Mysql分表查询海量数据和解决方案

lzzyok小宝贝
2024-04-23 23:21

众所周知数据库的管理往往离不开各种的数据优化,而要想进行优化通常我们都是通过参数来完成优化的。那么到底这些参数有哪些呢?为此在本篇文章中编程学习网笔者就为大家简单介绍MySQL,以供大家参考参考,希望能帮助到大家。

1) 分布式DB水平切分中用到的主要关键技术:分库,分表,M-S,集群,负载均衡
2) 需求分析:一个大型互联网应用每天几十亿的PV对DB造成了相当高的负载,对系统的稳定性的扩展性带来极大挑战。
3) 现有解决方式:通过数据切分提高网站性能,横向扩展数据层
水平切分DB,有效降低了单台机器的负载,也减小了宕机的可能性。
集群方案:解决DB宕机带来的单点DB不能访问问题。
读写分离策略:极大限度提高了应用中Read数据的速度和并发量。
典型例子:Taobao,Alibaba,Tencent,它们大都实现了自己的分布式数据访问层(DDAL)。Taobao的基于ibatis和spring的的分布式数据访问层,已有多年的应用,运行效率和生产实效性得到了开发人员和用户的肯定。
水平切分需要考虑的后续问题:分库后路由规则的选择和制定,以及后期扩展。如,如何以最少的数据迁移达到最大容量的扩展。因些路由表分规则以及负载均衡的考虑很重要。
4)对于DB切分,实质上就是数据切分。下面从What, Why, How三个方面来讲述。
What?什么是数据切分?
具体将有什么样的切分方式呢和路由方式呢?举个简单的例子:我们针对一个应用中的日志来说明,比如日志文章(article)表有如下字段:
article_id(int),title(varchar(128)),content(varchar(1024)),user_id(int)
面对这样的一个表,我们怎样切分呢?怎样将这样的数据分布到不同的数据库中的表中去呢?其实分析blog的应用,我们不难得出这样的结论:blog的应用中,用户分为两种:浏览者和blog的主人。浏览者浏览某个blog,实际上是在一个特定的用户的blog下进行浏览的,而blog的主人管理自己的blog,也同样是在特定的用户blog下进行操作的(在自己的空间下)。所谓的特定的用户,用数据库的字段表示就是“user_id”。就是这个“user_id”,它就是我们需要的分库的依据和规则的基础。我们可以这样做,将user_id为1~10000的所有的文章信息放入DB1中的article表中,将user_id为10001~20000的所有文章信息放入DB2中的article表中,以此类推,一直到DBn。这样一来,文章数据就很自然的被分到了各个数据库中,达到了数据切分的目的。接下来要解决的问题就是怎样找到具体的数据库呢?其实问题也是简单明显的,既然分库的时候我们用到了区分字段user_id,那么很自然,数据库路由的过程当然还是少不了user_id的。考虑一下我们刚才呈现的blog应用,不管是访问别人的blog还是管理自己的blog,总之我都要知道这个blog的用户是谁吧,也就是我们知道了这个blog的user_id,就利用这个user_id,利用分库时候的规则,反过来定位具体的数据库,比如user_id是234,利用该才的规则,就应该定位到DB1,假如user_id是12343,利用该才的规则,就应该定位到DB2。以此类推,利用分库的规则,反向的路由到具体的DB,这个过程我们称之为“DB路由”。
当然考虑到数据切分的DB设计必然是非常规,不正统的DB设计。那么什么样的DB设计是正统的DB设计呢?
我们平常规规矩矩用的基本都是。平常我们会自觉的按照范式来设计我们的数据库,负载高点可能考虑使用相关的Replication机制来提高读写的吞吐和性能,这可能已经可以满足很多需求,但这套机制自身的缺陷还是比较显而易见的。上面提到的“自觉的按照范式设计”。考虑到数据切分的DB设计,将违背这个通常的规矩和约束,为了切分,我们不得不在数据库的表中出现冗余字段,用作区分字段或者叫做分库的标记字段,比如上面的article的例子中的user_id这样的字段(当然,刚才的例子并没有很好的体现出user_id的冗余性,因为user_id这个字段即使就是不分库,也是要出现的,算是我们捡了便宜吧)。当然冗余字段的出现并不只是在分库的场景下才出现的,在很多大型应用中,冗余也是必须的,这个涉及到高效DB的设计。
Mysql实现海量海量数据存储查询时,主要有几个关键点,分表,分库,集群,M-S,负载均衡。
其中分库分表是很重要的一点。分库是如何将海量的MySQL数据放到不同的服务器中,分表则是在分库基础上对数据现进行逻辑上的划分。

数据划分可有多种方式,找到一个主键后,可以按号段分,也可以Hash取模分,也可以选择在认证库中保存DB配置。具体如何选择具体情况具体分析。
划分后,就是后期的查找和维护工作了。为了实现快速查找,得有一个高效的查找机制,这里可以选择建索引的方法,并充分借鉴已有的成熟的路由技术。同时,增减数据时,还要考虑到索引的维护,数据迁移时,数据的重新分摊也是一个要考虑的问题。下面具体分析数据变更的情形:
大型应用中Mysql经常碰到数据无限扩充的情况。常用解决方案如下:
MySQL master/slave: 只适合大量读的情形,未必适合海量数据。
MySQL cluster: 提供的可能不是大家想要那种功能。
MySQL proxy: MySQL master/slave配合
MySQL 5.1 partition: 只是将一个表存储上逻辑分开,部分改善了性能,但是可扩展性仍然是问题。
MySQL对于海量数据按应用逻辑分表分数据库,通过程序来决定数据存放的表。但是
跨区查询是一个问题,当需要快速查找一个数据时你得准确知道那个数据存在哪个地方。为了达到这个目的,可以将分表逻辑放到中间层,这样上层的应用则就简单很多,也便于扩展。下面结合网上一个关于分表查询很好的例子分析:
Why?为什么要切分数据?
1) 像Oracle这样成熟稳定的DB可以支撑海量数据的存储和查询,但是价格不是所有人都承受得起。
2) 负载高点时,Master-Slaver模式中存在瓶颈。现有技术中,在负载高点时使用相关的Replication机制来实现相关的读写的吞吐性能。这种机制存在两个瓶颈:一是有效性依赖于读操作的比例,这里Master往往会成为瓶颈所在,写操作时需要一个顺序队列来执行,过载时Master会承受不住,Slaver的数据同步延迟也会很大,同时还会消耗CPU的计算能力,为write操作在Master上执行以后还是需要在每台slave机器上都跑一次。而Sharding可以轻松的将计算,存储,I/O并行分发到多台机器上,这样可以充分利用多台机器各种处理能力,同时可以避免单点失败,提供系统的可用性,进行很好的错误隔离。
3) 用免费的MySQL和廉价的Server甚至是PC做集群,达到小型机+大型商业DB的效果,减少大量的资金投入,降低运营成本,何乐而不为呢?
How?如何切分数据?
先对数据切分的方法和形式进行比较详细的阐述和说明。
数据切分可以是物理上的,对数据通过一系列的切分规则将数据分布到不同的DB服务器上,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
数据切分也可以是数据库内的,对数据通过一系列的切分规则,将数据分布到一个数据库的不同表中,比如将article分为article_001,article_002等子表,若干个子表水平拼合有组成了逻辑上一个完整的article表,这样做的目的其实也是很简单的。举个例子说明,比如article表中现在有5000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成100个table呢,从article_001一直到article_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量。当然分表的好处还不知这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
综上,分库降低了单点机器的负载;分表,提高了数据操作的效率,尤其是Write操作的效率。
上文中提到,要想做到数据的水平切分,在每一个表中都要有相冗余字符作为切分依据和标记字段,通常的应用中我们选用user_id作为区分字段,基于此就有如下三种分库的方式和规则:(当然还可以有其他的方式)

按号段分:
(1) user_id为区分,1~1000的对应DB1,1001~2000的对应DB2,以此类推;
优点:可部分迁移
缺点:数据分布不均
(2) hash取模分:
对user_id进行hash(或者如果user_id是数值型的话直接使用user_id的值也可),然后用一个特定的数字,比如应用中需要将一个数据库切分成4个数据库的话,我们就用4这个数字对user_id的hash值进行取模运算,也就是user_id%4,这样的话每次运算就有四种可能:结果为1的时候对应DB1;结果为2的时候对应DB2;结果为3的时候对应DB3;结果为0的时候对应DB4,这样一来就非常均匀的将数据分配到4个DB中。
优点:数据分布均匀
缺点:数据迁移的时候麻烦,不能按照机器性能分摊数据
(3) 在认证库中保存数据库配置
就是建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
优点:灵活性强,一对一关系
缺点:每次查询之前都要多一次查询,性能大打折扣
以上就是通常的开发中我们选择的三种方式,有些复杂的项目中可能会混合使用这三种
方式。
4) 接下来对分布式数据库解决海量数据的存访问题做进一步介绍
分布式数据方案提供功能如下:
(1)提供分库规则和路由规则(RouteRule简称RR),将上面的说明中提到的三中切分规则直接内嵌入本系统,具体的嵌入方式在接下来的内容中进行详细的说明和论述;
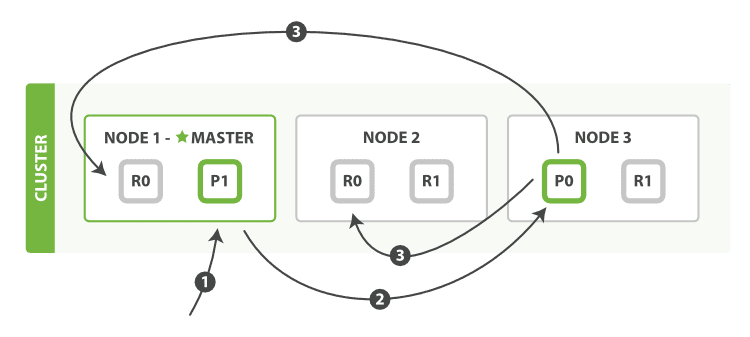
(2)引入集群(Group)的概念,解决容错性的问题,保证数据的高可用性;
(3)引入负载均衡策略(LoadBalancePolicy简称LB);
(4)引入集群节点可用性探测机制,对单点机器的可用性进行定时的侦测,以保证LB策略的正确实施,以确保系统的高度稳定性;
(5)引入读/写分离,提高数据的查询速度;
5)MySQL partition
MySQL 5.1 的 partition 功能由于单张表的数据跨文件,批量查询时候同样存在上述问题,不过它是在 MySQL 内部实现的,不需要外部调用者关心。其查询实现的原理应该大致类似。但 partition 只解决了 IO 的瓶颈,并不能解决 CPU 计算的瓶颈,因此无法代替传统的手工分表方式。
对于这个问题还有许多其他方法,学网络的应该很熟悉DNS的两种查询方法:递归方式和迭代方式。这些思路也可以应用到数据库查询中来并应用。如,HSCALE分表分数据库的思路:HSCALE是在MySQL proxy的基础上,在MySQL proxy的层面将上层的请求分配到实际的表上。实际的原理是通过拦截SQL进行替换和服务器重定向再将SQL传递到目标服务器上。它的分表算法可以由自定义的Lua脚本来实现,非常灵活。目前已经能支持同数据库分表,跨数据库的实现也将增加,因为在MySQL proxy的框架下,这并不是很困难的事情。使用HSCALE有2个开销,一是网络层面的,、MySQL proxy对每个SQL会增加0.0 ms级的网络延迟,如果增加了HSCALE, 则会增加0. ms级延迟。第2个开销则是MySQL proxy, Lua, SQL解析,HSCALE算法等造成。现在的版本或许不是很成熟,但是在原理上基本上没多大障碍,发展下去将是一个不错的选择。
以上就是关于大数据的知识点了。喜欢的可以分享给你的朋友,也可以点赞噢~更多内容,就在编程学习网!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341