

Wormhole大数据流式处理平台的设计思想是怎样的

本篇文章为大家展示了Wormhole大数据流式处理平台的设计思想是怎样的,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
导读:互联网的迅猛发展使得数据不再昂贵,而如何从数据中更快速获取价值变得日益重要,因此,数据实时化成为了一个大趋势。越来越多的业务场景需要实时分析,以极低的延迟来分析实时数据并给出分析结果,从而提高业务效率,带来更高价值。流式处理作为实时处理的一种重要手段,正在因数据实时化的发展而蓬勃发展。本文是敏捷大数据(Agile BigData)背景下的实时流式处理平台Wormhole的开篇介绍:Wormhole具体是一个怎样的平台?
一、Wormhole背景介绍
在流式计算领域,越来越多成熟的技术框架出现在开源世界,如Storm、Heron、Spark、Samza、Flink、Beam等。流式技术也逐步进化发展,支持流上丰富计算语法(类SQL)、支持at least once或exactly once语义、支持高可靠高可用、支持高吞吐低延迟、支持基于事件时间计算、支持统一整合接入抽象等,这些都从不可能变为可能。
然而,虽然流式处理的技术已经很丰富,流式处理在企业中的实施仍然存在较大难度,主要原因是成本高,需求上线周期长等,而产生这样问题的原因又分两个方面,一是企业组织结构,二是技术。
传统数据仓库和BI的组织结构都是集中相关技术人员成立独立大数据部门,各个业务部门向其提需求,做定制化开发。
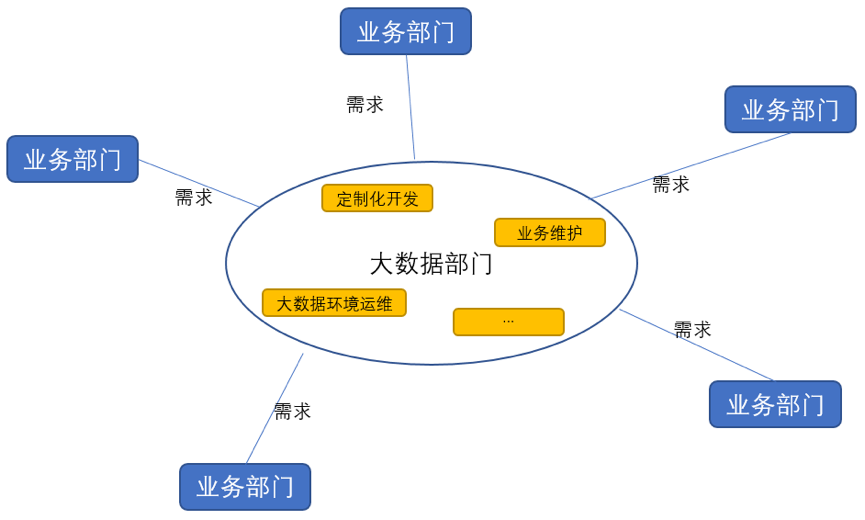
(企业组织结构)
如上图,大数据部门不仅仅做大数据环境运维,还做定制化开发和线上业务维护。恰恰这两点会消耗大量的人力,也增加了管理和沟通成本。举一个需求开发的例子,如下图:
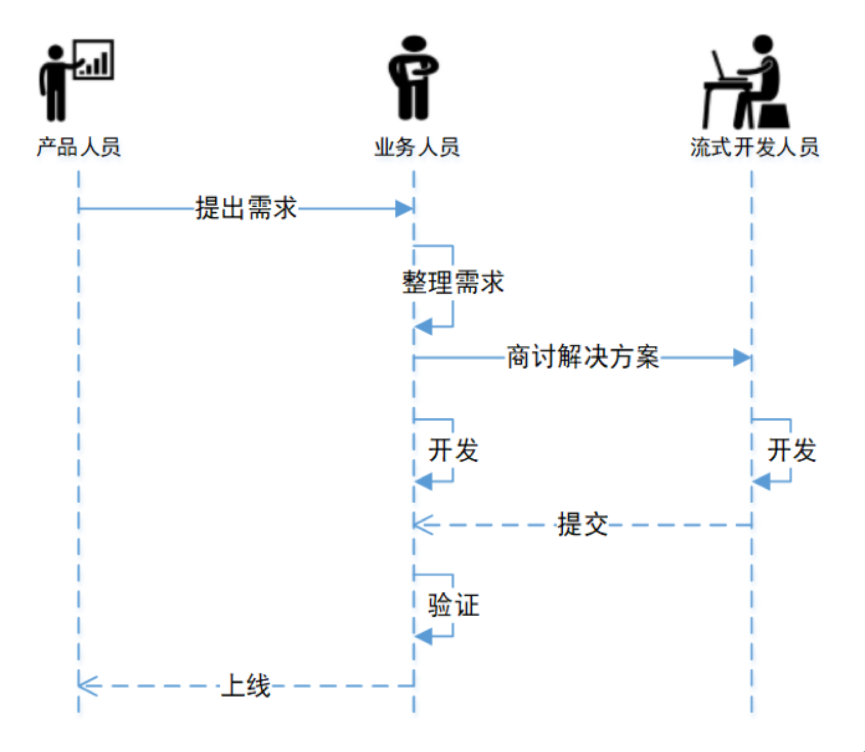
(需求开发流程)
上图是企业普遍使用的一个开发流程,这里边就反应出一些问题:
人力成本高
从此图可以看出,至少需要3个角色的人员才能完成一个需求,而且流式开发人员要花很多时间了解需求、业务、表结构等等。
上线周期长、效率低
所有需求都是由产品人员提出,由业务人员分析,然后与流式开发人员一起设计开发完成,且需要大量时间测试及验证结果。
复用低
在需求中,有很多业务是类似的,但因业务和定制化问题,所以无法很好的做到代码复用,导致重复开发比较多。
业务维护成本高
当上线的需求有变化时,就要在原有代码的基础上改造,流式处理开发人员也需要再一次了解业务流程、表结构等等,还是需要很多的人力资源,并且周期也很长,同时改动会增加出问题的概率。
大量消耗资源
为了功能隔离和降低维护难度,每个定制化功能都要启动一个流式应用,无法复用,需要占用大量硬件资源。
目前流式处理的种种问题很大的制约了企业实时大数据的发展,各个公司都在寻找一条更轻量的解决之道。我们根据多年在实时大数据项目中的实践和经验积累,自主研发了流式处理平台——Wormhole,很大程度上解决了上述各类问题。下面我们来介绍一下Wormhole的具体情况。
二、Wormhole是什么
Wormhole是一个面向实时大数据项目实施者的流式处理平台,致力于统一并简化大数据开发和管理,尤其针对典型流式实时/准实时数据处理应用场景,屏蔽了底层技术细节,提供了极低的开发门槛。项目实施者只需简单配置及编写SQL即可支持大部分业务场景,使得大数据业务系统开发和管理变得更加轻量、可控可靠。
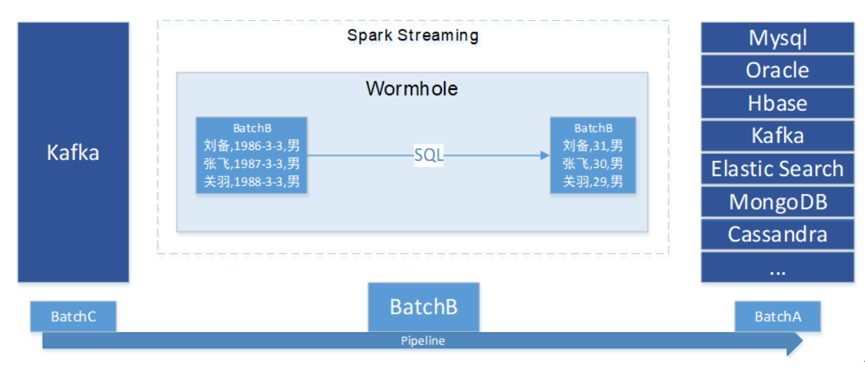
(Wormhole数据处理样例)
Wormhole主要基于Spark技术,实现了基于SQL的流上数据处理和异构系统幂等写入等相关功能。如上图所示,Wormhole接入流上的数据,然后将数据中的出生日期通过用户编写的SQL处理为年龄,写入到另外一个存储系统中。
Wormhole通过技术手段实现基于SQL的流式处理方案,大大降低了流式处理的技术门槛;同时通过平台化和可视化等实现了职能的变化,减少了整个需求生命周期的参与角色数量,精炼了整个开发过程,进而缩短了开发周期,也减少了开发和维护成本。
三、Wormhole设计目标
3.1 设计目标
基于敏捷大数据的思想,Wormhole的设计目标如下:
平台化/组件化
通过平台化支持,组件化组装实施,可以快速对原型进行验证,和需求方形成反馈闭环快速迭代
标准化
对数据格式进行标准化,达到通用效果,减少数据格式化和维护的成本
配置化/可视化
用户可视化配置、部署、管理、监控,降低大数据产品开发门槛,确保高质量产出
低延迟/高性能/高可用
根据实时性的要求,流式处理要求更低的延迟,并且要求更高的吞吐量,以及容错能力,保证系统7*24正常运行
自助化/自动化
让企业从数据中心化转型为平台服务化,让每个数据从业者都能够有更多的自助服务,并释放数据处理能力,系统替代人工完成重复低级的工作,让从业者回归数据和业务本质
3.2 效果体现
Wormhole平台的建设带来的效果主要体现在以下几方面:
组织结构更合理:
如下图,大数据相关部门不再做定制化开发和业务维护,而是更专注平台化和大数据环境的稳定,大大减少了人力资源的浪费。
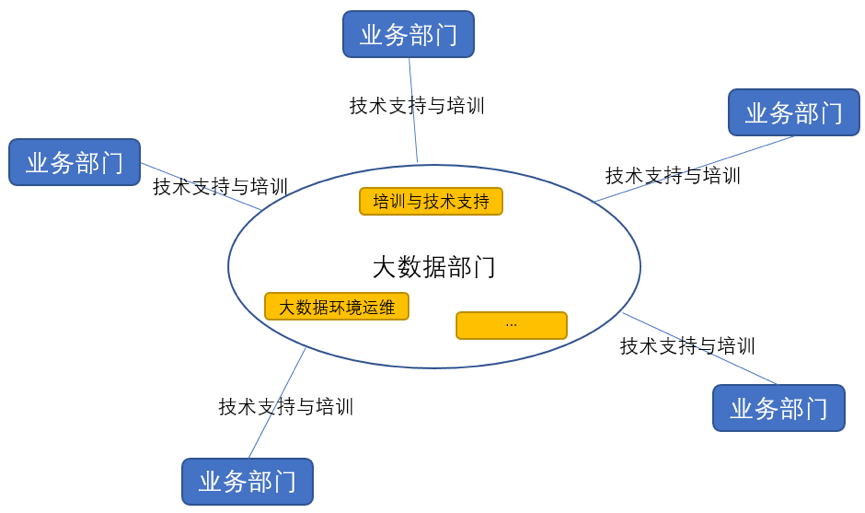
(基于Wormhole的组织结构)
降低了流式处理开发的技术门槛:
流式处理的开发模式变为了业务人员通过可视化配置和编写SQL即可完成80%以上的业务场景,不再需要对流式处理技术有很深的理解
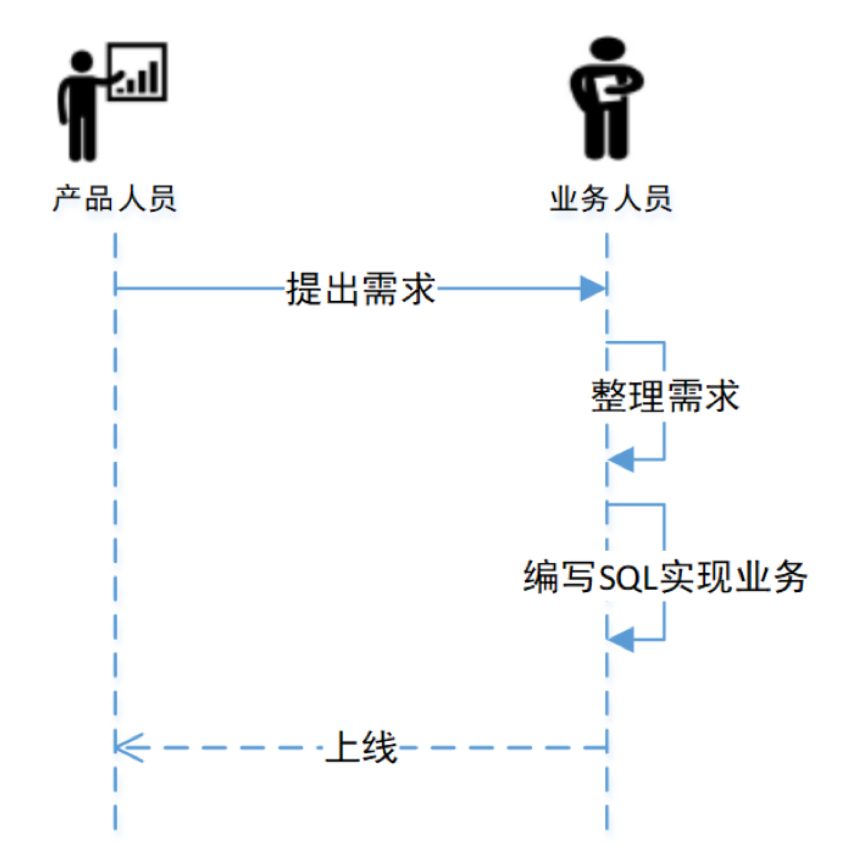
缩短了需求上线周期:
如下图所示基于Wormhole的需求开发流程,一个需求从提出到上线只需要产品人员和业务人员,大幅降低了沟通和学习成本,进而大大缩短了需求开发上线周期。
四、Wormhole设计规范
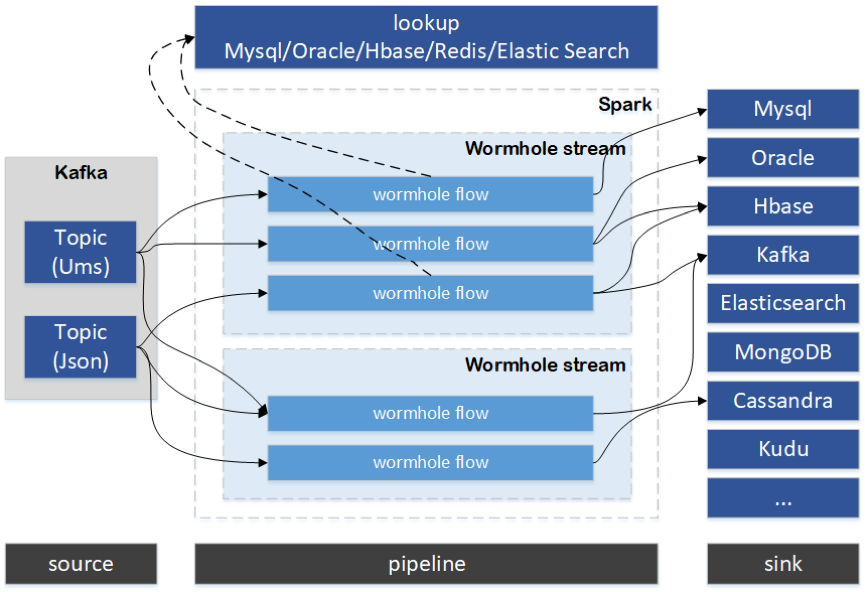
(Wormhole流程设计图)
上图是Wormhole的一个设计介绍,体现了流式处理的从输入到输出的过程,在这个过程中,Wormhole定义新的概念,将整个流式处理进行了标准化,将定制化的流式计算变为标准化的流式处理,并从三个纬度进行了高度抽象。
统一数据逻辑表命名空间——Namespace
Namespace:数据的“IP”,通过7层结构唯一定位数据对应的物理位置,即
[Data System].[Instance].[Database].[Table].[Table Version]. [Database Partition].[Table Partition]

1)统一通用流消息协议——UMS
UMS是Wormhole定义的流消息协议规范
UMS试图抽象统一所有结构化消息
UMS自身携带结构化数据Schema信息,方便数据处理
UMS支持每一个消息中存在一份Schema信息及多条数据信息,这样,在存在多条数据时可以降低数据大小,提高处理效率
说明:

protocol-type目前支持data_increment_data(增量数据)和data_initial_data(初始化全量数据)
schema-namespace指定数据对应的namespace
schema-fields描述每个字段的名称、类型、是否可空。ums_id_代表记录id,要求保证递增;ums_op_代表数据操作(i:插入;u:更新;d:删除);ums_ts_代表数据更新时间
payload-tuple指一条记录的内容,与schema-fields一一对应
注:在Wormhole_v0.4.0版本后,应社区需求,支持用户自定义半结构化JSON格式
2)统一数据计算逻辑管道——Flow
Flow是Wormhole抽象的流式处理逻辑管道
Flow由Source Namespace、Sink Namespace和处理逻辑构成
Flow支持UMS和自定义JSON两种消息协议
Flow支持Event和Revision两种Sink写入模式
Flow统一计算逻辑标准(SQL/UDF/接口扩展)

(Flow)
说明:上图中蓝色框和箭头组成了一个Flow,首先从TopicA中读取Namespace1 (SourceNamespace)的数据,数据协议为UMS或者自定义JSON,然后处理用户配置好的数据处理逻辑,输出到Namespace2 (SinkNameSpace)对应的数据系统中,写入支持insertOnly和幂等(对同key且不同状态的数据保证最终一致性)。
作为一个实时大数据流式处理平台,Wormhole的设计目标和设计规范最终都是为流上处理数据而服务。
上述内容就是Wormhole大数据流式处理平台的设计思想是怎样的,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












