^n) O(log2m⋅logmn)
然后我就想比较一下B+树和二叉树的时间复杂度。我们知道二叉树的时间复杂度是O(logn)【计算机行业的简写:把底数2给省略了】,完整的数学公式是:
O( log 2 n ) O(\log_2^n) O(log2n)
注意:本文所有二叉树都指的平衡二叉树,并且和B+树一样把数据存在叶子节点上。(事实上,二叉树都时间复杂度,就是在这样的前提条件下计算出来的)。
其实文本的目的就是:观察B+树分支(度)的变化,对时间复杂度的影响(当分支为2时,就是二叉树)。
怎么比较呢?前者有两个变量,后者只有一个变量。我们可以给m固定几个数,然后观察几条函数曲线。
使用一个在线函数绘制工具
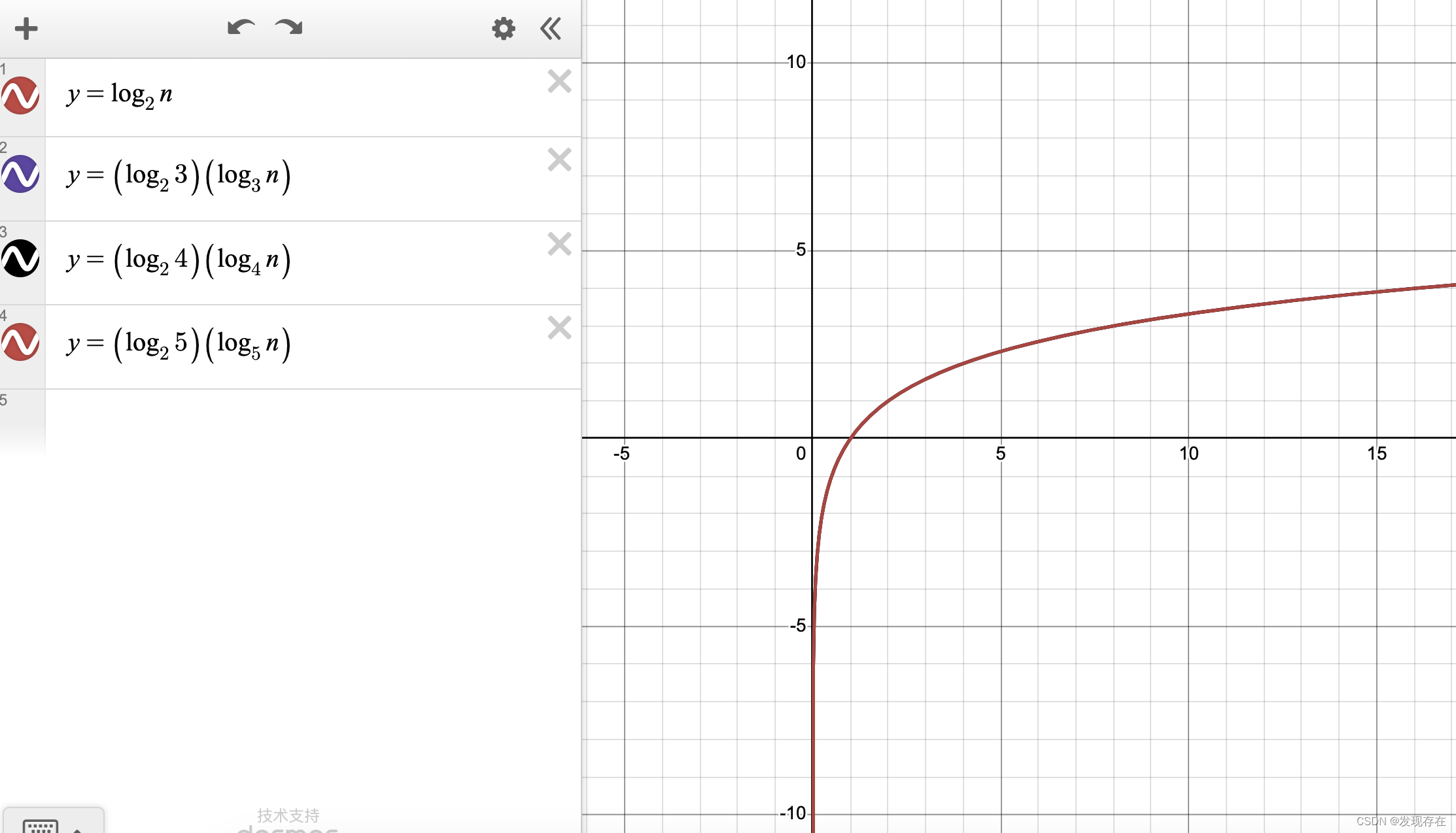
第一个是二叉树的时间复杂度函数。后三个分别是b+树的时间复杂度函数,m分别为3,4,5。
发现一个惊人的结果:他们看起来好像都完全重合了!
莫非 log 2m ⋅ log mn = log 2n \log_2^m \cdot \log_m^n = \log_2^n log2m⋅logmn=log2n ?
在网上搜了一下相关的对数公式,没什么解题思路。
难道他们只是约等于? 只是误差很小,看不出来?不过也有可能是自己高中数学知识还给老师了,不会解而已(因为我把这个函数曲线无论怎么放大,或者往后看,都是一样的,应该不至于误差那么小)。
但当我用m去假设,带入m=2。m=4。 m=8尝试化简,结合一个对数公式,居然找到解题思路了。
解:
根据公式
m n ⋅ log a b = log a n b m \frac{m}{n} \cdot \log_a^b = \log_{a^n}^{b^m} nm⋅logab=loganbm
设
m= 2 x m = 2^x m=2x
变换( n = n1 n = n^1 n=n1)之后,根据前面的那个公式,可得到
log 2 m ⋅ log m n = log 2 2 x ⋅ log 2 x n 1 =x⋅( 1 x ⋅ log 2 n )= log 2 n \log_2^m \cdot \log_m^n = \log_2^{2^x} \cdot \log_{2^x}^{n^1} = x \cdot ( \frac{1}{x} \cdot \log_2^n) = \log_2^n log2m⋅logmn=log22x⋅log2xn1=x⋅(x1⋅log2n)=log2n
稍微解释一下:m 为什么可以等于 2 x 2^x 2x
m在这里就是大于2的自然数,这句话其实就是问 2x 2^x 2x能不能表示任意一个大于2的自然数。当然是可以的,因为 2x 2^x 2x是一条大于0的连续曲线。
所以:在内存里,当元素一样,b+树在一个节点内也采用二分法查找元素(最快的方式)。b树和二叉树的时间复杂度都是O(logN)。
总结
在内存里(不考虑磁盘io的特殊性),n叉树的查询时间复杂度都是O(logN)。
其他
关于开头那篇博客的最后一句:
log m N 可以简写为logN \log_m^N 可以简写为 logN logmN可以简写为logN
我是不太认同的。
按照作者的意思,底数m的变化对结果影响不大,可以省略。
下面这几条曲线从上到下,依次对应左边从上到下的四个函数(m=2,m=3,m=100,m=1000)
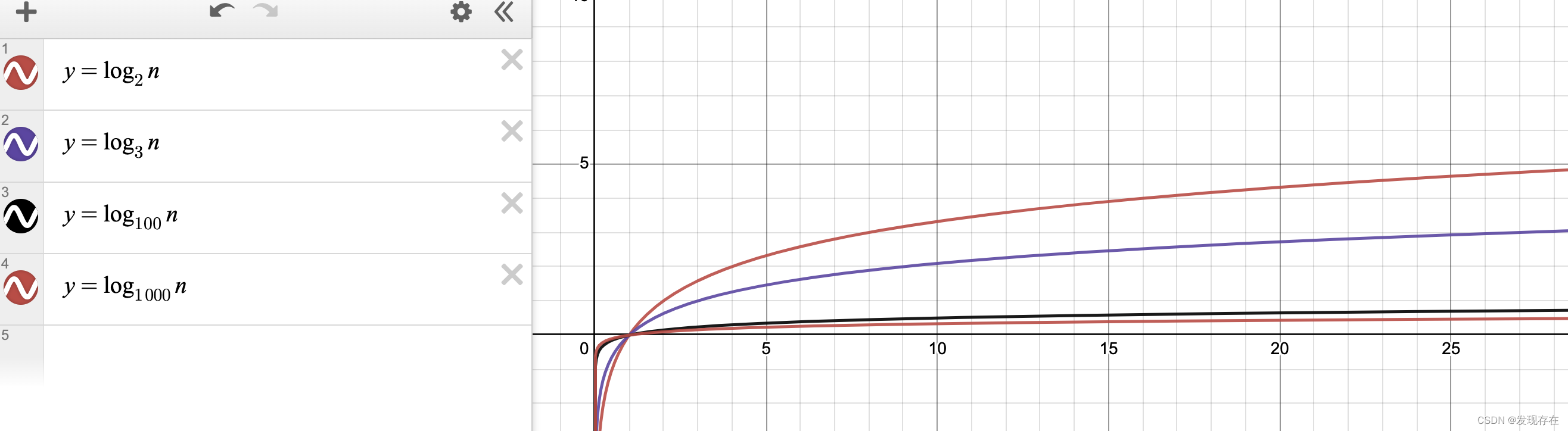
看函数曲线,对数函数确实变化非常缓,底数对结果影响也没那么明显。
当n=1000000(一百万)时
二叉树需要遍历20次,而“1000叉树”只需要2次。如果在内存里,差别确实不大,都会非常快。
但作者那句话的前提是:考虑磁盘IO。也就是说这是在讨论类似数据库的场景。
在100万正常数据量的情况下,二叉树需要磁盘io达到20次,这肯定是不可接受的。
而m=1000就是mysql一般的分叉数量级(度数),这也就我们说的:mysql的B+索引树一般就是3层。
来源地址:https://blog.csdn.net/yunduanyou/article/details/128233801
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341


![[mysql]mysql8修改root密码](https://static.528045.com/imgs/45.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









