

如何深入分析Kafka架构的工作流程、存储机制、分区策略

这期内容当中小编将会给大家带来有关如何深入分析Kafka架构的工作流程、存储机制、分区策略,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
一、前言
在开始之前首先要明确一点,kafka是一个分布式流平台,本质上是一个消息队列。谈到消息队列,就会联想到消息队列的三大作用:异步、消峰、解耦。kafka主要应用在大数据的实时处理领域,使用起来比较简单,本文主要分析kafka的工作流程、存储机制,分区策略,并围绕多个角度展开总结。
但是要注意的是,随着时代的巨轮驶向2020,目前kafka已经不是一家独大了,Pulsar作为一个天生支持多租户、跨地域复制、统一消息模型的消息平台,已经在不少企业成功的替代了Kafka。关于Apache Pulsar的更多知识,感兴趣的可以关注我,后面会对它进行总结和深入。
二、kafka工作流程
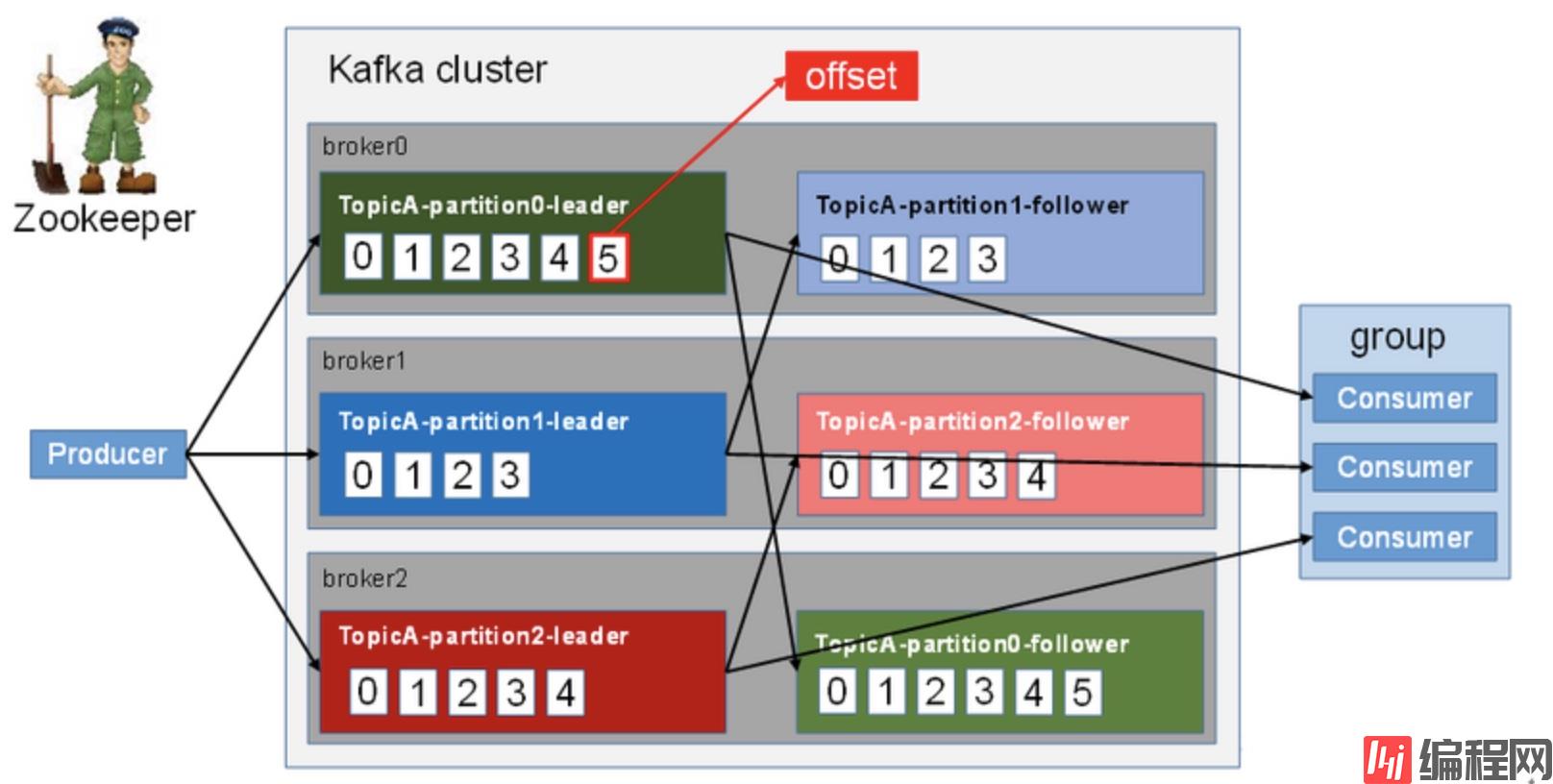
kafka将消息按照topic进行分类,每条message由三个属性组成。
offset:表示 message 在当前 Partition 中的偏移量,是一个逻辑上的值,唯一确定了 Partition 中的一条 message,可以简单的认为是一个 id;
MessageSize:表示 message 内容 data 的大小;
data:message 的具体内容
在整个kafka架构中,生产者和消费者采用发布和订阅的模式,生产者生产消息,消费者消费消息,它俩各司其职,并且都是面向topic的。(需要注意:topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。)
Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。
消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,这样当出现故障并恢复后,可以从这个offset位置继续进行消费,避免漏掉数据或者重复消费。
二、文件存储机制
2.1、文件存储结构及命名规则
在kafka的设计之初,考虑到了生产者生产的消息不断追加到log文件末尾后导致log文件过大的情况,所以采用了分片和索引机制,具体来说就是将每个partition分为多个segment。每个segment对应三个文件:.index 文件、.log 文件、.timeindex 文件(早期版本中没有)。其中.log和.index文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,csdn这个topic有2个分区,则其对应的文件夹为csdn-0,csdn-1;
如果我们打开csdn-0这个文件夹,会看到里面的文件如下:
00000000000000000000.index00000000000000000000.log00000000000000150320.index00000000000000150320.log通过这个文件夹下有两个log,我们可以得出结论,这个partition有2个segment。
文件命名规则:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充。
注意:index 文件并不是从0开始,也不是每次递增1的,这是因为 Kafka 采取稀疏索引存储的方式,每隔一定字节的数据建立一条索引,它减少了索引文件大小,使得能够把 index 映射到内存,降低了查询时的磁盘 IO 开销,同时也并没有给查询带来太多的时间消耗。
下面引用一张旧的kafka存储机制图,不带.timeindex 文件: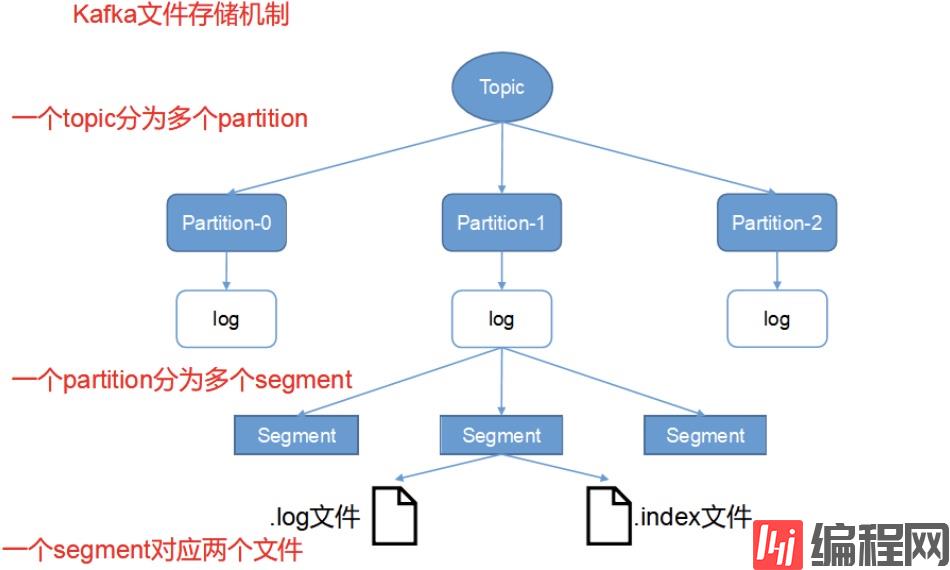
2.2、文件关系
index文件和log文件的关系:“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。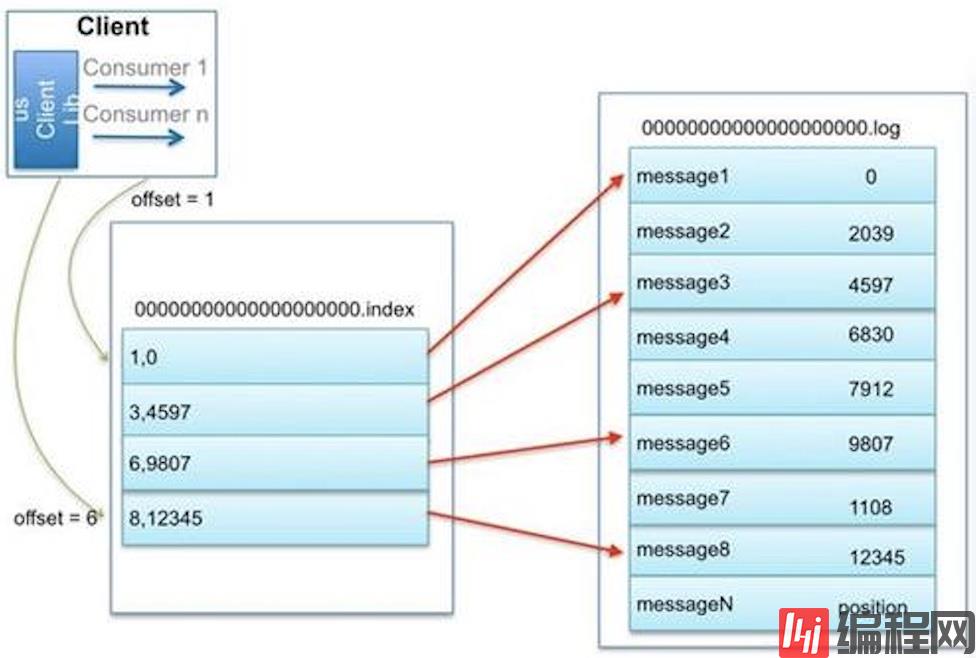
2.3、使用offset查找message
因为每一个segment文件名为上一个 Segment 最后一条消息的 offset ,所以当需要查找一个指定 offset 的 message 时,通过在所有 segment 的文件名中进行二分查找就能找到它归属的 segment ,再在其 index 文件中找到其对应到文件上的物理位置,就能拿出该 message 。
举例:这里我们以查找offset为6的message为例,查找流程如下:
首先要确定这个offset信息在哪个segment文件(由于是顺序读写,这里使用二分查找法),第一个文件名为00000000000000000000,第二个为00000000000000150320,所以6这个offset的数据肯定在第一个文件里面;
找到文件后就好办了,在这个文件的 00000000000000000000.index文件中的[6,9807]定位到00000000000000000000.log文件中9807这个位置来进行数据读取即可。
三、分区策略
3.1、为什么要进行分区
在了解分区策略之前需要先了解为什么要分区,可以从两方面来解释这个问题:
方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据;
可以提高并发,分区后以Partition为单位读写。
3.2、分区策略
首先要知道producer发送的数据其实需要封装成一个ProducerRecord对象才可以,我们看ProducerRecord提供的方法如下:

通过这个构造方法,我们知道kafka分区策略有如下3种:
指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
上述就是小编为大家分享的如何深入分析Kafka架构的工作流程、存储机制、分区策略了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












