

HanLP自然语言处理包如何安装与使用


这篇文章主要介绍了HanLP自然语言处理包如何安装与使用,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
HanLP是由一系列模型与算法组成的Java工具包,目标是促进自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
HanLP能提供以下功能:关键词提取、短语提取、繁体转简体、简体转繁体、分词、词性标注、拼音转换、自动摘要、命名实体识别(地名、机构名等)、文本推荐等功能,详细请参见以下链接:http://www.hankcs.com/nlp/hanlp.html
HanLP下载地址:
https://github.com/hankcs/HanLP/releases,HanLP项目主页:
https://github.com/hankcs/HanLP
1、HanLP安装
hanlp是由jar包、properties文件和data数据模型组成,因此,在安装时,这三种文件都应该有。可以通过建立java工程即可运行。
hanlp.properties文件中描述了不同词典的相对路径以及root根目录,因此,可以在此文件中修改其路径。
hanlp-1.3.4.jar包中包含了各种算法及提取方法的api,大部分方法都是静态的,可以通过HanLP直接进行调用,因此,使用非常方便。
data文件夹中包含了dictionary和model文件夹,dictionary中主要是各种类型的词典,model主要是分析模型,hanlp api中的算法需要使用model中的数据模型。
2、HanLP的使用
普通java工程目录如下所示:

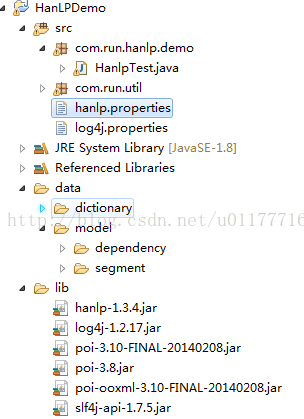
3、HanLP的具体使用
例如:对excel中的聊天记录字段进行热点词的提取,计算并排序,功能如下所示
package com.run.hanlp.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.log4j.Logger;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.suggest.Suggester;
import com.hankcs.hanlp.summary.TextRankKeyword;
import com.hankcs.hanlp.tokenizer.NLPTokenizer;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import com.run.util.ExcelUtil;
public class HanlpTest {
public static final Logger log = Logger.getLogger(HanlpTest.class);
public static void main(String[] args) {
log.info("关键词提取:");
HanlpTest.getWordAndFrequency();
}
public static void getWordAndFrequency() {
// String content =
// "程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。";
List<Map<String, Integer>> content = ExcelUtil.readExcelByField("i:/rundata/excelinput",5000,5);
Map<String, Integer> allKeyWords=new HashMap<>();
for(int i=0;i<content.size();i++){
Map<String, Integer> oneMap=content.get(i);
for(String str:oneMap.keySet()){
int count = oneMap.get(str);
CombinerKeyNum(str,count,allKeyWords);
}
}
List<Map.Entry<String,Integer>> sortedMap=sortMapByValue(allKeyWords);
log.info(sortedMap);
}
public static List<Map.Entry<String,Integer>> sortMapByValue(Map<String,Integer> allKeyWords){
List<Map.Entry<String,Integer>> sortList=new ArrayList<>(allKeyWords.entrySet());
Collections.sort(sortList, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return (o2.getValue() - o1.getValue());
}
});
return sortList;
}
public static void CombinerKeyNum(String key,int value,Map<String,Integer> allKeyWords){
if(allKeyWords.containsKey(key)){
int count=allKeyWords.get(key);
count+=value;
allKeyWords.put(key, count);
}else{
allKeyWords.put(key, value);
}
}
public static HashMap<String, Integer> getKeyWordMap(String content) {
List<Term> list = StandardTokenizer.SEGMENT.seg(content);
TextRankKeyword textmap = new TextRankKeyword();
Map<String, Float> map = textmap.getTermAndRank(content);
Map<String, Integer> mapCount = new HashMap<>();
for (String str : map.keySet()) {
String keyStr = str;
int count = 0;
for (int i = 0; i < list.size(); i++) {
if (keyStr.equals(list.get(i).word)) {
count++;
}
}
mapCount.put(keyStr, Integer.valueOf(count));
}
// log.info(mapCount);
return (HashMap<String, Integer>) mapCount;
}
}
运行之后,结果如下:


由此可见,可以看见从excel中提取出来的热点词汇及其频率。
感谢你能够认真阅读完这篇文章,希望小编分享的“HanLP自然语言处理包如何安装与使用”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341



![[mysql]mysql8修改root密码](https://static.528045.com/imgs/31.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









