

MySQL数据库和表的基本操作


文章目录
一、数据库的基础知识
背景知识
MySQL是一个客户端服务器结构的程序
主动发送数据的这一方,客户端(client)
被动接受数据的这一方,服务器(server)
客户端给服务器发送的数据叫做: 请求(request)
服务器给客户端发送的数据叫做: 响应(response)
客户端和服务器之间是通过网络进行通信的
服务器是存储数据的主体(数据是存储在主机的硬盘上的)
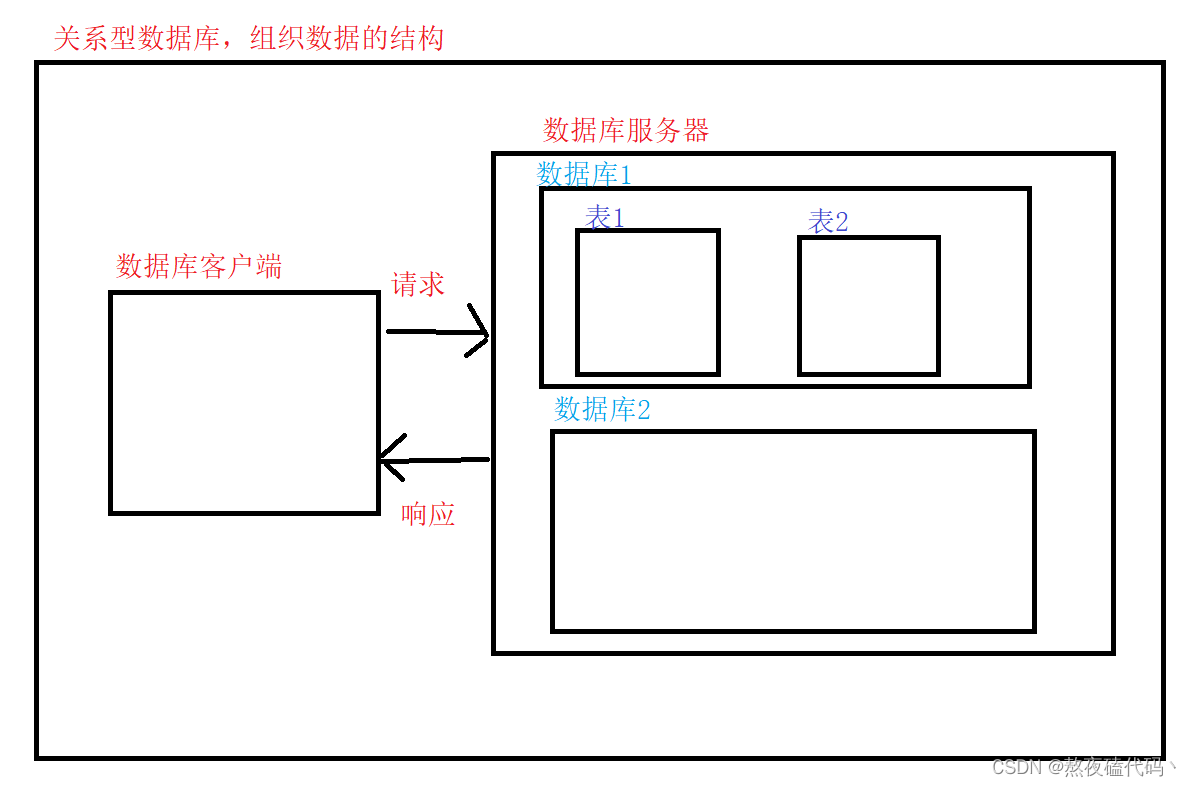
服务器当中存放多个数据库,每个数据库当中又可以存放多张表,每张表中又存储各自的数据
数据库能够正常使用的前提条件是客户端与服务器是建立连接的
数据库的基本操作
1.显示所有数据库
show databases;这里databases后面是加s的,因为是所有数据库

2.创建数据库
create database [if not exists] DB_name [charset charset_name] [ collate collate_name]这里中括号所包含的都是可加可不加的,自己按具体情况选择。

这里我们看到Query OK,证明我们成功创建了一个名为test的数据库。

当我们再次创建test数据库时,系统报了一个错误(database exists),证明这个数据库已经存在。这时候我们就可以加一个判断( if not exists)

这里我们我们再次创建这个重复的数据库,发现系统并没有报错,而是告诉了一个警告。我们可以去看一下这个警告信息
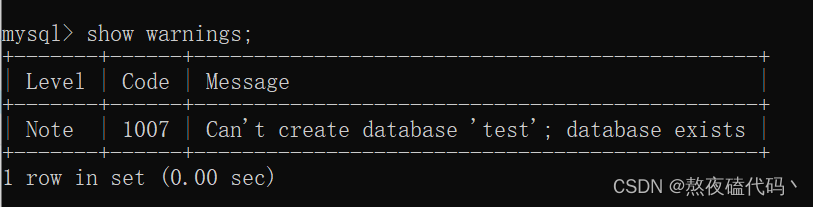
这里我们可以发现报的是(database exists)的警告。这里大家就要注意了,错误和警告不是一个重量级的,在适当的时候我们可以加上(if not exists)来避免这些错误的出现。
CHARACTER SET: 指定数据库采用的字符集
字符集指的是某个范围字符的编码规则
比如utf8字符集对于所有中文汉字采用3个字节来表示(编码),所以我们称utf8为一种字符集。
这里的范围就是指所有的中文汉字
编码规则就是指 都采用3个字节来表示一个汉字
2.比如ASCII字符集对于所有英文字母采用1个字节来表示(编码),所以我们称ASCII为一种字符集。
这里的范围就是指所有的英文字母
编码规则就是指 都采用1个字节来表示一个字母
Mysql中的utf8是伪utf8,当有些不满足时,可以替换为更全面的utf8bm4

COLLATE通常是和数据编码(CHARSET)相关的,一般来说每种CHARSET都有多种它所支持的COLLATE,并且每种CHARSET都指定一种COLLATE为默认值。例如Latin1编码的默认COLLATE为latin1_swedish_ci,GBK编码的默认COLLATE为gbk_chinese_ci,utf8mb4编码的默认值为utf8mb4_general_ci。

3.使用数据库
当我们要对一个数据库进行操作时,那么这时我们得使用这个数据库。
use DB_name;
4.删除数据库
删除数据库是一件十分危险的事情,大家在进行删库的时候一定要慎重再慎重
drop database DB_name;
但是如果删的库,服务器中不存在,那么就会报错误
这时我们可以在数据库名前面加一判断
drop database [if exists] test;这时我们可以发现,即使该数据库服务器中不存在,只是报了一个警告

二、数据类型
我们在学习MySQL数据类型时,会发现有些数据类型设计的并不好,和java有一些区别,这是因为MySQL这里语言比较久远了,那时还没有Java这样语言,那个时候能够设计出来这样已经很厉害啦。
字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| varchar(size) | 0 - 65535 字节 | 可变长度字符串 | String |
| text | 0 - 65535 字节 | 长文本数据 | String |
| mediumtext | 0 -16777215 字节 | 中等长度文本数据 | String |
| blod | 0 - 65535 字节 | 二进制长文本数据 | byte[ ] |
varchar(size):最常用的字符串的类型,带一个参数参数,这里表示存储的最大限度,varchar(50)表示这列最多存50个字符,至于这个size设置为多少,根据实际需求来制定,并不是size订多少就直接分配多少,而是动态分配,但是最大不会超过size。
text,mediumtext:适用于比较长的字符串,比较存储一篇长文等,应用较少
bold:主要是用来存储二进制的数据。
数值类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| bit(M) | M指定位数,默认为1 | 二进制数 | 常用boolean对应bit |
| tinyint | 1字节 | byte | |
| smallint | 2字节 | short | |
| int | 4字节 | Integer | |
| bigint | 8字节 | Long | |
| float(M,D) | 4字节 | 单精度,M为长度,D为小数位数,会丢失精度 | Float |
| double(M,D) | 8字节 | 双精度,M为长度,D为小数位数,会丢失精度 | Double |
| decimal(M,D) | M/D最大值+2 | 双精度,M为长度,D为小数位数,精确数值 | BigDecimal |
| numeric(M,D) | M/D最大值+2 | 双精度,M为长度,D为小数位数,精确数值 | BigDecimal |
数值类型可以指定为无符号(unsigned),不去取负数。
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型。
float,double:并不适合用来需要精确存储的数据,因为IEEE 754标准,数据在内存中的存储就决定了无法精确表示数据。
decimal: 可以精确的表示浮点数,因为它牺牲了空间和运算速度,换来的是更精确的表示方法。
最常用的数值类型: int,double,decimal
日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| datetime | 8字节 | 范围从1000-9999年,不会进行检索及转换 | java.util.Date、java.sql.Timestamp |
| timestamp | 4字节 | 范围从1970 - 2038年,自动检索当前时区并转换 | java.util.Date、java.sql.Timestamp |
在表中插入时的类型为: ‘xxxx-xx-xx xx:xx:xx’
timestamp: 这个类型有点危险,将在2038年耗尽
三、表的基本操作
在进行任何数据库的表时,都需要先使用该数据库
use DB_name;创建表
create table table_name(filed1 type [comment xx},filed2 type [comment xx},filed3 type [comment xx});comment为可增加解释字段
在这里我们以创建一个学生表为例:
create table student( id int comment '学号', name varchar(50), age int );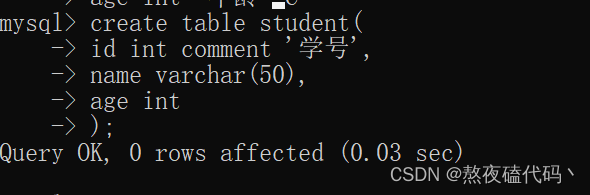
查看表结构
desc table_name;desc的全拼为describle.
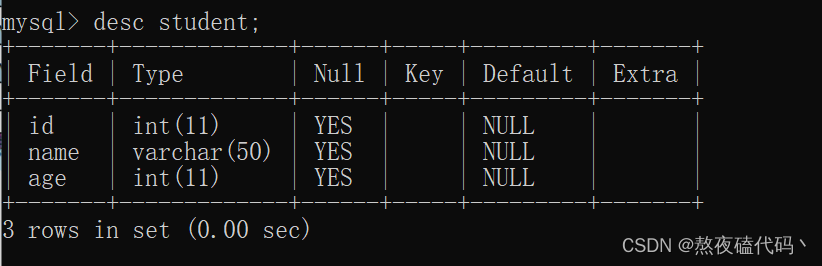
这里我们可以查看表的结构。
查看所有表
可以查看当前数据库下的所有表
show tables;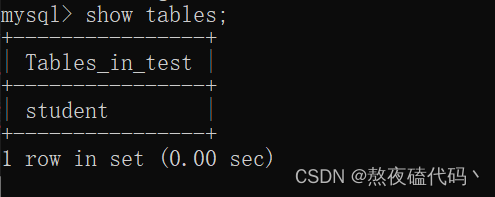
因为当前数据库我们只创建了一个student的表。
删除表
删除表结构和删除数据库操作都是非常危险的使用的时候都要小心再小心
drop table table_name;
来源地址:https://blog.csdn.net/buhuisuanfa/article/details/127713348
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341




![[mysql]mysql8修改root密码](https://static.528045.com/imgs/22.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









