

Z-Score标准化(z-score normalization)

")
文章目录
前言
标准化方法是一种最为常见的量纲化处理方式
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
z-score标准化是将数据按比例缩放,使之落入一个特定区间。
一、z-score normalization是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、计算Z-Score标准化
1.标准差
标准差(Standard Deviation) ,数学术语,是离均差平方的算术平均数(即:方差)的算术平方根,用σ表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。
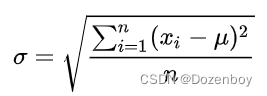
2.Z-Score标准化
z-score normalization后,所有特征的均值为0,标准差为1。
要实现z-score normalization,调整输入值如下公式所示:
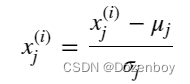
其中j选择X矩阵中的一个特征或一列。μj为特征(j)所有值的均值,σj为特征(j)的标准差。
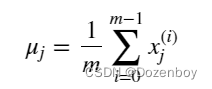
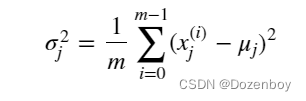
代码如下(示例):
def zscore_normalize_features(X): """ X (ndarray): Shape (m,n) input data, m examples, n features X_norm (ndarray): Shape (m,n) input normalized by column mu (ndarray): Shape (n,) mean of each feature sigma (ndarray): Shape (n,) standard deviation of each feature """ # find the mean of each column/feature mu = np.mean(X, axis=0) # mu will have shape (n,) # find the standard deviation of each column/feature sigma = np.std(X, axis=0) # sigma will have shape (n,) # element-wise, subtract mu for that column from each example, divide by std for that column X_norm = (X - mu) / sigma return (X_norm, mu, sigma) #check our work#from sklearn.preprocessing import scale#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)代码来源于吴恩达老师机器学习
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
来源地址:https://blog.csdn.net/weixin_51382471/article/details/128022317
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












