

数学建模—聚类(matlab、spss)K均值 Q型聚类 R型聚类

短信预约 -IT技能 免费直播动态提醒
文章目录
聚类三种方法: 【说明】 1、三种方式输入矩阵行为个案,列为变量 量纲不同需要预处理,一般使用zscore() zscore()标准化为对每一列操作减去均值除以标准差
2、k均值需要自己确定k取值。Q、R型聚类需要运行完以后再确定选择
一、K均值
- matlab实现
%% 数据预处理%如果量纲不同,需要进行预处理,数据的列为属性,行为个案clear;clc;close all;data_mean=xlsread('data.xlsx','mean','B3:L16'); %读入数据data_mean=zscore(data_mean);%% 判断kmeans的k值%第二个参数 可以自定义,'linkage','gmdistribution','kmeans'% eva = evalclusters(data_mean,'kmeans','CalinskiHarabasz','KList',[1:10]) %判断聚类k值 越大越好% hold on;% eva = evalclusters(data_mean,'kmeans','DaviesBouldin','KList',[1:10]) %判断聚类k值 越小越好% hold on;%eva = evalclusters(data_mean,'kmeans','gap','KList',[1:10]) %判断聚类k值% hold on;eva = evalclusters(data_mean,'kmeans','silhouette','KList',[1:10]) %判断聚类k值 越大越好% hold on;plot(eva)%% 根据第一步确定分类[idx,C,sumd,d]=kmeans(data_mean,3)%idx表示分类的组别,C表示簇质心的距离,其中第 j 行是簇 j 的质心。%sumd簇内的点到质心距离的总和,以数值列向量形式返回,d表示从每个点到每个质心的距离,以数值矩阵形式返回%% 若维度为2维可以画散点图%catter plot by group,This MATLAB function creates a scatter plot of x and y, grouped by g.%gscatter(x,y,g)%由于这个例子数据维数太高没法可视化,提取数据的前两个维度,方便演示figuregscatter(data_mean(:,1),data_mean(:,2),idx,'bgm')%画散点hold onplot(C(:,1),C(:,2),'kx')%画质心legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')%添加标签%3维数据figurescatter3(data_mean(:,1),data_mean(:,2),data_mean(:,3),50,idx,'.')% plot(C(:,1),C(:,2),'kx')%画质心% legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')%添加标签- SPSS实现(默认使用kmeans++)
数据预处理:
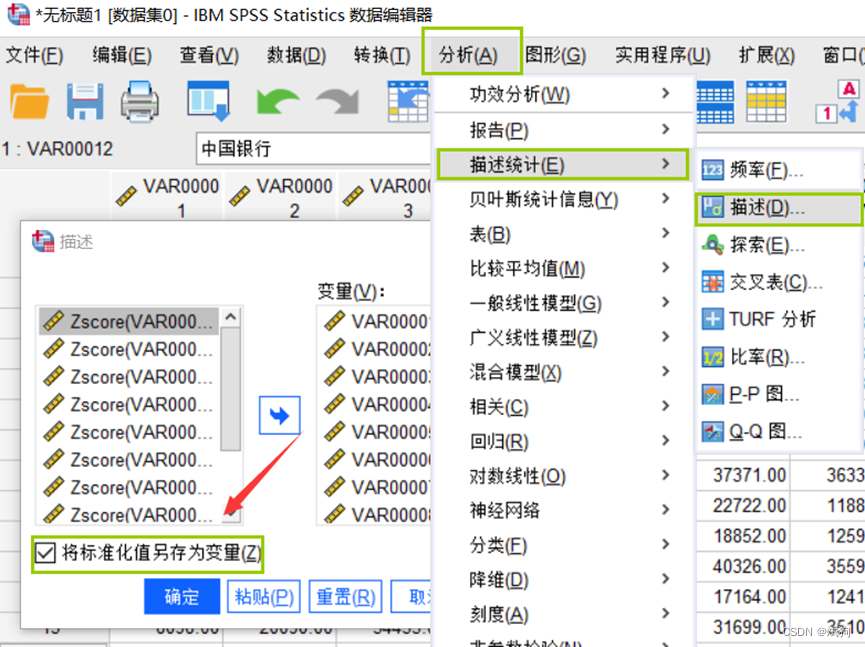
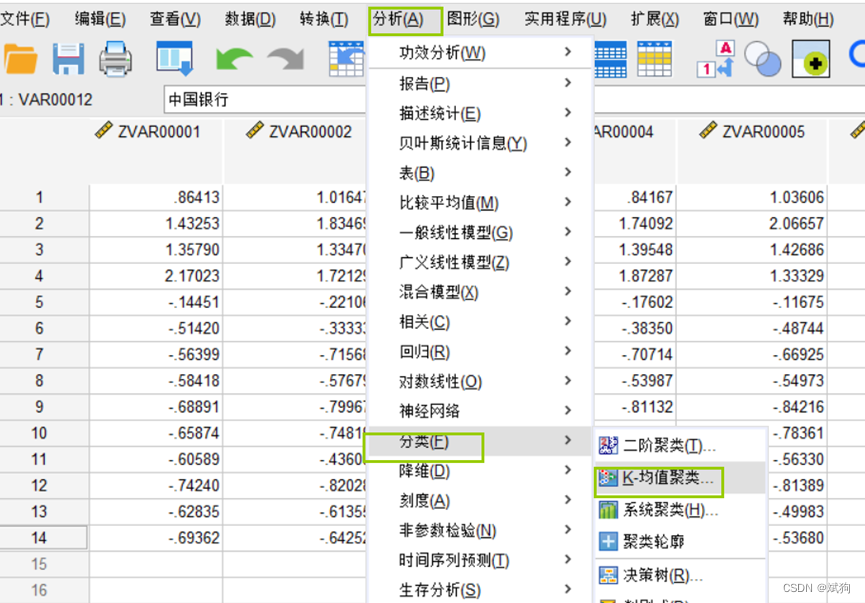
模型:
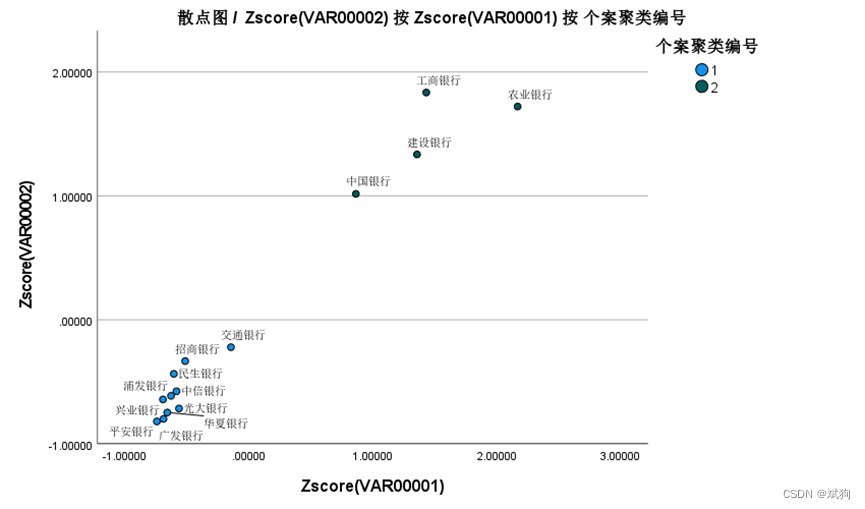
出图:
①判断k的值时的那个图(matlab)
②如果列变量有2个(spss或matlab)或是3个(spss)可以画散点图
Spss中:
首先要保存下分类的类别

二、Q型聚类
对样本(行)进行聚类
Spss实现:
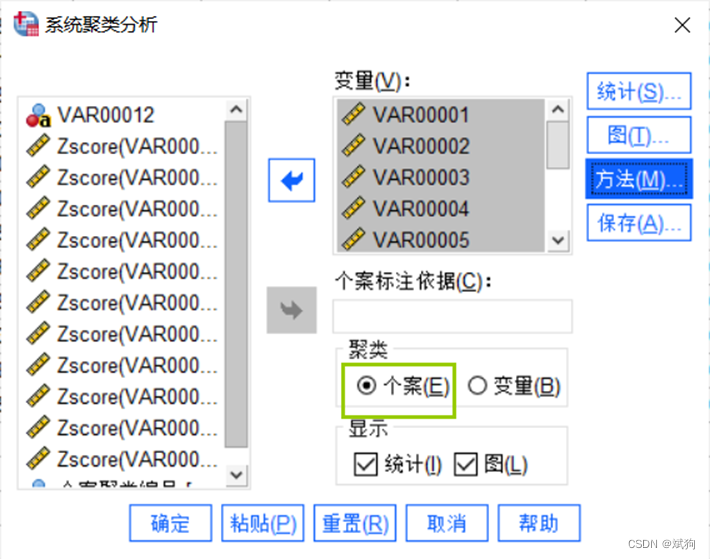
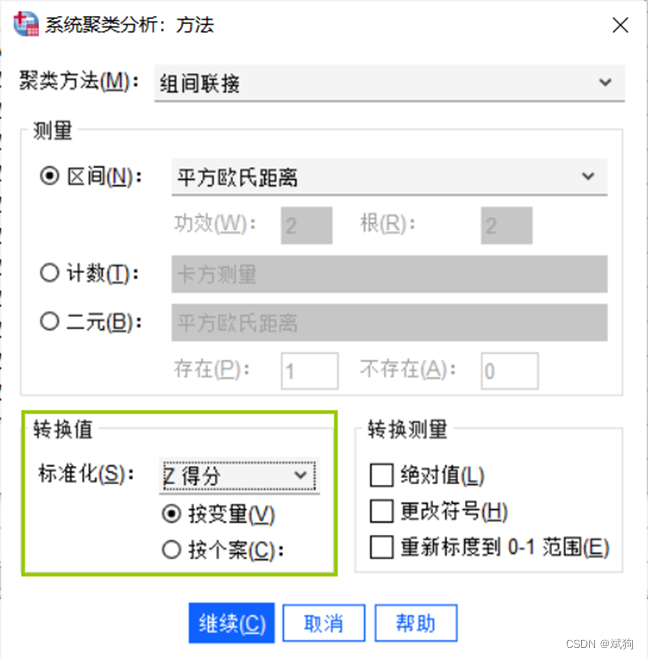
如果数据没有标准化处理,可以在这进行,注意要选择【按变量】,相当于zscore()指令
判断类别
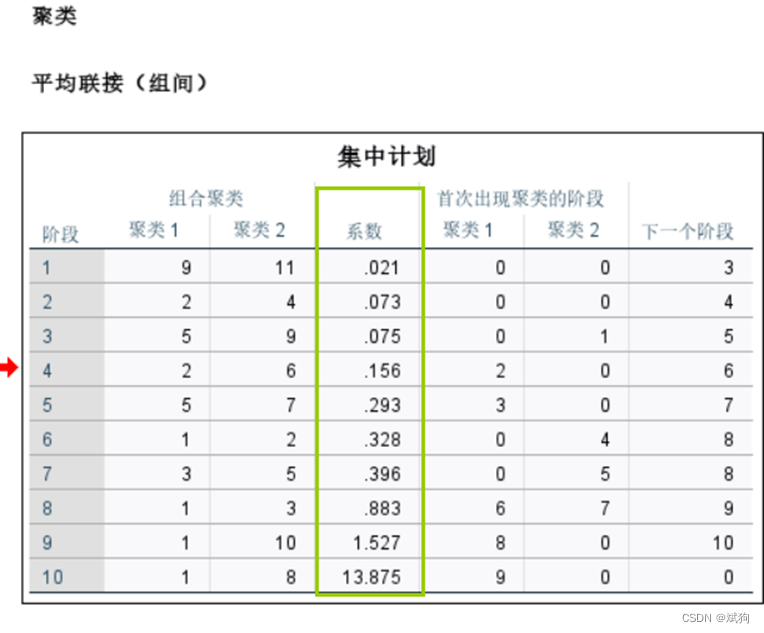
即将系数复制到excel
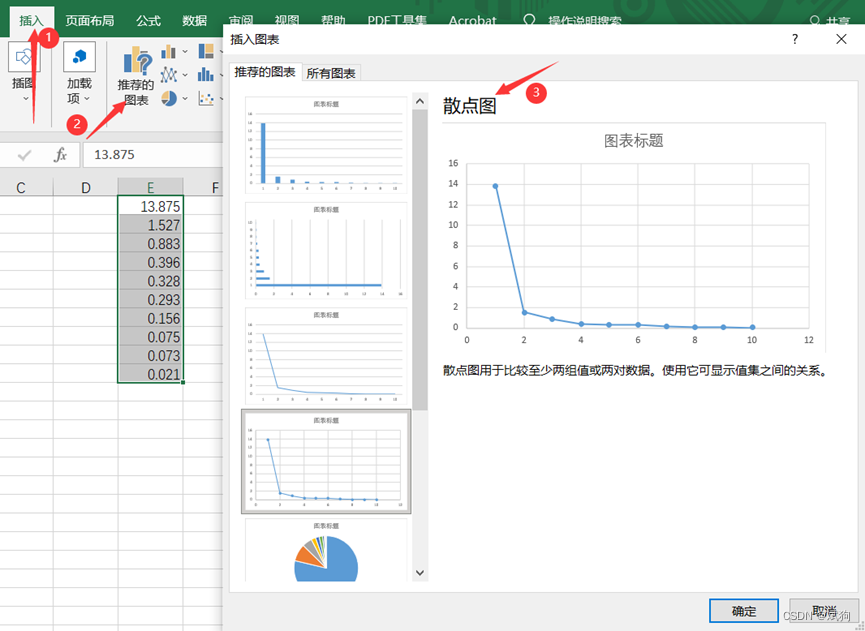
出图:
①判断类别k(spss,matlab)
②聚类图谱(spss)
③如果列变量有2个(spss或matlab)或是3个(spss)可以画散点图
三、R型聚类
对属性(列)进行聚类
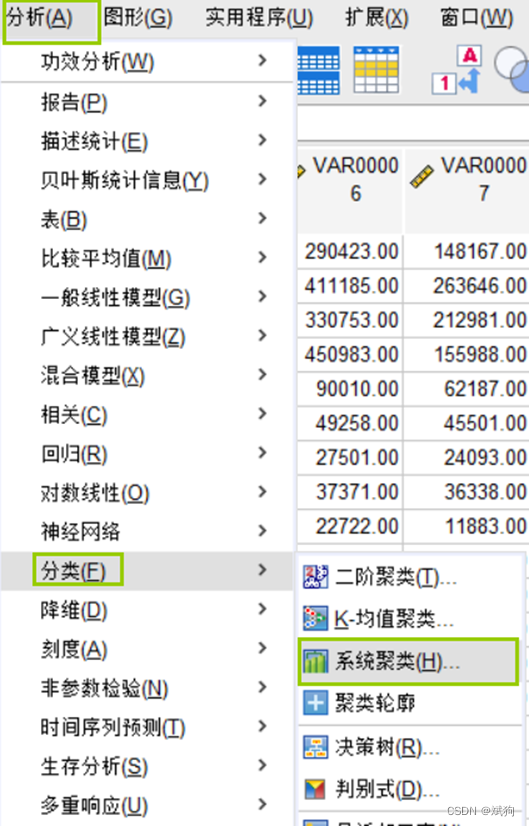
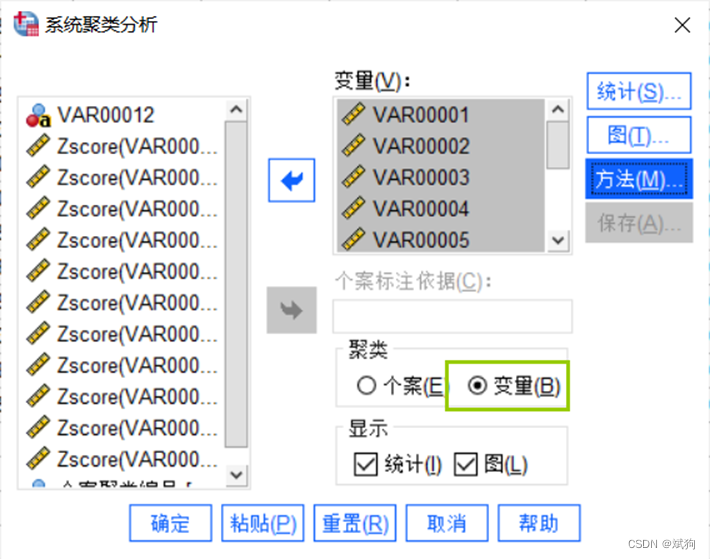
出图:
①判断类别k(spss,matlab)
②聚类图谱(spss)
③如果列变量有2个(spss或matlab)或是3个(spss)可以画散点图
来源地址:https://blog.csdn.net/weixin_53026957/article/details/126575230
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












