

如何使用Python爬虫爬取网站图片

这篇文章主要介绍了如何使用Python爬虫爬取网站图片,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
此次python3主要用requests,解析图片网址主要用beautiful soup,可以基本完成爬取图片功能,
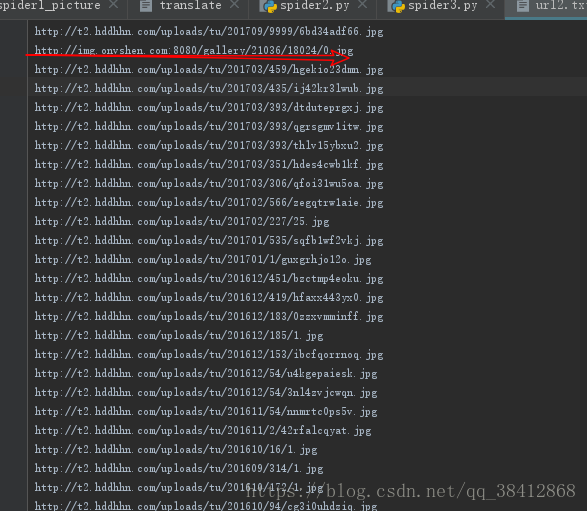
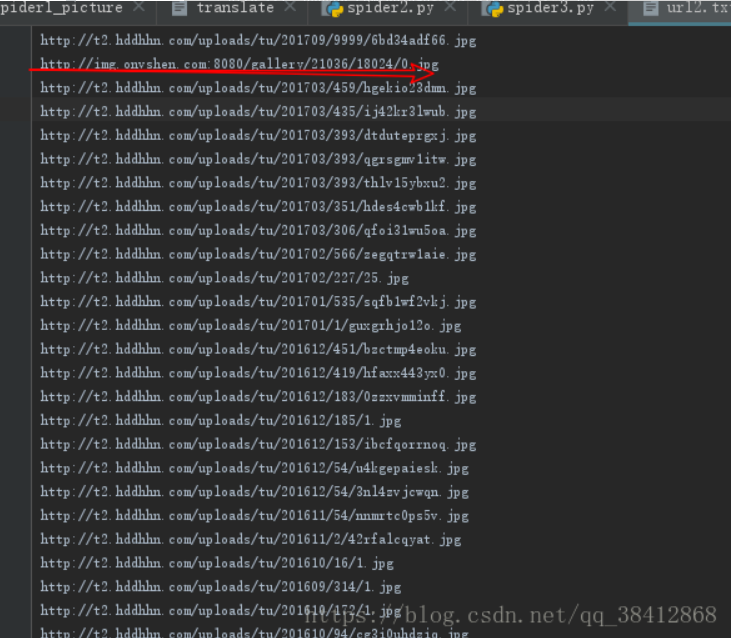
爬虫这个当然大多数人入门都是爬美女图片,我当然也不落俗套,首先也是随便找了个网址爬美女图片
from bs4 import BeautifulSoupimport requests if __name__=='__main__': url='http://www.27270.com/tag/649.html' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"} req = requests.get(url=url, headers=headers) req=requests.get(url=url,headers=headers) req.encoding = 'gb2312' html=req.text bf=BeautifulSoup(html,'lxml') targets_url=bf.find('div',class_='w1200 oh').find_all('a',target='_blank') for each in targets_url: img_req=requests.get(url=each.get('href'),headers=headers) img_req.encoding = 'gb2312' html = img_req.text bf = BeautifulSoup(html, 'lxml') img_url = bf.find('div', class_='articleV4Body').find('img')['class="lazy" data-src'] name=each.img.get('alt')+'.jpg' path=r'C:\Users\asus\Desktop\新建文件夹' file_name = path + '\\' + name try: req1=requests.get(img_url,headers=headers) f=open(file_name,'wb') f.write(req1.content) f.close() except: print("some error")期间遇到的一个情况是,它到访问img_url的时候总报错连接主机失败,我开始以为是网址加了反爬之类的,但是我单独拿出来一个网址,却可以很容易的访问,百思不得其解,最后咨询大佬告诉我把img_url的每一个都试试看,可能是某一个网址出了问题,找了找果然是有个叛徒,产生的img_url中第二个网址无法访问,怪不得老报错,我应该多试几个的,一叶障目
我同时也是个火影迷,掌握基本方法后准备试试爬取火影图片,也是网址找了个网址:
http://desk.zol.com.cn/dongman/huoyingrenzhe/
可以看到火影的图片是以图集的形式储存的,所以这个下载就比刚才的稍微多了一点步骤
查看网站源代码容易发现,图集的链接所在都是class='photo-list-padding'的li标签里,且链接没有补全

点开其中一个链接, http://desk.zol.com.cn/dongman/huoyingrenzhe/(前面为浏览器自动补全,在代码里需要自己补全)
可以看到图片的下载地址以及打开本图集下一张图片的链接

了解完网站的图片构造后动手写代码,我们筛选出图集的链接后,通过图集的链接找到第一张图片下载地址和第二张图片的链接,通过第二张的链接找到第二张的下载地址和第三张的链接,循环下去,直到本图集到底,接着开始第二个图集,直到所有图集下载完毕,代码如下,为了方便循环,我们集成下载图片功能为download函数,解析图片网址功能为parses_picture:
from bs4 import BeautifulSoupimport requests def download(img_url,headers,n): req = requests.get(img_url, headers=headers) name = '%s'%n+'='+img_url[-15:] path = r'C:\Users\asus\Desktop\火影壁纸1' file_name = path + '\\' + name f = open(file_name, 'wb') f.write(req.content) f.close def parses_picture(url,headers,n): url = r'http://desk.zol.com.cn/' + url img_req = requests.get(url, headers=headers) img_req.encoding = 'gb2312' html = img_req.text bf = BeautifulSoup(html, 'lxml') try: img_url = bf.find('div', class_='photo').find('img').get('class="lazy" data-src') download(img_url,headers,n) url1 = bf.find('div',id='photo-next').a.get('href') parses_picture(url1,headers,n) except: print(u'第%s图片集到头了'%n) if __name__=='__main__': url='http://desk.zol.com.cn/dongman/huoyingrenzhe/' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"} req = requests.get(url=url, headers=headers) req=requests.get(url=url,headers=headers) req.encoding = 'gb2312' html=req.text bf=BeautifulSoup(html,'lxml') targets_url=bf.find_all('li',class_='photo-list-padding') n=1 for each in targets_url: url = each.a.get('href') parses_picture(url,headers,n) n=n+1期间遇到的一个情况是每次一个图集到底的时候,就会产生报错,因为找不到下一张图片的链接了,于是我便加上try语句来捕捉这一报错,让程序继续下去,有了bf果然比正则表达式简单,可以通过标签属性很方便的找到想要的信息。
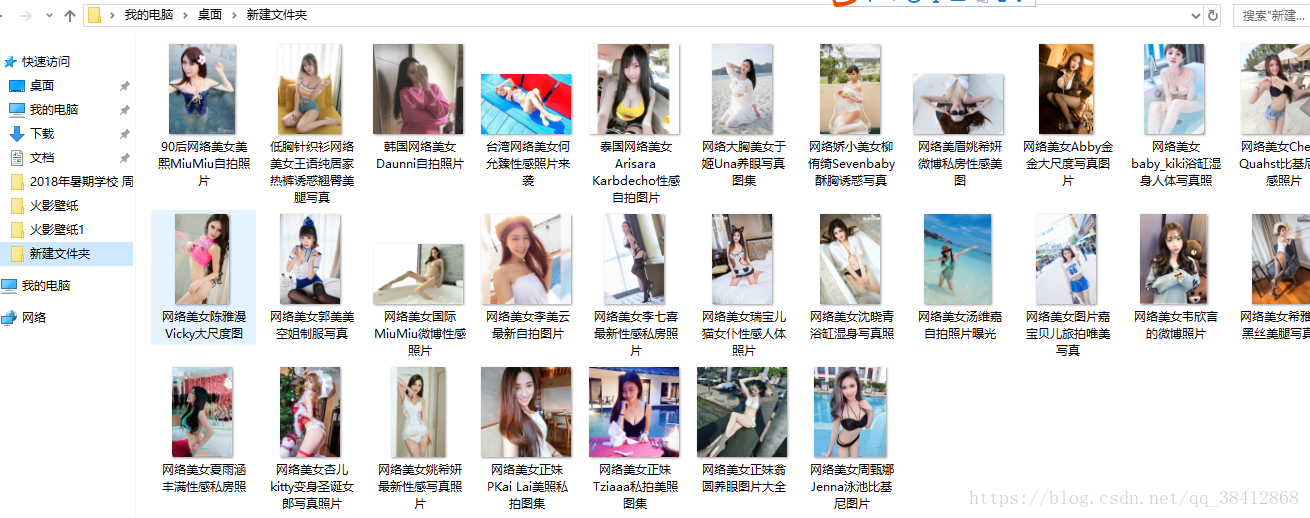
下载情况

感谢你能够认真阅读完这篇文章,希望小编分享的“如何使用Python爬虫爬取网站图片”这篇文章对大家有帮助,同时也希望大家多多支持编程网,关注编程网行业资讯频道,更多相关知识等着你来学习!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












