关于Kafka大数据环境中的应用解析

懒人小魔法师
2024-04-23 23:33

欢迎各位阅读本篇,Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。本篇文章讲述了关于Kafka大数据环境中的应用解析,编程学习网教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!

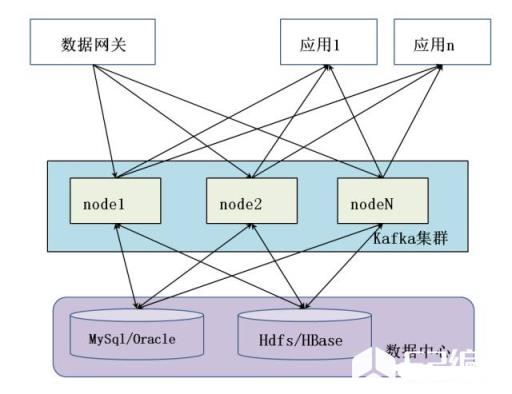
我们生活在一个数据爆炸的时代,数据的巨量增长给我们的业务处理带来了压力,同时巨量的数据也给我们带来了十分可观的财富。随着大数据将各个行业用户、运营商、服务商的数据整合进大数据环境,或用户取用大数据环境中海量的数据,业务平台间的消息处理将变得尤为复杂。如何高效地采集、使用数据,如何减轻各业务系统的压力,也变得越来越突出。在早期的系统实现时,业务比较简单。即便是数据量、业务量比较大,大数据环境也能做出处理。但是随着接入的系统增多,数据量、业务量增大,大数据环境、业务系统都可出现一定的瓶颈。下面我们看几个场景。
场景一:我们开发过一个设备信息挖掘平台。这个平台需要实时将采集互联网关采集到的路由节点的状态信息存入数据中心。通常一个网关一次需要上报几十甚至几百个变化的路由信息。全区有几万个这种互联网关。当信息采集平台将这些变化的数据信息写入或更新到数据库时候,会给数据库代理非常大的压力,甚至可以直接将数据库搞挂掉。这就对我们的数据采集系统提出了很高的要求。如何稳定高效地把消息更新到数据库这一要求摆了出来。
场景二:数据中心处理过的数据需要实时共享给几个不同的机构。我们常采用的方法是将数据批量存放在数据采集机,分支机构定时来采集;或是分支机构通过JDBC、RPC、http或其他机制实时从数据中心获取数据。这两种方式都存在一定的问题,前者在于实时性不足,还牵涉到数据完整性问题;后者在于,当数据量很大的时候,多个分支机构同时读取数据,会对数据中心的造成很大的压力,也造成很大的资源浪费。
为了解决以上场景提出的问题,我们需要这样一个消息系统:
缓冲能力,系统可以提供一个缓冲区,当有大量数据来临时,系统可以将数据可靠的缓冲起来,供后续模块处理;
订阅、分发能力,系统可以接收消息可靠的缓存下来,也可以将可靠缓存的数据发布给使用者。
这就要我们找一个高吞吐的、能满足订阅发布需求的系统。
Kafka是一个分布式的、高吞吐的、基于发布/订阅的消息系统。利用kafka技术可以在廉价PC Server上搭建起大规模的消息系统。Kafka具有消息持久化、高吞吐、分布式、实时、低耦合、多客户端支持、数据可靠等诸多特点,适合在线和离线的消息处理。
使用kafka解决我们上述提到的问题。
互联网关采集到变化的路由信息,通过kafka的producer将归集后的信息批量传入kafka。Kafka按照接收顺序对归集的信息进行缓存,并加入待消费队列。Kafka的consumer读取队列信息,并一定的处理策略,将获取的信息更新到数据库。完成数据到数据中心的存储。
数据中心的数据需要共享时,kafka的producer先从数据中心读取数据,然后传入kafka缓存并加入待消费队列。各分支结构作为数据消费者,启动消费动作,从kafka队列读取数据,并对获取的数据进行处理。
Kafka生产的代码如下:
public void produce(){
//生产消息预处理
produceInfoProcess();
pro.send(ProducerRecord,new Callback(){
@Override
onCompletion() {
if (metadata == null) {
// 发送失败
failedSend();
} else {
//发送成功!"
successedSend();
}
}
});
}消息生产者根据需求,灵活定义produceInfoProcess()方法,对相关数据进行处理。并依据数据发布到kafka的情况,处理回调机制。在数据发送失败时,定义failedSend()方法;当数据发送成功时,定义successedSend()方法。
Kafka消费的代码如下:
public void consumer() {
//配置文件
properties();
//获取当前数据的迭代器
iterator = stream.iterator();
while (iterator.hasNext()) {
//取出消息
MessageAndMetadata next = iterator.next();
messageProcess();
}
}Kafka消费者会和kafka集群建立一个连接。从kafka读取数据,调用messageProcess()方法,对获取的数据灵活处理。
结论
Kafka的高吞吐能力、缓存机制能有效的解决高峰流量冲击问题。实践表明,在未将kafka引入系统前,当互联网关发送的数据量较大时,往往会挂起关系数据库,数据常常丢失。在引入kafka后,更新程序能够结合能力自主处理消息,不会引起数据丢失,关系型数据库的压力波动不会发生过于显著的变化,不会出现数据库挂起锁死现象。
依靠kafka的订阅分发机制,实现了一次发布,各分支依据需求自主订阅的功能。避免了各分支机构直接向数据中心请求数据,或者数据中心依次批量向分支机构传输数据以致实时性不足的情况。kafka提高了实时性,减轻了数据中心的压力,提高了效率。
分享:Kafka相关术语介绍
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
小结:Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。不妨关注编程学习网教育平台,在这个学习知识的天堂中,您肯定会有意想不到的收获的!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341