

自动化测试——selenium(环境部署和元素定位篇)

")
自动化测试——selenium(环境部署和元素定位篇)
文章目录
一、什么是selenium? > 一个web自动化测试工具;二、主流的自动化工具: > QTP:收费 支持(支持web、桌面软件自动化) > selenium:免费,开源 只支持web项目 > Robot frameword: 基于Python扩展关键字驱动自动化工具注意:要是用selenium自动化工具,要先下载安装selenium
一、web自动化环境部署
1.1 selenium安装
安装
在cmd 直接输入 :pip install selenium
卸载:
在cmd输入:pip uninstall selenium
查看:
pip show selenium 或者 pip list
pip 是python中包管理工具(可安装,可卸载,查看python工具),使用pip的时候必须联网
有的输入 pip install selenium 会提示出现 ‘pip’ 不是内部或外部命令,也不是可运行的程序或批处理文件。产生这个原因python环境内部没有 pip 路径,则需要我们收到导入
解决方法:
1、找到我们python工具中的pip所在文件夹,复制其路径
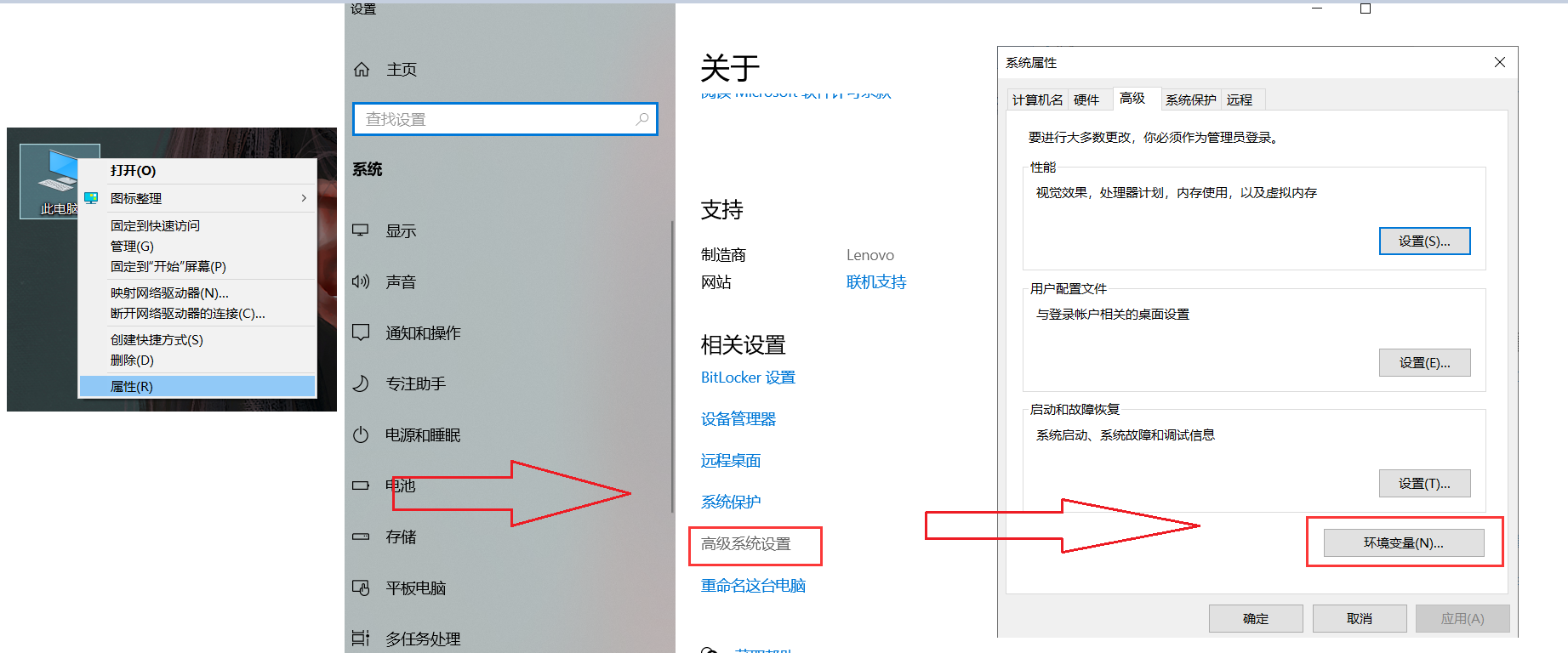
右键,点击我的电脑 选择属性,点击高级系统设置,再点击环境变量
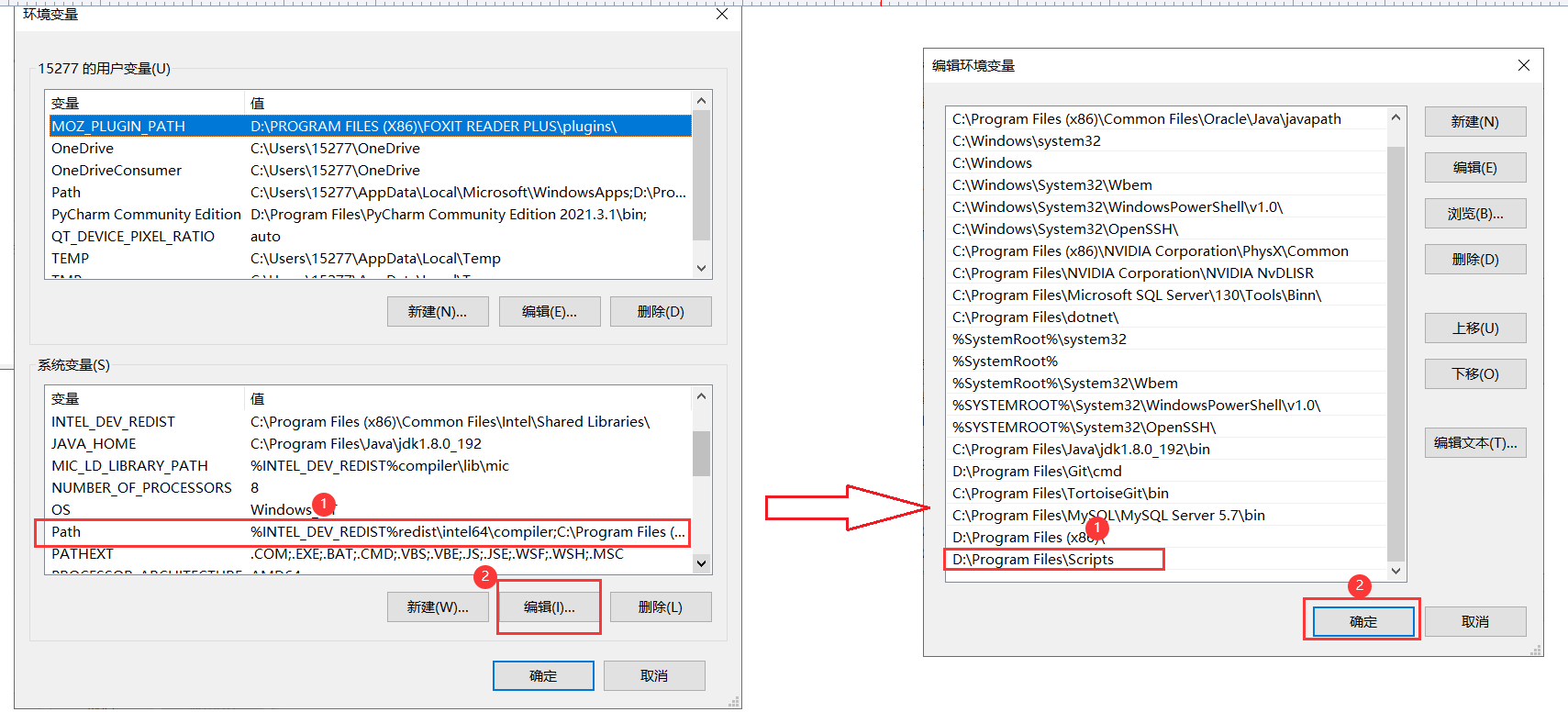
点击环境变量后,找到Path然后编辑,把复制上的路径粘贴进去就可以了。
1.2 浏览器驱动获取
这里有多种浏览器,但是很多浏览器都是用的,谷歌,火狐,Edge中的内核,在这里讲的就是最具有代表性的谷歌浏览器
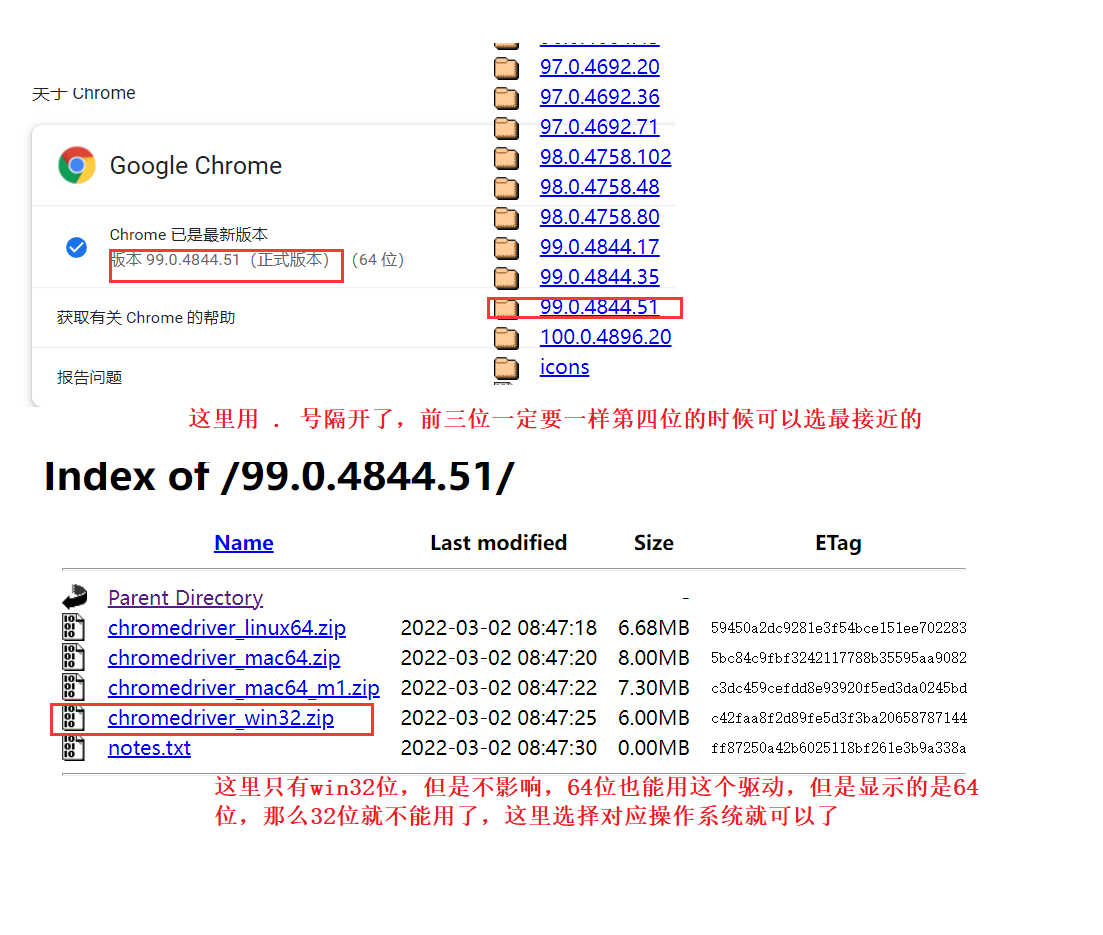
获取谷歌浏览器的驱动地址:http://chromedriver.storage.googleapis.com/index.html1)、获取浏览器的版本一定要选本地电脑谷歌浏览器版本号一样,注意:这里可能有些版本驱动地址没有一模一样的,但是可以选择用 . 号隔开的前三位必须相同,第四位可以选最接近你浏览器版本的那个数. 后面一步的是有,这里只有win32位,但是不影响,64位也能用这个驱动,但是显示的是64位,那么32位就不能用了,这里选择对应操作系统就可以了。
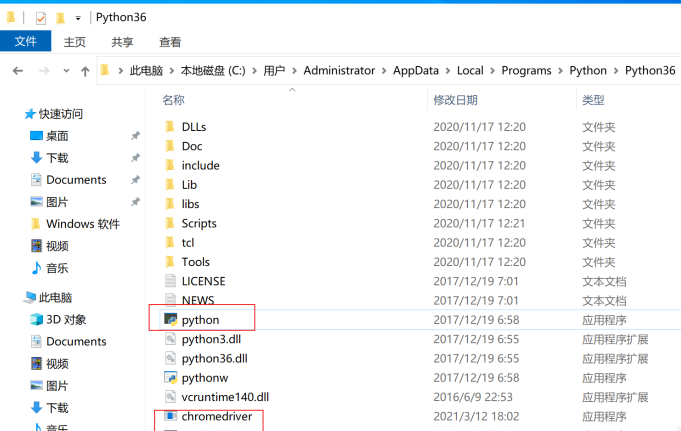
1.3 浏览器驱动安装
下载好驱动压缩包过后,解压得到 chromedriver.exe 驱动程序把他放进Python解释器根目录下,就ok了
二、web自动化的基本代码
步骤:1、导包2、实例化浏览器对象3、打开网页4、时间轴观察效果5、关闭网页"""web 自动化基本代码"""# 1、导包from time import sleepfrom selenium import webdriver# 2、实例化浏览器对象:类名()driver = webdriver.Chrome()# 3、打开网页包含协议头driver.get('https://www.baidu.com/')# 4、时间轴观察效果sleep(5)# 5、关闭网页driver.quit()三、八大元素定位
为什么要使用元素定位?
计算机无法向人一样,所见即所得,因此需要通过元素定位来指定计算机所定位的元素来进行操作
定位工具:
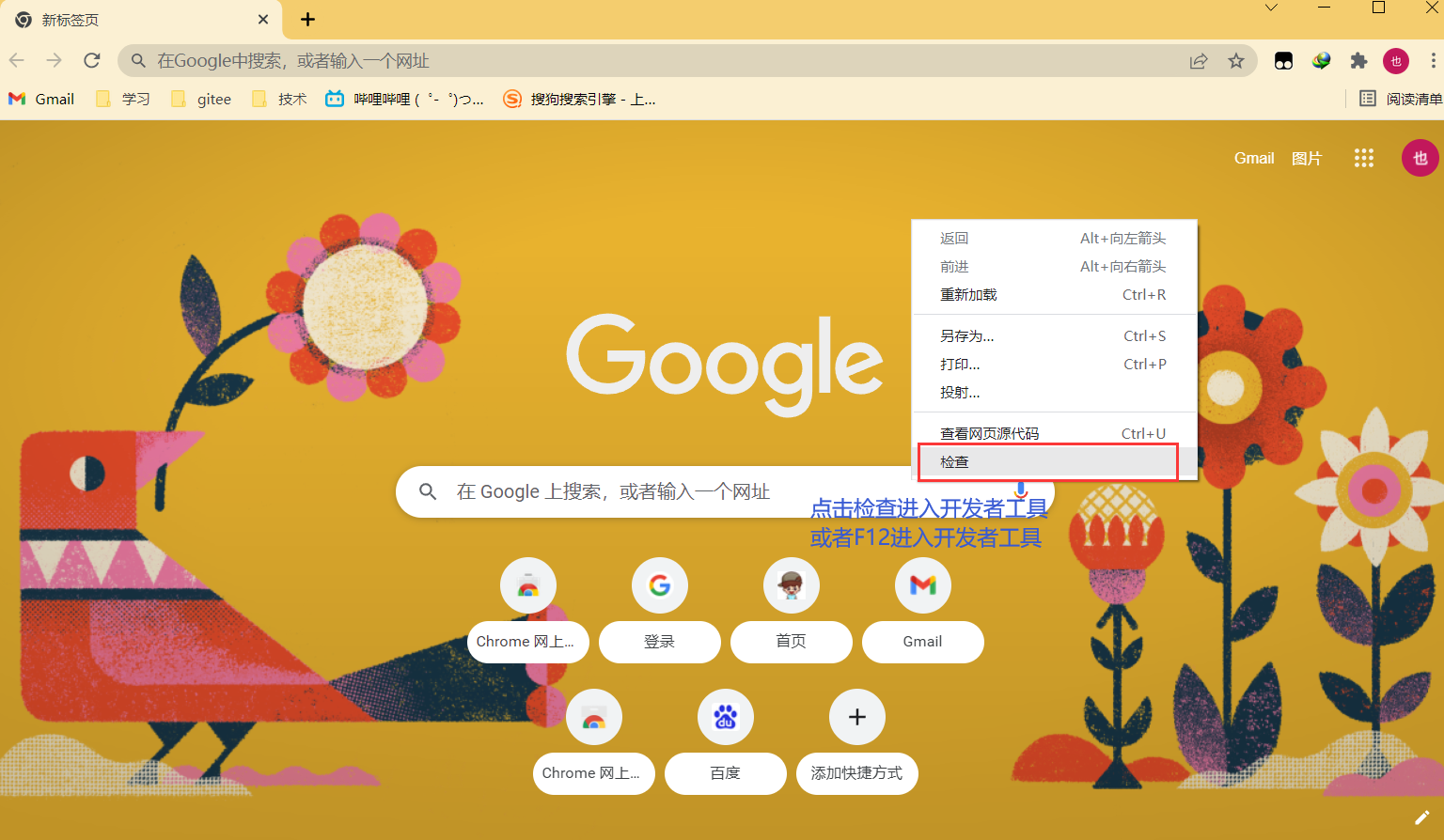
1)、谷歌使用 F12 进入开发者工具
2)、右键点击检查进入开发者工具
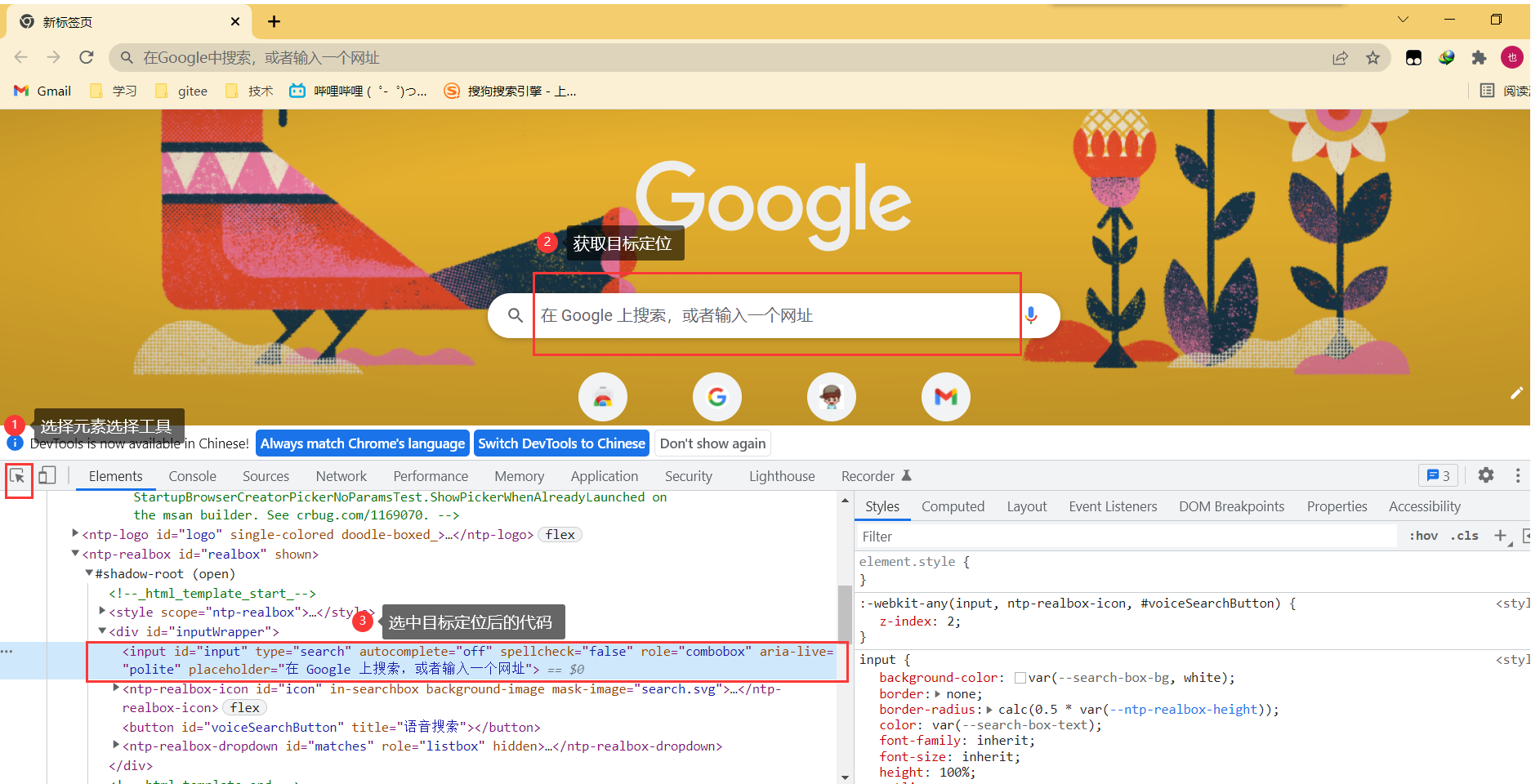
定位元素是依赖于什么?
标签名、属性、层级、路径
定位方式:1、id2、name3、class_name(使用的是class属性进行定位)4、teg_name (标签名称)5、link_text(定位超链接 a 标签)6、partial_link_text(定位超链接 a 标签 包含关系)7、xpath (路径)8、css (元素选择器)注意:这是 selenium 框架中提供的八大元素定位方法,只要能够定位目标元素,用哪一种都无所谓,最常用的是 id ,xpath,css
3.1 id定位方法
说明:通过元素的id属性定位,id一般情况下在当前页面中是唯一。
提示:元素必须要有id属性。
# 语法:find_element_by_id(元素value)1、元素定位:首先调用find_element_by_id(元素value)获得元素定位2、调用send_keys来填写内容3、通过⽬标元素的 id 属性值定位, 由于 id 值一般是唯一的,因此当元素存在 id 属性值时, 优先使用 id 方法定位元素# 元素定位:首先调用find_element_by_id(元素value)获得元素定位# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求driver.find_element_by_id('kw').send_keys('易烊千玺')# 观察效果sleep(3)# 关闭网页driver.quit()3.2 name定位方法
说明:通过元素的name属性来定位, name一般名称为重复
提示:元素必须要有name属性
1、name方法:由于元素的 name 属性值可能存在重复, 必须确定其能够代表⽬标元素唯⼀性之后, ⽅可使⽤2、当页⾯面内有多个元素的特征值是相同的时候, 定位元素的⽅法执⾏时,默认只会获取第⼀个符合要求的特征对应的元素3、因此, 定位元素时需要尽量保证使⽤的特征值能够代表⽬标元素在当前⻚页⾯内的唯⼀性!否则定不了位,添加在第一个定位的位置
name 的定位方法不是唯一的,默认只会获取第⼀个符合要求的特征对应的元素,在确认他是第一个符合要求的特征对应的元素,即可使用。
错误示范:

所以要精准找到在确认他是第一个符合要求的特征对应的元素,方可用这个方法。
driver.find_element_by_name('name的值')# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html')# 需求username = driver.find_element_by_name('userA')username.send_keys('易烊千玺')password = driver.find_element_by_name('passwordA')password.send_keys('12123')# 观察效果sleep(3)# 关闭网页driver.quit()3.3 class_name 方法
说明:通过元素的class属性来定位,class属性一般为多个值。
提示:元素必须要有class属性
注意:
方法名是class_name ,但是我们找的是class属性
如果元素的 class 属性值存在多个值, 在 class_name 方法使用时, 只能使⽤其中的任意⼀一个
# 语法driver.find_element_by_class_name"""class_name 方法:方法名是 class_name, 但要找元素的 class 属性值"""# 1、导包from time import sleepfrom selenium import webdriver# 2、实例化浏览器对象driver = webdriver.Chrome()# 3、打开网页driver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html')tel = driver.find_element_by_class_name('telA')tel.send_keys('18611111111')"""如果元素的 class 属性值存在多个值, 在 class_name ⽅法使用时, 只能使用其中的任意⼀个"""# mail = driver.find_element_by_class_name('emailA dzyxA') # 错误写法# mail = driver.find_element_by_class_name('emailA') # 正确写法mail = driver.find_element_by_class_name('dzyxA') # 正确写法mail.send_keys('123@qq.com')# 4、观察效果sleep(3)# 5、关闭网页driver.quit()3.4 tag_name 方法
说明:通过元素的标签名称来定位,标签名(查看元素时尖括号(<)紧挨着的单词或字母就是标签名) (标签名也就是元素名)
# 语法driver.find_element_by_tag_name("标签名")tag_name 方法:由于存在大量标签,并且重复性更高,因此必须确定其能够代表目标元素唯一性之后,方可以使用;如果页面中存在多个相同标签,默认返回第一个标签元素。
注意:一般标签重复性过高,要精确定位,都不会选择tag_name !
# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html')# 需求username = driver.find_element_by_tag_name('input')username.send_keys('admin')# 观察效果sleep(3)# 关闭网页driver.quit()3.5 link_text
说明:定位超链接标签
注意:1、只能使用精准匹配(a标签的全部文本内容)
2、该⽅法只针对超链接元素(a 标签),并且需要输入超链接的全部⽂本信息
点击方法:元素对象 .click()
# 语法:driver.find_element_by_link_text('文本内容').click()# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求username = driver.find_element_by_link_text('新闻').click()# 观察效果sleep(3)# 关闭网页driver.quit()3.6 partial_link_text
说明:定位超链接标签
注意:
1. 可以使用精准或模糊匹配,如果使用模糊匹配最好使用能代表唯一的关键词
2. 如果有多个值,默认返回第一个值
# 语法driver.find_element_by_partial_link_text('模糊匹配').click()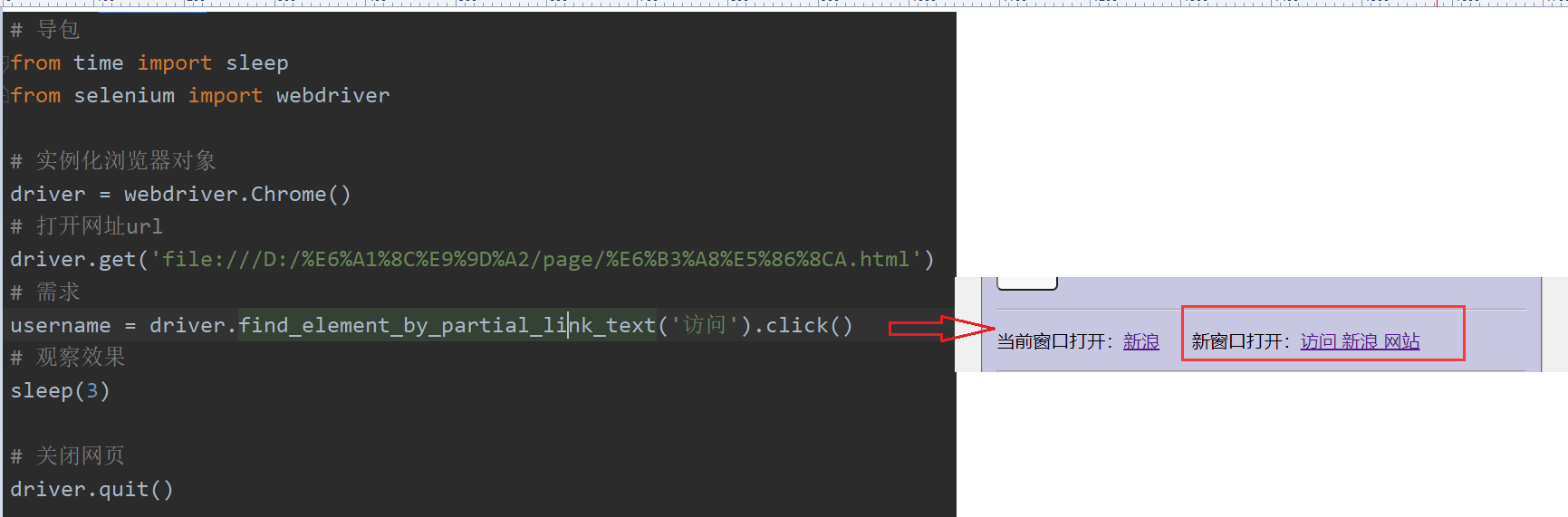
3.7 定位一组元素的方法
通常我们定义元素方法的是 driver.find_element_by_xxx,但是也有 driver.find_elements_by_xxx这种element后面带s,表示执行结果返回的是列表类型,里面的数据是多个元素对象。
说明:1、我们可以获取列表
下标获取对应的目标元素 2、其他元素定位方法也可以实行定义一组元素
3、使用标签名定位操作
# 语法driver.find_elements_by_xxx"""id 列表定位"""# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html')# 需求element = driver.find_elements_by_id('AAA')element[0].send_keys('admin')element[1].send_keys('123456')# 观察效果sleep(3)# 关闭网页driver.quit()"""使用标签名进行定位"""# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('file:///D:/%E6%A1%8C%E9%9D%A2/page/%E6%B3%A8%E5%86%8CA.html')# 需求new_els = driver.find_elements_by_tag_name('input')new_els[0].send_keys('admin')new_els[1].send_keys('123456')# 观察效果sleep(3)# 关闭网页driver.quit()总结:
id,name,class,都是依赖于元素这三个对应的属性,如果元素没有这个三个属性,定位方法不能使用;
link_text, partial_link_text: 只适合超链接定位
tag_name: 只能找页面唯一元素,或者 页面中多个相同元素中的第一个元素
3.8 xpath ☆
说明:Xpath策略有多种,无论使用哪一种策略(方法),定位的方法都是同一个,不同策略只决定方法的参数的写法
# Xpath 定位方法:driver.find_element_by_xpath('Xpath的策略')3.8.1 获取路径策略
什么是Xpath定位:
基于元素的路径定位
Xpath常用的定位策略:
- 绝对路径:从最外层元素到指定元素之间所有经过元素层级的路径 ,绝对路径是以
/html根节点开始,使用/来分割元素层级- 语法:
/html/body/div/fieldset/form/p[1]/input(可能会有多个p标签,所以也是用索引的方式定位,是从一开始以便读者看懂)
- 语法:
绝对路径对页⾯结构要求比较严格,不建议使⽤!!!!
- 相对路径:匹配任意层级的元素,不限制元素的位置 ,相对路径是以
//开始,//跟元素名称,不知元素名称可以使用*代替。- 语法:
//input或者//*
- 语法:
推荐使用相对路径!!
直接获取路径值。
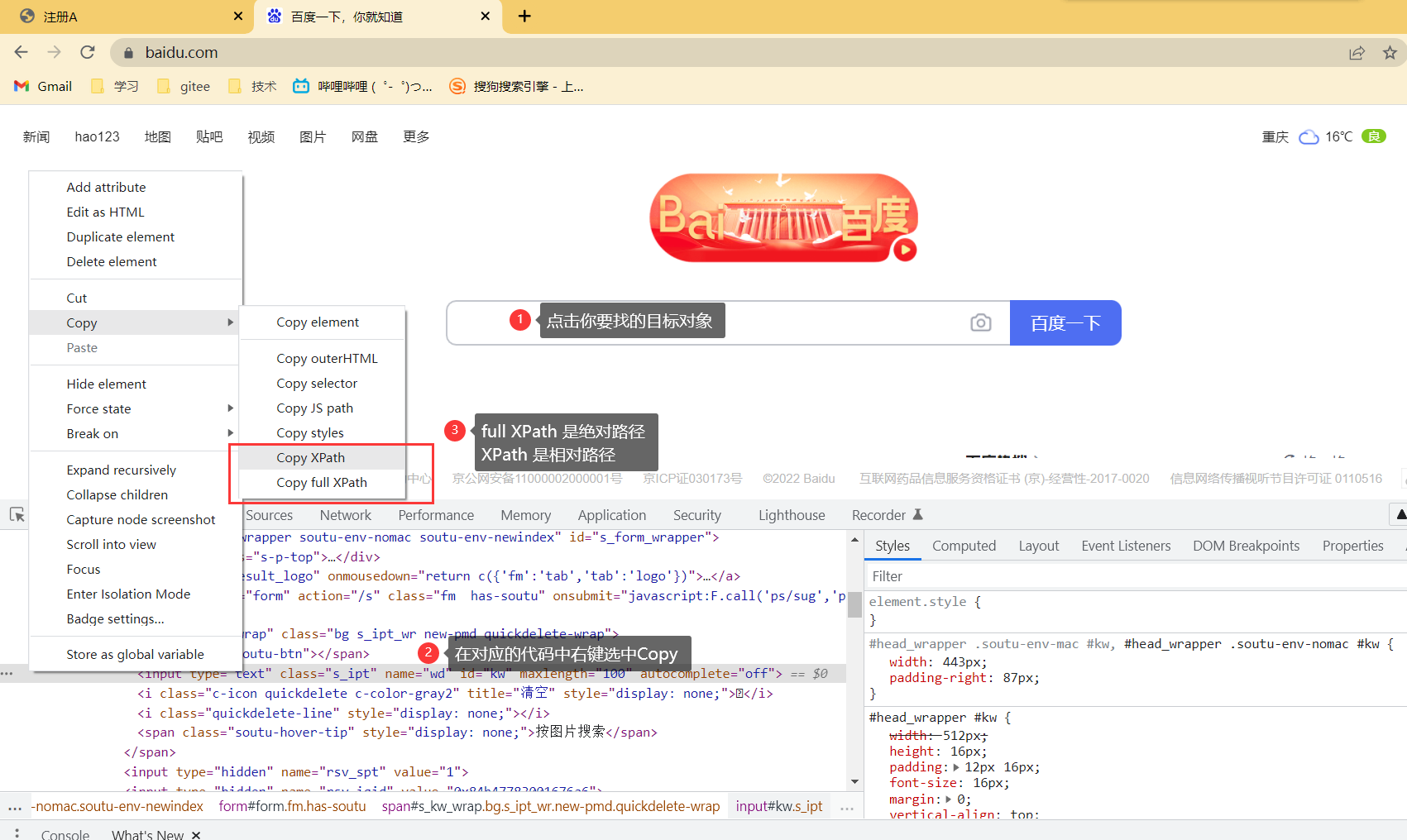
3.8.2 利用元素属性策略
路径结合属性
该方法可以使用目标元素的任意一个属性和属性值(需要保证唯⼀性)
# 语法1://标签名[@属性名='属性值']# 语法2://*[@属性名='属性值']注意: 1、使用 XPath 策略, 需要在浏览器⼯具中根据策略语法, 组装策略值,验证后再放入代码中使用
2、⽬标元素的有些属性和属性值, 可能存在多个相同特征的元素, 需要注意唯一性
路径结合逻辑(多个属性)
解决的是单个属性和属性值无法定位元素唯一性的问题。
# 语法: //*[@属性1="属性值1" and @属性2="属性值2"]注意:多个属性可有由 多个 and 链接,每一个属性前面都要有 @ 开头,可以根据需求使用更多属性值
层级和属性结合策略
目标元素⽆法直接定位, 可以考虑先定位其父层级或祖辈层级, 再获取目标元素
# 语法://*[@id='父级id属性值']/input (⽗层级定位策略/目标元素定位策略)代码实现:
# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求# 1、相对路径ele = driver.find_element_by_xpath('//*[@id="kw"]')ele.send_keys('易烊千玺')# 2、绝对路径driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input').send_keys('易烊千玺')# 3、路径结合属性 语法1://标签名[@属性名='属性值']driver.find_element_by_xpath("//input[@id='kw']").send_keys('易烊千玺')# 语法2: //*[@属性名='属性值']driver.find_element_by_xpath("//*[@id='kw']").send_keys('易烊千玺')# 4、路径结合逻辑(多个属性)driver.find_element_by_xpath("//*[@id='kw' and @name ='wd']").send_keys('易烊千玺')# 5、层级和属性结合策略driver.find_element_by_xpath("//*[@id='s_kw_wrap']/input").send_keys('易烊千玺')# 观察效果sleep(3)# 关闭网页driver.quit()3.8.3 xpath 扩展
1. //*[text()='文本信息'] # 定位文本值等于XXX的元素 提示:一般适合 p标签,a标签 2. //*[contains(@属性,'属性值的部分内容')] # 定位属性包含xxx的元素 【重点】提示:contains为关键字,不可更改。 3. //*[starts-with(@属性,'属性值的开头部分')] # 定位属性以xxx开头的元素提示:starts-with为关键字不可更改# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求# driver.find_element_by_xpath("//*[text()='新闻']").click()# driver.find_element_by_xpath("//*[contains(@autocomplete,'f')]").send_keys('易烊千玺')driver.find_element_by_xpath("//*[starts-with(@autocomplete,'o')]").send_keys('易烊千玺')sleep(3)# 关闭网页driver.quit()3.9 css定位 ☆
通过 css 的选择器语法定位元素
Selenium框架官方推荐使用 css ,因为定位效率高于xpath
CSS一种标记语言,焦点:数据的样式。控制元素的显示样式,就必须先找到元素,在css标记语言中找元素使用css选择器;
css的选择策略也有很多,但是无论选择哪一种选择策略都是用的同一种定位方法
# 方法:driver.find_element_by_css_selector('css策略')常用策略:1、id 选择器语法:#id属性值2、class 选择器语法:.class属性值(如果使⽤具有多个值的 class 属性,则需要传入全部的属性值 语法:[class="全部属性值"])3、属性选择器语法1:[属性名=“属性值”]语法2:标签名[属性名=“属性值”]4、标签选择器语法:标签名 如input,button5、层级选择器父子层级关系:父层级策略 > 子层级策略 (也可以使用空格连接上下层级策略)祖辈后代层级关系:祖辈策略 后代策略提示:>与空格的区别,大于号必须为子元素,空格则不用。# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求# 语法id:#id属性值driver.find_element_by_css_selector('#kw').send_keys('易烊千玺')# 语法class:.class属性值 如: '.talA'# 语法class有多个属性值的时候:[class="全部属性值"]driver.find_element_by_css_selector('[class="s_ipt"]').send_keys('易烊千玺')# 语法属性选择器driver.find_element_by_css_selector('input[id="kw"]').send_keys('易烊千玺')driver.find_element_by_css_selector('[name="wd"]').send_keys('易烊千玺')# 语法层级选择器# 父层级策略 > 子层级策略driver.find_element_by_css_selector('#s_kw_wrap>input').send_keys('易烊千玺')driver.find_element_by_css_selector('#form input').send_keys('易烊千玺')sleep(3)# 关闭网页driver.quit()3.9.1 css的扩展方法 ☆
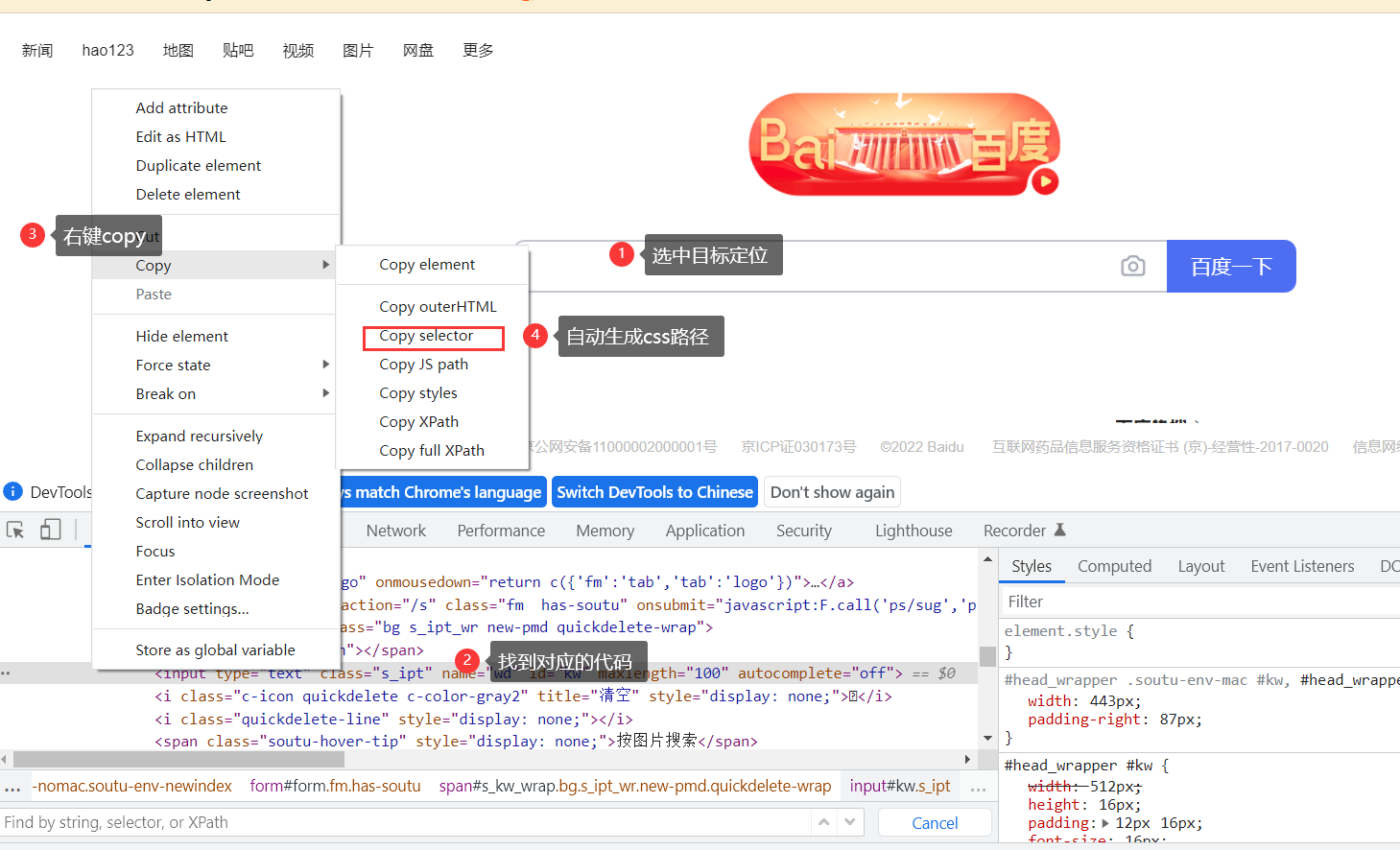
1. [属性^='开头的字母'] # 获取指定属性以指定字母开头的元素2. [属性$='结束的字母'] # 获取指定属性以指定字母结束的元素3. [属性*='包含的字母'] # 获取指定属性包含指定字母的元素# 导包from time import sleepfrom selenium import webdriver# 实例化浏览器对象driver = webdriver.Chrome()# 打开网址urldriver.get('https://www.baidu.com/')# 需求# 语法1:[属性^='开头的字母'] # 获取指定属性以指定字母开头的元素driver.find_element_by_css_selector("[class^='s_i']").send_keys('易烊千玺')# 语法2:[属性$='结束的字母'] # 获取指定属性以指定字母结束的元素driver.find_element_by_css_selector("[class$='pt']").send_keys('易烊千玺')# 语法3:[属性*='包含的字母'] # 获取指定属性包含指定字母的元素driver.find_element_by_css_selector("[autocomplete*='f']").send_keys('易烊千玺')sleep(3)# 关闭网页driver.quit()也可以直接自动生成css的路径,跟xpath步骤一样:
这篇帖子就到这里了,这里只介绍了selenium中的八大元素定位,后面还有很多内容,就留着下一篇帖子见面吧😁😁😁铁汁们,觉得笔者写的不错的可以点个赞哟❤🧡💛💚💙💜🤎🖤🤍💟,收藏关注呗,你们支持就是我写博客最大的动力!!!!
来源地址:https://blog.csdn.net/qq_54219272/article/details/123310772
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












