

nodeJs爬虫获取数据简单实现代码

短信预约 -IT技能 免费直播动态提醒

本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
效果图:
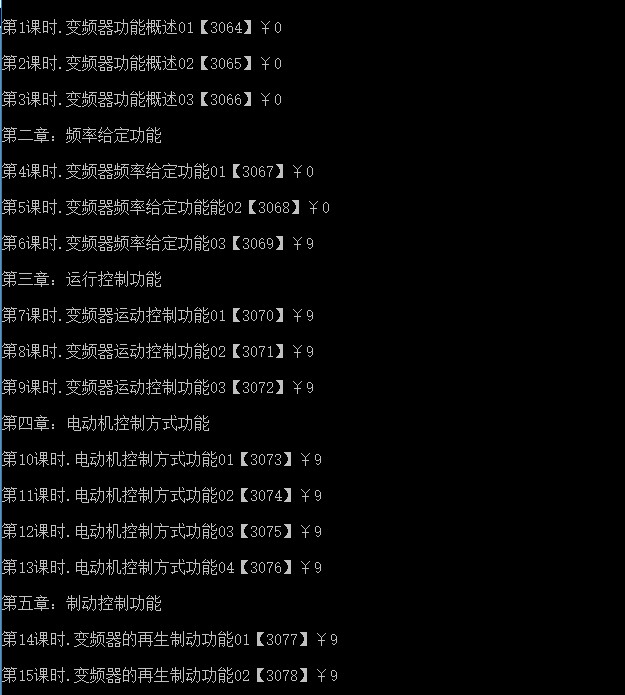
以上就是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341











