

主流Docker网络的实现原理是什么

这篇文章主要介绍了主流Docker网络的实现原理是什么,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
一、容器网络简介
容器网络主要解决两大核心问题:一是容器的IP地址分配,二是容器之间的相互通信。本文重在研究第二个问题并且主要研究容器的跨主机通信问题。
实现容器跨主机通信的最简单方式就是直接使用host网络,这时由于容器IP就是宿主机的IP,复用宿主机的网络协议栈以及underlay网络,原来的主机能通信,容器也就自然能通信,然而带来的最直接问题就是端口冲突问题。
因此通常容器会配置与宿主机不一样的属于自己的IP地址。由于是容器自己配置的IP,underlay平面的底层网络设备如交换机、路由器等完全不感知这些IP的存在,也就导致容器的IP不能直接路由出去实现跨主机通信。
要解决如上问题实现容器跨主机通信,主要有如下两个思路:
思路一:修改底层网络设备配置,加入容器网络IP地址的管理,修改路由器网关等,该方式主要和SDN结合。
思路二:完全不修改底层网络设备配置,复用原有的underlay平面网络,解决容器跨主机通信,主要有如下两种方式:
Overlay隧道传输。把容器的数据包封装到原主机网络的三层或者四层数据包中,然后使用原来的网络使用IP或者TCP/UDP传输到目标主机,目标主机再拆包转发给容器。Overlay隧道如Vxlan、ipip等,目前使用Overlay技术的主流容器网络如Flannel、Weave等。
修改主机路由。把容器网络加到主机路由表中,把主机当作容器网关,通过路由规则转发到指定的主机,实现容器的三层互通。目前通过路由技术实现容器跨主机通信的网络如Flannel host-gw、Calico等。
本文接下来将详细介绍目前主流容器网络的实现原理。
在开始正文内容之前,先引入两个后续会一直使用的脚本:
第一个脚本为 docker_netns.sh:
#!/bin/bash
NAMESPACE=$1
if [[ -z $NAMESPACE ]]; then
ls -1 /var/run/docker/netns/
exit 0
fi
NAMESPACE_FILE=/var/run/docker/netns/${NAMESPACE}
if [[ ! -f $NAMESPACE_FILE ]]; then
NAMESPACE_FILE=$(docker inspect -f "{{.NetworkSettings.SandboxKey}}" $NAMESPACE 2>/dev/null)
fi
if [[ ! -f $NAMESPACE_FILE ]]; then
echo "Cannot open network namespace '$NAMESPACE': No such file or directory"
exit 1
fi
shift
if [[ $# -lt 1 ]]; then
echo "No command specified"
exit 1
fi
nsenter --net=${NAMESPACE_FILE} $@
该脚本通过指定容器id、name或者namespace快速进入容器的network namespace并执行相应的shell命令。
如果不指定任何参数,则列举所有Docker容器相关的network namespaces。
# ./docker_netns.sh # list namespaces
4-a4a048ac67
abe31dbbc394
default
# ./docker_netns.sh busybox ip addr # Enter busybox namespace
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
354: eth0@if355: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:64:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.100.2/24 brd 192.168.100.255 scope global eth0
valid_lft forever preferred_lft forever
356: eth2@if357: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth2
valid_lft forever preferred_lft forever
另一个脚本为 find_links.sh:
#!/bin/bash
DOCKER_NETNS_SCRIPT=./docker_netns.sh
IFINDEX=$1
if [[ -z $IFINDEX ]]; then
for namespace in $($DOCKER_NETNS_SCRIPT); do
printf "e[1;31m%s: e[0m
" $namespace
$DOCKER_NETNS_SCRIPT $namespace ip -c -o link
printf "
"
done
else
for namespace in $($DOCKER_NETNS_SCRIPT); do
if $DOCKER_NETNS_SCRIPT $namespace ip -c -o link | grep -Pq "^$IFINDEX: "; then
printf "e[1;31m%s: e[0m
" $namespace
$DOCKER_NETNS_SCRIPT $namespace ip -c -o link | grep -P "^$IFINDEX: ";
printf "
"
fi
done
fi
该脚本根据ifindex查找虚拟网络设备所在的namespace:
# ./find_links.sh 354abe31dbbc394:354: eth0@if355: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default link/ether 02:42:c0:a8:64:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0该脚本的目的是方便查找veth的对端所在的namespace位置。如果不指定ifindex,则列出所有namespaces的link设备。
二、Docker原生的Overlay
Laurent Bernaille在DockerCon2017上详细介绍了Docker原生的Overlay网络实现原理,作者还总结了三篇干货文章一步一步剖析Docker网络实现原理,最后还教大家一步一步从头开始手动实现Docker的Overlay网络,这三篇文章为:
Deep dive into docker overlay networks part 1
Deep dive into docker overlay networks part 2
Deep dive into docker overlay networks part 3
建议感兴趣的读者阅读,本节也大量参考了如上三篇文章的内容。
2.1 Overlay网络环境
测试使用两个Node节点:
| Node名 | 主机IP |
|---|---|
| node-1 | 192.168.1.68 |
| node-2 | 192.168.1.254 |
首先创建一个overlay网络:
docker network create -d overlay --subnet 10.20.0.0/16 overlay在两个节点分别创建两个busybox容器:
docker run -d --name busybox --net overlay busybox sleep 36000容器列表如下:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 10.20.0.3/16 |
| node-2 | 192.168.1.254 | 10.20.0.2/16 |
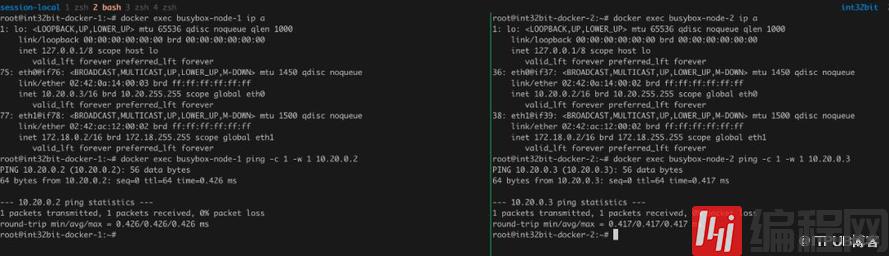
我们发现容器有两个IP,其中eth0 10.20.0.0/16为我们创建的Overlay网络ip,两个容器能够互相ping通。而不在同一个node的容器IP eth2都是172.18.0.2,因此172.18.0.0/16很显然不能用于跨主机通信,只能用于单个节点容器通信。
2.2 容器南北流量
这里的南北流量主要是指容器与外部通信的流量,比如容器访问互联网。
我们查看容器的路由:
# docker exec busybox-node-1 ip rdefault via 172.18.0.1 dev eth210.20.0.0/16 dev eth0 scope link class="lazy" data-src 10.20.0.3172.18.0.0/16 dev eth2 scope link class="lazy" data-src 172.18.0.2由此可知容器默认网关为172.18.0.1,也就是说容器是通过eth2出去的:
# docker exec busybox-node-1 ip link show eth277: eth2@if78: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff# ./find_links.sh 78default:78: vethf2de5d4@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker_gwbridge state UP mode DEFAULT group defaultlink/ether 2e:6a:94:6a:09:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 1通过 find_links.sh脚本查找ifindex为78的link在默认namespace中,并且该link的master为 docker_gwbridge,也就是说该设备挂到了 docker_gwbridgebridge。
# brctl showbridge name bridge id STP enabled interfacesdocker0 8000.02427406ba1a nodocker_gwbridge 8000.0242bb868ca3 no vethf2de5d4而 172.18.0.1正是bridge docker_gwbridge的IP,也就是说 docker_gwbridge是该节点的所有容器的网关。
由于容器的IP是172.18.0.0/16私有IP地址段,不能出公网,因此必然通过NAT实现容器IP与主机IP地址转换,查看iptables nat表如下:
# iptables-save -t nat | grep -- '-A POSTROUTING'-A POSTROUTING -s 172.18.0.0/16 ! -o docker_gwbridge -j MASQUERADE由此可验证容器是通过NAT出去的。
我们发现其实容器南北流量用的其实就是Docker最原生的bridge网络模型,只是把 docker0换成了 docker_gwbridge。如果容器不需要出互联网,创建Overlay网络时可以指定 --internal参数,此时容器只有一个Overlay网络的网卡,不会创建eth2。
2.3 容器东西向流量
容器东西流量指容器之间的通信,这里特指跨主机的容器间通信。
显然容器是通过eth0实现与其他容器通信的:
# docker exec busybox-node-1 ip link show eth0
75: eth0@if76: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:14:00:03 brd ff:ff:ff:ff:ff:ff
# ./find_links.sh 76
1-19c5d1a7ef:
76: veth0@if75: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP mode DEFAULT group default link/ether 6a:ce:89:a2:89:4a brd ff:ff:ff:ff:ff:ff link-netnsid 1
eth0的对端设备ifindex为76,通过 find_links.sh脚本查找ifindex 76在 1-19c5d1a7ef namespace下,名称为 veth0,并且master为br0,因此veth0挂到了br0 bridge下。
通过 docker_netns.sh脚本可以快速进入指定的namespace执行命令:
# ./docker_netns.sh 1-19c5d1a7ef ip link show veth0
76: veth0@if75: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP mode DEFAULT group default
link/ether 6a:ce:89:a2:89:4a brd ff:ff:ff:ff:ff:ff link-netnsid 1
# ./docker_netns.sh 1-19c5d1a7ef brctl show
bridge name bridge id STP enabled interfaces
br0 8000.6ace89a2894a no veth0
vxlan0
可见除了veth0,bridge还绑定了vxlan0:
./docker_netns.sh 1-19c5d1a7ef ip -c -d link show vxlan074: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default link/ether 96:9d:64:39:76:4e brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1 vxlan id 256 class="lazy" data-srcport 0 0 dstport 4789 proxy l2miss l3miss ttl inherit ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx...vxlan0是一个VxLan虚拟网络设备,因此可以推断Docker Overlay是通过vxlan隧道实现跨主机通信的。这里直接引用Deep dive into docker overlay networks part 1的图:
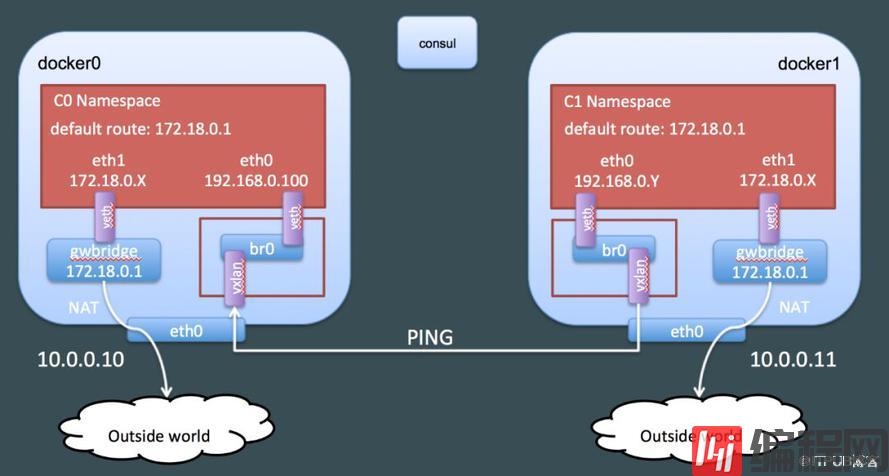
图中192.168.0.0/16对应前面的10.20.0.0/16网段。
2.4 ARP代理
如前面所述,跨主机的两个容器虽然是通过Overlay通信的,但容器自己却不知道,他们只认为彼此都在一个二层中(同一个子网),或者说大二层。我们知道二层是通过MAC地址识别对方的,通过ARP协议广播学习获取IP与MAC地址转换。当然通过Vxlan隧道广播ARP包理论上也没有问题,问题是该方案将导致广播包过多,广播的成本会很大。
和OpenStack Neutron的L2 Population原理一样,Docker也是通过ARP代理+静态配置解决ARP广播问题。我们知道,虽然Linux底层除了通过自学习方式外无法知道目标IP的MAC地址是什么,但是应用却很容易获取这些信息,比如Neutron的数据库中就保存着Port信息,Port中就有IP和MAC地址。Docker也一样会把endpoint信息保存到KV数据库中,如etcd:
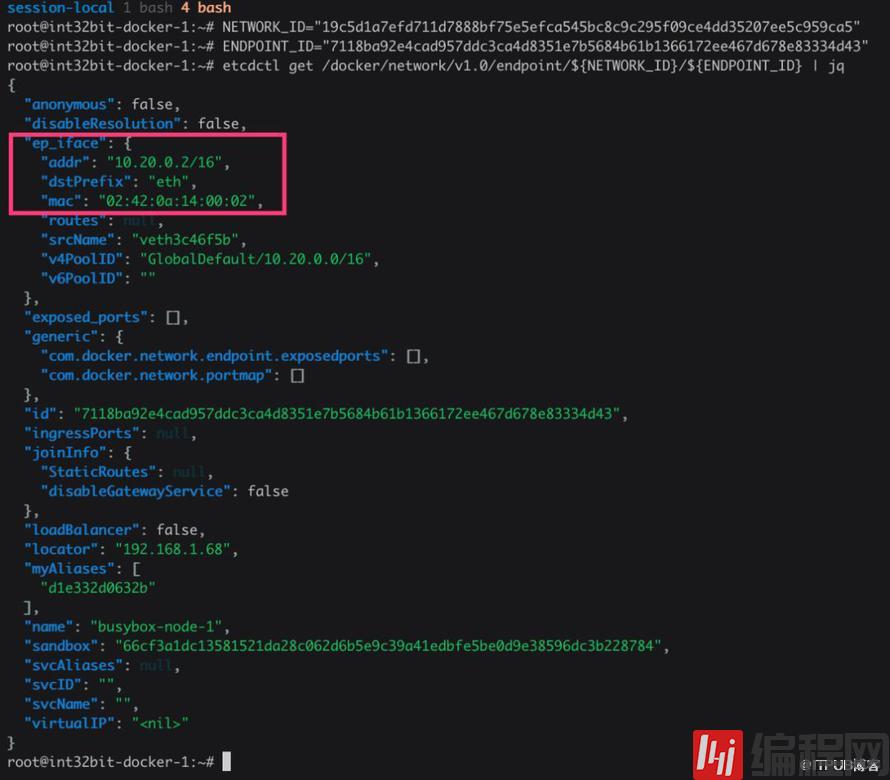
有了这些数据完全可以实现通过静态配置的方式填充IP和MAC地址表(neigh表)替换使用ARP广播的方式。因此vxlan0还负责了本地容器的ARP代理:
./docker_netns.sh 2-19c5d1a7ef ip -d -o link show vxlan0 | grep proxy_arp而vxlan0代理回复时直接查找本地的neigh表回复即可,而本地neigh表则是Docker静态配置,可查看Overlay网络namespaced neigh表:
# ./docker_netns.sh 3-19c5d1a7ef ip neigh20.20.0.3 dev vxlan0 lladdr 02:42:0a:14:00:03 PERMANENT10.20.0.4 dev vxlan0 lladdr 02:42:0a:14:00:04 PERMANENT记录中的 PERMANENT说明是静态配置而不是通过学习获取的,IP 10.20.0.3、10.20.0.4正是另外两个容器的IP地址。
每当有新的容器创建时,Docker通过Serf以及Gossip协议通知节点更新本地neigh ARP表。
2.5 VTEP表静态配置
前面介绍的ARP代理属于L2层问题,而容器的数据包最终还是通过Vxlan隧道传输的,那自然需要解决的问题是这个数据包应该传输到哪个node节点?如果只是两个节点,创建vxlan隧道时可以指定本地ip(local IP)和对端IP(remote IP)建立点对点通信,但实际上显然不可能只有两个节点。
我们不妨把Vxlan出去的物理网卡称为VTEP(VXLAN Tunnel Endpoint),它会有一个可路由的IP,即Vxlan最终封装后的外层IP。通过查找VTEP表决定数据包应该传输到哪个remote VTEP:
| 容器MAC地址 | Vxlan ID | Remote VTEP |
|---|---|---|
| 02:42:0a:14:00:03 | 256 | 192.168.1.254 |
| 02:42:0a:14:00:04 | 256 | 192.168.1.245 |
| ... | ... | ... |
VTEP表和ARP表类似,也可以通过广播洪泛的方式学习,但显然同样存在性能问题,实际上也很少使用这种方案。在硬件SDN中通常使用BGP EVPN技术实现Vxlan的控制平面。
而Docker解决的办法和ARP类似,通过静态配置的方式填充VTEP表,我们可以查看容器网络namespace的转发表(Forward database,简称fdb),
./docker_netns.sh 3-19c5d1a7ef bridge fdb...02:42:0a:14:00:04 dev vxlan0 dst 192.168.1.245 link-netnsid 0 self permanent02:42:0a:14:00:03 dev vxlan0 dst 192.168.1.254 link-netnsid 0 self permanent...可见MAC地址02:42:0a:14:00:04的对端VTEP地址为192.168.1.245,而02:42:0a:14:00:03的对端VTEP地址为192.168.1.254,两条记录都是 permanent,即静态配置的,而这些数据来源依然是KV数据库,endpoint中 locator即为容器的node IP。
2.6 总结
容器使用Docker原生Overlay网络默认会创建两张虚拟网卡,其中一张网卡通过bridge以及NAT出容器外部,即负责南北流量。另一张网卡通过Vxlan实现跨主机容器通信,为了减少广播,Docker通过读取KV数据静态配置ARP表和FDB表,容器创建或者删除等事件会通过Serf以及Gossip协议通知Node更新ARP表和FDB表。
三、和Docker Overlay差不多的Weave
weave是weaveworks公司提供的容器网络方案,实现上和Docker原生Overlay网络有点类似。
初始化三个节点192.168.1.68、192.168.1.254、192.168.1.245如下:
weave launch --ipalloc-range 172.111.222.0/24 192.168.1.68 192.168.1.254 192.168.1.245分别在三个节点启动容器:
# node-1docker run -d --name busybox-node-1 --net weave busybox sleep 3600# node-2docker run -d --name busybox-node-2 --net weave busybox sleep 3600# node-3docker run -d --name busybox-node-3 --net weave busybox sleep 3600在容器中我们相互ping:
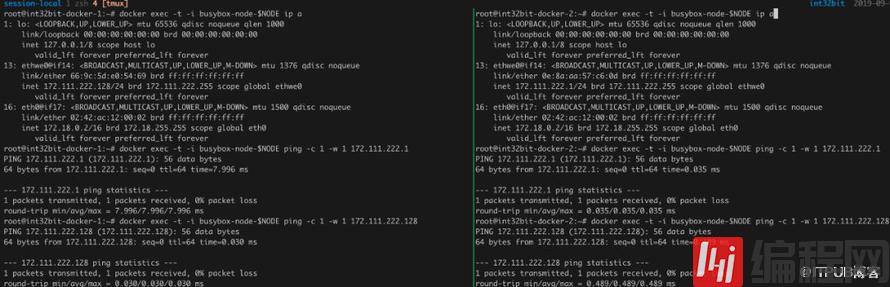
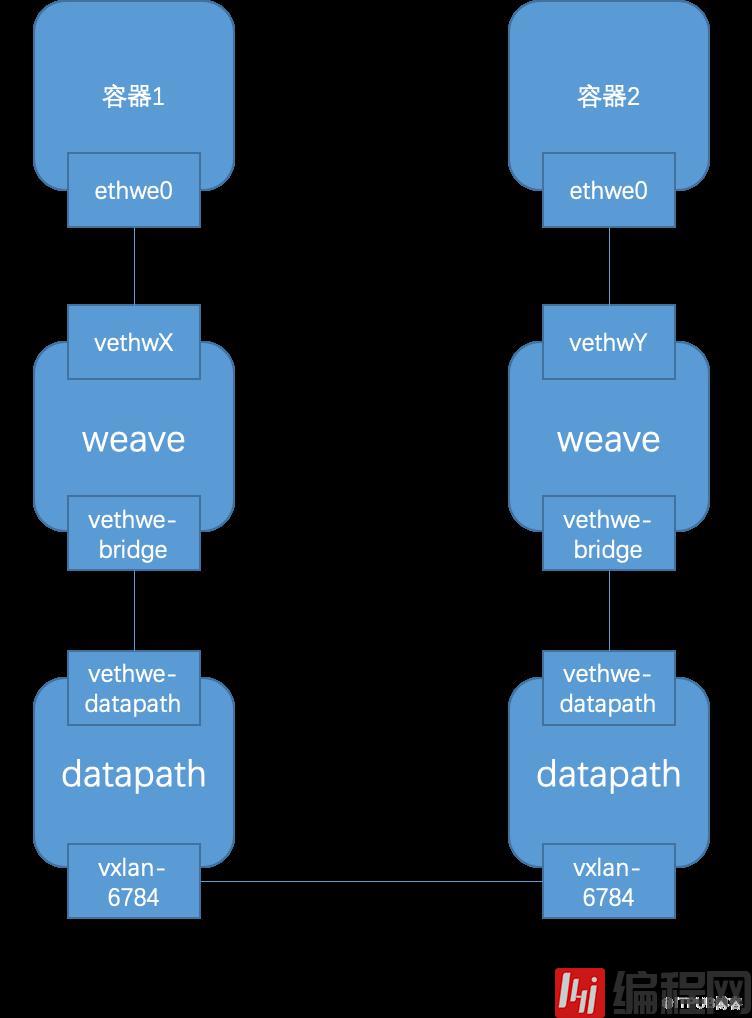
从结果发现,Weave实现了跨主机容器通信,另外我们容器有两个虚拟网卡,一个是Docker原生的桥接网卡eth0,用于南北通信,另一个是Weave附加的虚拟网卡ethwe0,用于容器跨主机通信。
另外查看容器的路由:
# docker exec -t -i busybox-node-$NODE ip rdefault via 172.18.0.1 dev eth0172.18.0.0/16 dev eth0 scope link class="lazy" data-src 172.18.0.2172.111.222.0/24 dev ethwe0 scope link class="lazy" data-src 172.111.222.128224.0.0.0/4 dev ethwe0 scope link其中 224.0.0.0/4是一个组播地址,可见Weave是支持组播的,参考Container Multicast Networking: Docker & Kubernetes | Weaveworks.
我们只看第一个容器的ethwe0,VETH对端ifindex为14:
# ./find_links.sh 14default:14: vethwl816281577@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default link/ether de:12:50:59:f0:d9 brd ff:ff:ff:ff:ff:ff link-netnsid 0可见ethwe0的对端在default namespace下,名称为 vethwl816281577,该虚拟网卡桥接到 weave bridge下:
# brctl show weavebridge name bridge id STP enabled interfacesweave 8000.d2939d07704b no vethwe-bridge vethwl816281577weave bridge下除了有 vethwl816281577,还有 vethwe-bridge:
# ip link show vethwe-bridge9: vethwe-bridge@vethwe-datapath: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master weave state UP mode DEFAULT group default link/ether 0e:ee:97:bd:f6:25 brd ff:ff:ff:ff:ff:ff可见 vethwe-bridge与 vethwe-datapath是一个VETH对,我们查看对端 vethwe-datapath:
# ip -d link show vethwe-datapath8: vethwe-datapath@vethwe-bridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue master datapath state UP mode DEFAULT group default link/ether f6:74:e9:0b:30:6d brd ff:ff:ff:ff:ff:ff promiscuity 1 veth openvswitch_slave addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535vethwe-datapath的master为 datapath,由 openvswitch_slave可知 datapath应该是一个openvswitch bridge,而 vethwe-datapath挂到了 datapath桥下,作为 datapath的port。
为了验证,通过ovs-vsctl查看:
# ovs-vsctl show96548648-a6df-4182-98da-541229ef7b63 ovs_version: "2.9.2"使用 ovs-vsctl发现并没有 datapath这个桥。官方文档中fastdp how it works中解释为了提高网络性能,没有使用用户态的OVS,而是直接操纵内核的datapath。使用 ovs-dpctl命令可以查看内核datapath:
# ovs-dpctl showsystem@datapath: lookups: hit:109 missed:1508 lost:3 flows: 1 masks: hit:1377 total:1 hit/pkt:0.85 port 0: datapath (internal) port 1: vethwe-datapath port 2: vxlan-6784 (vxlan: packet_type=ptap)可见datapath类似于一个OVS bridge设备,负责数据交换,该设备包含三个port:
port 0: datapath (internal)
port 1: vethwe-datapath
port 2: vxlan-6784
除了 vethwe-datapath,还有一个 vxlan-6784,由名字可知这是一个vxlan:
# ip -d link show vxlan-678410: vxlan-6784: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65535 qdisc noqueue master datapath state UNKNOWN mode DEFAULT group default qlen 1000 link/ether d2:21:db:c1:9b:28 brd ff:ff:ff:ff:ff:ff promiscuity 1 vxlan id 0 class="lazy" data-srcport 0 0 dstport 6784 nolearning ttl inherit ageing 300 udpcsum noudp6zerocsumtx udp6zerocsumrx external openvswitch_slave addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535最后Weave的网络流量图如下:
四、简单优雅的Flannel
4.1 Flannel简介
Flannel网络是目前最主流的容器网络之一,同时支持overlay(如vxlan)和路由(如host-gw)两种模式。
Flannel和Weave以及Docker原生overlay网络不同的是,后者的所有Node节点共享一个子网,而Flannel初始化时通常指定一个16位的网络,然后每个Node单独分配一个独立的24位子网。由于Node都在不同的子网,跨节点通信本质为三层通信,也就不存在二层的ARP广播问题了。
另外,我认为Flannel之所以被认为非常简单优雅的是,不像Weave以及Docker Overlay网络需要在容器内部再增加一个网卡专门用于Overlay网络的通信,Flannel使用的就是Docker最原生的bridge网络,除了需要为每个Node配置subnet(bip)外,几乎不改变原有的Docker网络模型。
4.2 Flannel Overlay网络
我们首先以Flannel Overlay网络模型为例,三个节点的IP以及Flannel分配的子网如下:
| Node名 | 主机IP | 分配的子网 |
|---|---|---|
| node-1 | 192.168.1.68 | 40.15.43.0/24 |
| node-2 | 192.168.1.254 | 40.15.26.0/24 |
| node-3 | 192.168.1.245 | 40.15.56.0/24 |
在三个集成了Flannel网络的Node环境下分别创建一个 busybox容器:
docker run -d --name busybox busybox:latest sleep 36000容器列表如下:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 40.15.43.2/24 |
| node-2 | 192.168.1.254 | 40.15.26.2/24 |
| node-3 | 192.168.1.245 | 40.15.56.2/24 |
查看容器namespace的网络设备:
# ./docker_netns.sh busybox ip -d -c link416: eth0@if417: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8951 qdisc noqueue state UP mode DEFAULT group default link/ether 02:42:28:0f:2b:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 0 veth addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535和Docker bridge网络一样只有一张网卡eth0,eth0为veth设备,对端的ifindex为417.
我们查找下ifindex 417的link信息:
# ./find_links.sh 417default:417: veth2cfe340@if416: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8951 qdisc noqueue master docker0 state UP mode DEFAULT group default link/ether 26:bd:de:86:21:78 brd ff:ff:ff:ff:ff:ff link-netnsid 0可见ifindex 417在default namespace下,名称为 veth2cfe340并且master为docker0,因此挂到了docker0的bridge下。
# brctl showbridge name bridge id STP enabled interfacesdocker0 8000.0242d6f8613e no veth2cfe340 vethd1fae9ddocker_gwbridge 8000.024257f32054 no和Docker原生的bridge网络没什么区别,那它是怎么解决跨主机通信的呢?
实现跨主机通信,要么Overlay隧道封装,要么静态路由,显然docker0没有看出有什么overlay的痕迹,因此只能通过路由实现了。
不妨查看下本地路由如下:
# ip rdefault via 192.168.1.1 dev eth0 proto dhcp class="lazy" data-src 192.168.1.68 metric 10040.15.26.0/24 via 40.15.26.0 dev flannel.1 onlink40.15.43.0/24 dev docker0 proto kernel scope link class="lazy" data-src 40.15.43.140.15.56.0/24 via 40.15.56.0 dev flannel.1 onlink...我们只关心40.15开头的路由,忽略其他路由,我们发现除了40.15.43.0/24直接通过docker0直连外,其他均路由转发到了 flannel.1。而40.15.43.0/24为本地Node的子网,因此在同一宿主机的容器直接通过docker0通信即可。
我们查看 flannel.1的设备类型:
413: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8951 qdisc noqueue state UNKNOWN mode DEFAULT group default link/ether 0e:08:23:57:14:9a brd ff:ff:ff:ff:ff:ff promiscuity 0 vxlan id 1 local 192.168.1.68 dev eth0 class="lazy" data-srcport 0 0 dstport 8472 nolearning ttl inherit ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535可见 flannel.1是一个Linux Vxlan设备,其中 .1为VNI值,不指定默认为1。
由于不涉及ARP因此不需要proxy参数实现ARP代理,而本节点的容器通信由于在一个子网内,因此直接ARP自己学习即可,不需要Vxlan设备学习,因此有个nolearning参数。
而 flannel.1如何知道对端VTEP地址呢?我们依然查看下转发表fdb:
bridge fdb | grep flannel.14e:55:ee:0a:90:38 dev flannel.1 dst 192.168.1.245 self permanentda:17:1b:07:d3:70 dev flannel.1 dst 192.168.1.254 self permanent其中192.168.1.245、192.168.1.254正好是另外两个Node的IP,即VTEP地址,而 4e:55:ee:0a:90:38以及 da:17:1b:07:d3:70为对端的 flannel.1设备的MAC地址,由于是 permanent表,因此可推测是由flannel静态添加的,而这些信息显然可以从etcd获取:
# for subnet in $(etcdctl ls /coreos.com/network/subnets); do etcdctl get $subnet;done{"PublicIP":"192.168.1.68","BackendType":"vxlan","BackendData":{"VtepMAC":"0e:08:23:57:14:9a"}}{"PublicIP":"192.168.1.254","BackendType":"vxlan","BackendData":{"VtepMAC":"da:17:1b:07:d3:70"}}{"PublicIP":"192.168.1.245","BackendType":"vxlan","BackendData":{"VtepMAC":"4e:55:ee:0a:90:38"}}因此Flannel的Overlay网络实现原理简化如图:
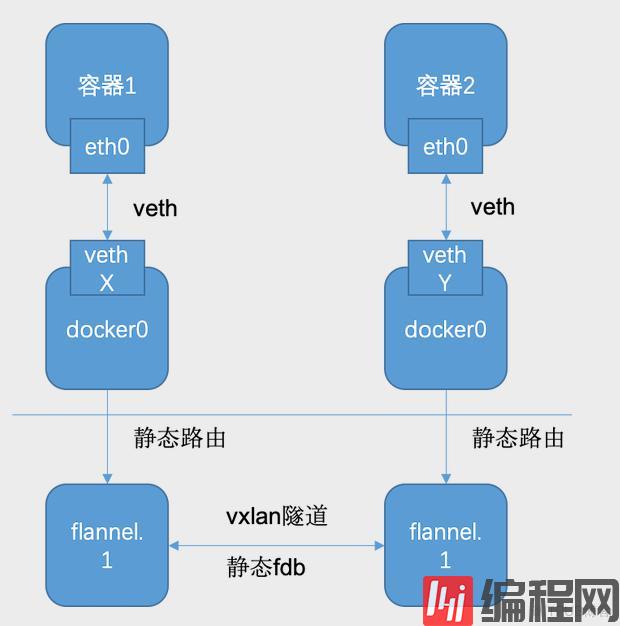
可见除了增加或者减少Node,需要Flannel配合配置静态路由以及fdb表,容器的创建与删除完全不需要Flannel干预,事实上Flannel也不需要知道有没有新的容器创建或者删除。
4.3 Flannel host-gw网络
前面介绍Flannel通过Vxlan实现跨主机通信,其实Flannel支持不同的backend,其中指定backend type为host-gw支持通过静态路由的方式实现容器跨主机通信,这时每个Node都相当于一个路由器,作为容器的网关,负责容器的路由转发。
需要注意的是,如果使用AWS EC2,使用Flannel host-gw网络需要禁用MAC地址欺骗功能,如图:

使用OpenStack则最好禁用Neutron的port security功能。
同样地,我们在三个节点分别创建busybox容器,结果如下:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 40.15.43.2/24 |
| node-2 | 192.168.1.254 | 40.15.26.2/24 |
| node-3 | 192.168.1.245 | 40.15.56.2/24 |
我们查看192.168.1.68的本地路由:
# ip rdefault via 192.168.1.1 dev eth0 proto dhcp class="lazy" data-src 192.168.1.68 metric 10040.15.26.0/24 via 192.168.1.254 dev eth040.15.43.0/24 dev docker0 proto kernel scope link class="lazy" data-src 40.15.43.140.15.56.0/24 via 192.168.1.245 dev eth0...我们只关心40.15前缀的路由,发现40.15.26.0/24的下一跳为192.168.1.254,正好为node2 IP,而40.15.43.0/24的下一跳为本地docker0,因为该子网就是node所在的子网,40.15.56.0/24的下一跳为192.168.1.245,正好是node3 IP。可见,Flannel通过配置静态路由的方式实现容器跨主机通信,每个Node都作为路由器使用。
host-gw的方式相对Overlay由于没有vxlan的封包拆包过程,直接路由就过去了,因此性能相对要好。不过正是由于它是通过路由的方式实现,每个Node相当于是容器的网关,因此每个Node必须在同一个LAN子网内,否则跨子网由于链路层不通导致无法实现路由导致host-gw实现不了。
4.4 Flannel利用云平台路由实现跨主机通信
前面介绍的host-gw是通过修改主机路由表实现容器跨主机通信,如果能修改主机网关的路由当然也是没有问题的,尤其是和SDN结合方式动态修改路由。
目前很多云平台均实现了自定义路由表的功能,比如OpenStack、AWS等,Flannel借助这些功能实现了很多公有云的VPC后端,通过直接调用云平台API修改路由表实现容器跨主机通信,比如阿里云、AWS、Google云等,不过很可惜官方目前好像还没有实现OpenStack Neutron后端。
下面以AWS为例,创建了如下4台EC2虚拟机:
node-1: 197.168.1.68/24
node-2: 197.168.1.254/24
node-3: 197.168.1.245/24
node-4: 197.168.0.33/24
注意第三台和其余两台不在同一个子网。
三台EC2均关联了flannel-role,flannel-role关联了flannel-policy,policy的权限如下:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:CreateRoute", "ec2:DeleteRoute", "ec2:ModifyInstanceAttribute", "ec2:DescribeRouteTables", "ec2:ReplaceRoute" ], "Resource": "*" } ]}即EC2实例需要具有修改路由表等相关权限。
之前一直很疑惑AWS的role如何与EC2虚拟机关联起来的。换句话说,如何实现虚拟机无需配置Key和Secretd等认证信息就可以直接调用AWS API,通过awscli的 --debug信息可知awscli首先通过metadata获取role信息,再获取role的Key和Secret:

关于AWS如何知道调用metadata的是哪个EC2实例,可参考之前的文章OpenStack虚拟机如何获取metadata.
另外所有EC2实例均禁用了MAC地址欺骗功能(Change Source/Dest Check),安全组允许flannel网段40.15.0.0/16通过,另外增加了如下iptables规则:
iptables -I FORWARD --dest 40.15.0.0/16 -j ACCEPTiptables -I FORWARD --class="lazy" data-src 40.15.0.0/16 -j ACCEPTflannel配置如下:
# etcdctl get /coreos.com/network/config | jq .{ "Network": "40.15.0.0/16", "Backend": { "Type": "aws-vpc" }}启动flannel,自动为每个Node分配24位子网,网段如下:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 40.15.16.0/24 |
| node-2 | 192.168.1.254 | 40.15.64.0/24 |
| node-3 | 192.168.1.245 | 40.15.13.0/24 |
| node-4 | 192.168.0.33 | 40.15.83.0/24 |
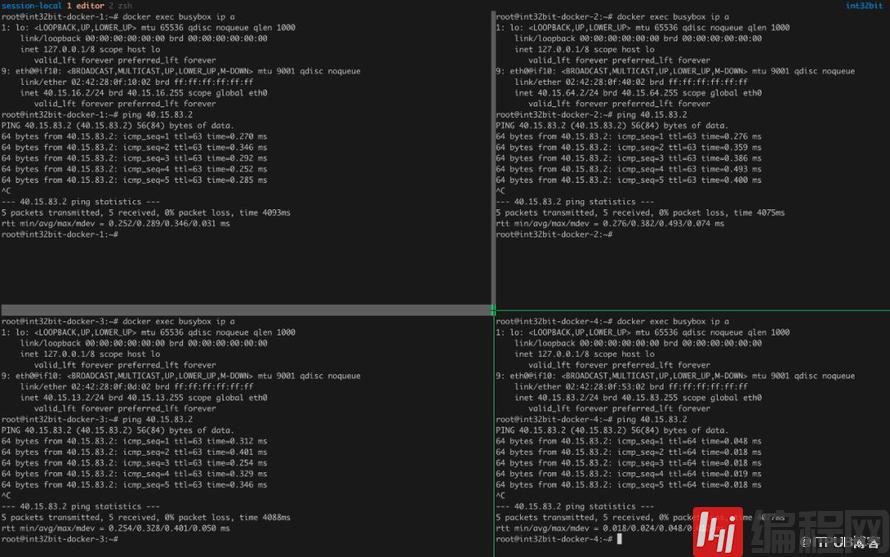
我们查看node-1、node-2、node-3关联的路由表如图:

node-4关联的路由表如图:
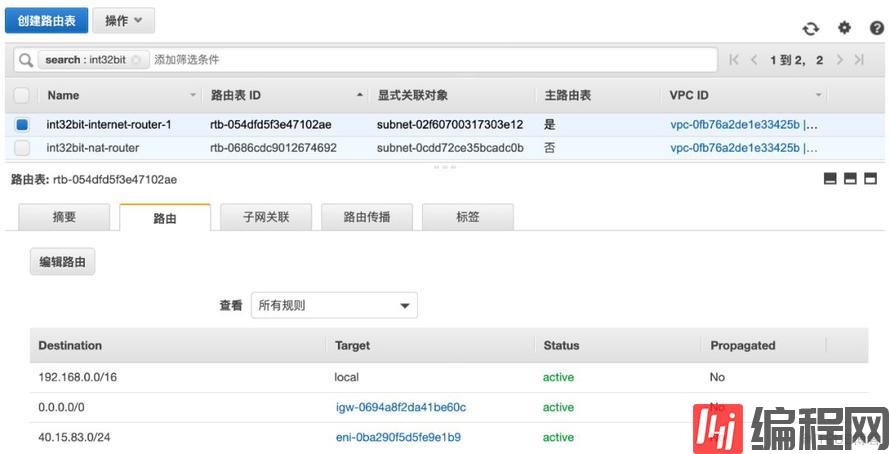
由此可见,每增加一个Flannel节点,Flannel就会调用AWS API在EC2实例的子网关联的路由表上增加一条记录,Destination为该节点分配的Flannel子网,Target为该EC2实例的主网卡。
在4个节点分别创建一个busybox容器,容器IP如下:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 40.15.16.2/24 |
| node-2 | 192.168.1.254 | 40.15.64.2/24 |
| node-3 | 192.168.1.245 | 40.15.13.2/24 |
| node-4 | 192.168.0.33 | 40.15.83.2/24 |
所有节点ping node-4的容器,如图:
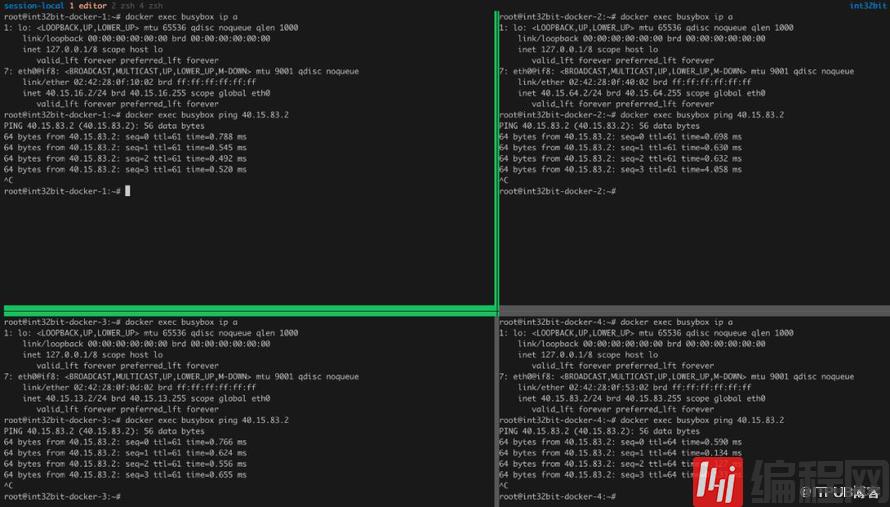
我们发现所有节点都能ping通node-4的容器。但是node-4的容器却ping不通其余容器:
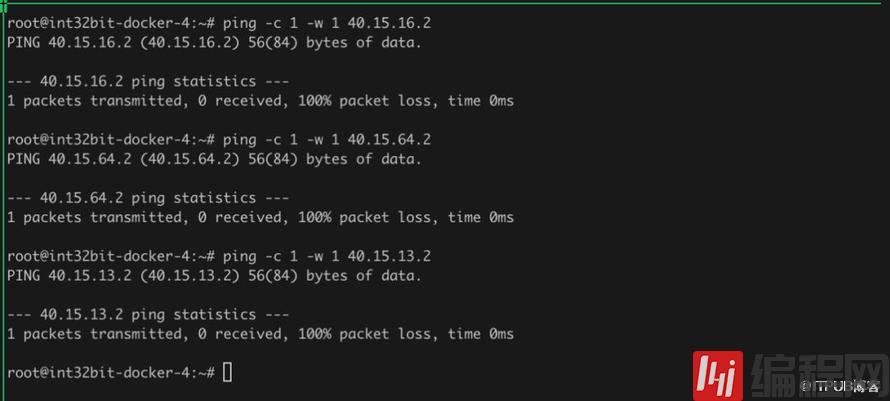
这是因为每个Node默认只会添加自己所在路由的记录。node-4没有node-1 ~ node-3的路由信息,因此不通。
可能有人会问,node1 ~ node3也没有node4的路由,那为什么能ping通node4的容器呢?这是因为我的环境中node1 ~ node3子网关联的路由是NAT网关,node4是Internet网关,而NAT网关的子网正好是node1 ~ node4关联的子网,因此node1 ~ node3虽然在自己所在的NAT网关路由没有找到node4的路由信息,但是下一跳到达Internet网关的路由表中找到了node4的路由,因此能够ping通,而node4找不到node1 ~ node3的路由,因此都ping不通。
以上只是默认行为,Flannel可以通过 RouteTableID参数配置Node需要更新的路由表,我们只需要增加如下两个子网的路由如下:
# etcdctl get /coreos.com/network/config | jq .{ "Network": "40.15.0.0/16", "Backend": { "Type": "aws-vpc", "RouteTableID": [ "rtb-0686cdc9012674692", "rtb-054dfd5f3e47102ae" ] }}重启Flannel服务,再次查看两个路由表:

我们发现两个路由表均添加了node1 ~ node4的Flannel子网路由。
此时四个节点的容器能够相互ping通。
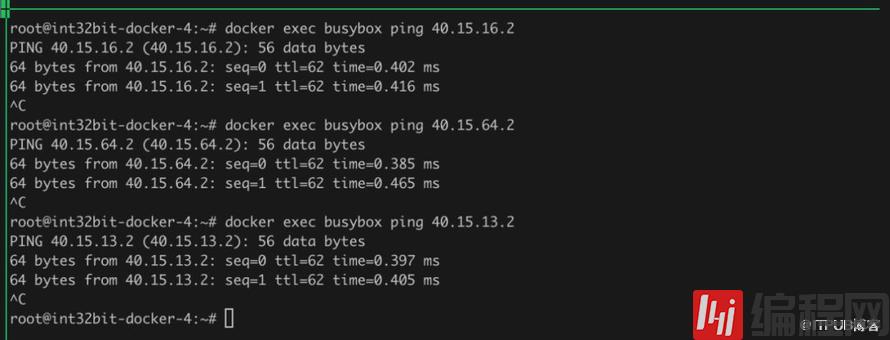
从中我们发现,aws-vpc解决了host-gw不能跨子网的问题,Flannel官方也建议如果使用AWS,推荐使用aws-vpc替代overlay方式,能够获取更好的性能:
When running within an Amazon VPC, we recommend using the aws-vpc backend which, instead of using encapsulation, manipulates IP routes to achieve maximum performance. Because of this, a separate flannel interface is not created.
The biggest advantage of using flannel AWS-VPC backend is that the AWS knows about that IP. That makes it possible to set up ELB to route directly to that container.
另外,由于路由是添加到了主机网关上,因此只要关联了该路由表,EC2实例是可以从外面直接ping通容器的,换句话说,同一子网的EC2虚拟机可以直接与容器互通。
不过需要注意的是,AWS路由表默认最多支持50条路由规则,这限制了Flannel节点数量,不知道AWS是否支持增加配额功能。另外目前最新版的Flannel v0.10.0好像对aws-vpc支持有点问题,再官方修复如上问题之前建议使用Flannel v0.8.0版本。
五、黑科技最多的Calico
5.1 Calico环境配置
Calico和Flannel host-gw类似都是通过路由实现跨主机通信,区别在于Flannel通过flanneld进程逐一添加主机静态路由实现,而Calico则是通过BGP实现节点间路由规则的相互学习广播。
这里不详细介绍BGP的实现原理,仅研究容器是如何通信的。
创建了3个节点的calico集群,ip pool配置如下:
# calicoctl get ipPool -o yaml- apiVersion: v1 kind: ipPool metadata: cidr: 197.19.0.0/16 spec: ipip: enabled: true mode: cross-subnet nat-outgoing: true- apiVersion: v1 kind: ipPool metadata: cidr: fd80:24e2:f998:72d6::/64 spec: {}Calico分配的ip如下:
for host in $(etcdctl --endpoints $ENDPOINTS ls /calico/ipam/v2/host/); do
etcdctl --endpoints $ENDPOINTS ls $host/ipv4/block | awk -F '/' '{sub(/-/,"/",$NF)}{print $6,$NF}'
done | sort
int32bit-docker-1 197.19.38.128/26
int32bit-docker-2 197.19.186.192/26
int32bit-docker-3 197.19.26.0/26
由此可知,Calico和Flannel一样,每个节点分配一个子网,只不过Flannel默认分24位子网,而Calico分的是26位子网。
三个节点分别创建busybox容器:
| Node名 | 主机IP | 容器IP |
|---|---|---|
| node-1 | 192.168.1.68 | 197.19.38.136 |
| node-2 | 192.168.1.254 | 197.19.186.197 |
| node-3 | 192.168.1.245 | 197.19.26.5/24 |

相互ping通没有问题。
5.2 Calico容器内部网络
我们查看容器的link设备以及路由:
# ./docker_netns.sh busybox ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
14: cali0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 197.19.38.136/32 brd 197.19.38.136 scope global cali0
valid_lft forever preferred_lft forever
# ./docker_netns.sh busybox ip r
default via 169.254.1.1 dev cali0
169.254.1.1 dev cali0 scope link
有如下几点个人感觉很神奇:
所有容器的MAC地址都是
ee:ee:ee:ee:ee:ee,网关地址是169.254.1.1,然而我找尽了所有的namespaces也没有找到这个IP。
这两个问题在Calico官方的faq中有记录#1 Why do all cali* interfaces have the MAC address ee:ee:ee:ee:ee:ee?、#2 Why can’t I see the 169.254.1.1 address mentioned above on my host?。
针对第一个问题,官方认为不是所有的内核都能支持自动分配MAC地址,所以干脆Calico自己指定MAC地址,而Calico完全使用三层路由通信,MAC地址是什么其实无所谓,因此直接都使用 ee:ee:ee:ee:ee:ee。
第二个问题,回顾之前的网络模型,大多数都是把容器的网卡通过VETH连接到一个bridge设备上,而这个bridge设备往往也是容器网关,相当于主机上多了一个虚拟网卡配置。Calico认为容器网络不应该影响主机网络,因此容器的网卡的VETH另一端没有经过bridge直接挂在默认的namespace中。而容器配的网关其实也是假的,通过proxy_arp修改MAC地址模拟了网关的行为,所以网关IP是什么也无所谓,那就直接选择了local link的一个ip,这还节省了容器网络的一个IP。我们可以抓包看到ARP包:
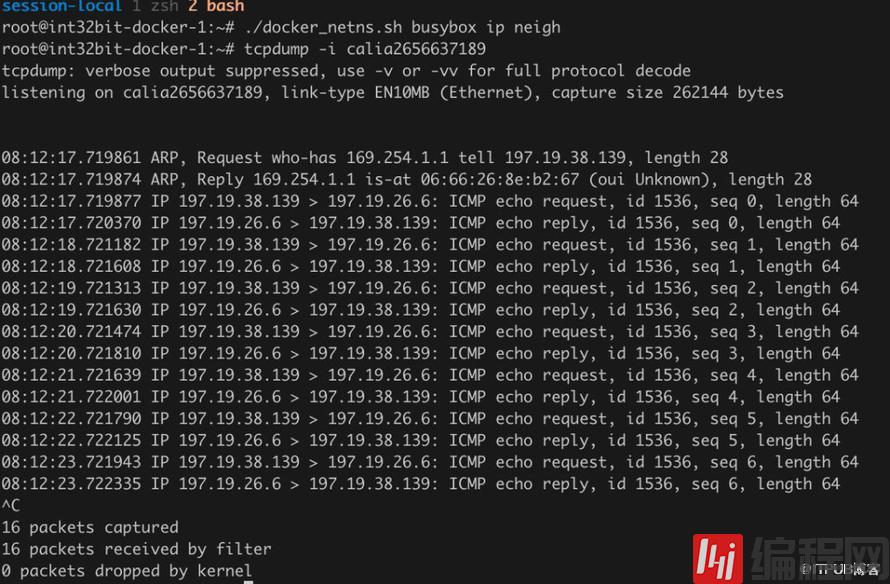
可以看到容器网卡的对端 calia2656637189直接代理回复了ARP,因此出去网关时容器的包会直接把MAC地址修改为 06:66:26:8e:b2:67,即伪网关的MAC地址。
有人可能会说那如果在同一主机的容器通信呢?他们应该在同一个子网,容器的MAC地址都是一样那怎么进行二层通信呢?仔细看容器配置的IP掩码居然是32位的,那也就是说跟谁都不在一个子网了,也就不存在二层的链路层直接通信了。
5.3 Calico主机路由
前面提到Calico通过BGP动态路由实现跨主机通信,我们查看主机路由如下,其中197.19.38.139、197.19.38.140是在本机上的两个容器IP:
# ip r | grep 197.19197.19.26.0/26 via 192.168.1.245 dev eth0 proto birdblackhole 197.19.38.128/26 proto bird197.19.38.139 dev calia2656637189 scope link197.19.38.140 dev calie889861df72 scope link197.19.186.192/26 via 192.168.1.254 dev eth0 proto bird我们发现跨主机通信和Flannel host-gw完全一样,下一跳直接指向hostIP,把host当作容器的网关。不一样的是到达宿主机后,Flannel会通过路由转发流量到bridge设备中,再由bridge转发给容器,而Calico则为每个容器的IP生成一条明细路由,直接指向容器的网卡对端。因此如果容器数量很多的话,主机路由规则数量也会越来越多,因此才有了路由反射,这里不过多介绍。
里面还有一条blackhole路由,如果来的IP是在host分配的容器子网197.19.38.128/26中,而又不是容器的IP,则认为是非法地址,直接丢弃。
5.4 Calico多网络支持
在同一个集群上可以同时创建多个Calico网络:
# docker network ls | grep calicoad7ca8babf01 calico-net-1 calico global5eaf3984f69d calico-net-2 calico global我们使用另一个Calico网络calico-net-2创建一个容器:
docker run -d --name busybox-3 --net calico-net-2 busybox sleep 36000
# docker exec busybox-3 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
24: cali0@if25: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff
inet 197.19.38.141/32 brd 197.19.38.141 scope global cali0
valid_lft forever preferred_lft forever
# ip r | grep 197.19
197.19.26.0/26 via 192.168.1.245 dev eth0 proto bird
blackhole 197.19.38.128/26 proto bird
197.19.38.139 dev calia2656637189 scope link
197.19.38.140 dev calie889861df72 scope link
197.19.38.141 dev calib12b038e611 scope link
197.19.186.192/26 via 192.168.1.254 dev eth0 proto bird
我们发现在同一个主机不在同一个网络的容器IP地址在同一个子网,那不是可以通信呢?
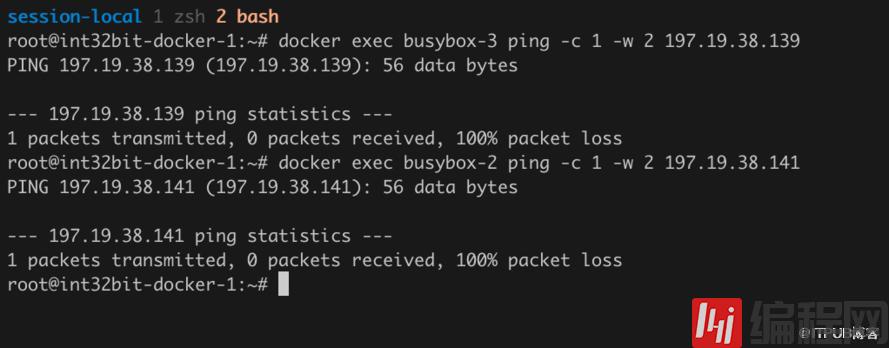
我们发现虽然两个跨网络的容器分配的IP在同一个子网,但居然实现了隔离。
如果使用诸如vxlan的overlay网络,很好猜测是怎么实现隔离的,无非就是使用不同的VNI。但Calico没有使用overlay,直接使用路由通信,而且不同网络的子网还是重叠的,它是怎么实现隔离的呢。
要在同一个子网实现隔离,我们猜测实现方式只能是逻辑隔离,即通过本地防火墙如iptables实现。
查看了下Calico生成的iptables规则发现太复杂了,各种包mark。由于决定包的放行或者丢弃通常是在filter表实现,而不是发往主机的自己的包应该在FORWARD链中,因此我们直接研究filter表的FORWARD表。
# iptables-save -t filter | grep -- '-A FORWARD'-A FORWARD -m comment --comment "cali:wUHhoiAYhphO9Mso" -j cali-FORWARD...Calico把cali-FORWARD子链挂在了FORWARD链上,comment中的一串看起来像随机字符串 cali:wUHhoiAYhphO9Mso不知道是干嘛的。
# iptables-save -t filter | grep -- '-A cali-FORWARD'-A cali-FORWARD -i cali+ -m comment --comment "cali:X3vB2lGcBrfkYquC" -j cali-from-wl-dispatch-A cali-FORWARD -o cali+ -m comment --comment "cali:UtJ9FnhBnFbyQMvU" -j cali-to-wl-dispatch-A cali-FORWARD -i cali+ -m comment --comment "cali:Tt19HcSdA5YIGSsw" -j ACCEPT-A cali-FORWARD -o cali+ -m comment --comment "cali:9LzfFCvnpC5_MYXm" -j ACCEPT...cali+表示所有以cali为前缀的网络接口,即容器的网卡对端设备。由于我们只关心发往容器的流量方向,即从caliXXX发往容器的流量,因此我们只关心条件匹配的 -o cali+的规则,从如上可以看出所有从 cali+出来的流量都跳转到了 cali-to-wl-dispatch子链处理,其中 wl是workload的缩写,workload即容器。
# iptables-save -t filter | grep -- '-A cali-to-wl-dispatch'-A cali-to-wl-dispatch -o calia2656637189 -m comment --comment "cali:TFwr8sfMnFH3BUla" -g cali-tw-calia2656637189-A cali-to-wl-dispatch -o calib12b038e611 -m comment --comment "cali:ZbRb0ozg-GGeUfRA" -g cali-tw-calib12b038e611-A cali-to-wl-dispatch -o calie889861df72 -m comment --comment "cali:5OoGv50NzX0sKdMg" -g cali-tw-calie889861df72-A cali-to-wl-dispatch -m comment --comment "cali:RvicCiwAy9cIEAKA" -m comment --comment "Unknown interface" -j DROP从子链名字也可以看出 cali-to-wl-dispatch是负责流量的分发的,即根据具体的流量出口引到具体的处理流程子链,从X出来的,由cali-tw-X处理,从Y出来的,由cali-tw-Y处理,依次类推,其中 tw为 to workload的简写。
我们假设是发往busybox 197.19.38.139这个容器的,对应的主机虚拟设备为 calia2656637189,则跳转子链为 cali-tw-calia2656637189:
# iptables-save -t filter | grep -- '-A cali-tw-calia2656637189'-A cali-tw-calia2656637189 -m comment --comment "cali:259EHpBvnovN8_q6" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT-A cali-tw-calia2656637189 -m comment --comment "cali:YLokMEiVkZggfg9R" -m conntrack --ctstate INVALID -j DROP-A cali-tw-calia2656637189 -m comment --comment "cali:pp8a6fGxqaALtRK5" -j MARK --set-xmark 0x0/0x1000000-A cali-tw-calia2656637189 -m comment --comment "cali:bgw2sCtlIfZjhXLA" -j cali-pri-calico-net-1-A cali-tw-calia2656637189 -m comment --comment "cali:1Z2NvhoS27pP03Ll" -m comment --comment "Return if profile accepted" -m mark --mark 0x1000000/0x1000000 -j RETURN-A cali-tw-calia2656637189 -m comment --comment "cali:mPb8hORsTXeVt7yC" -m comment --comment "Drop if no profiles matched" -j DROP其中第1、2条规则在深入浅出OpenStack安全组实现原理中介绍过,不再赘述。
第三条规则注意使用的是 set-xmark而不是 set-mark,为什么不用 set-mark,这是由于 set-mark会覆盖原来的值。而 set-xmark value/netmask,表示 X=(X&(~netmask))^value, --set-xmark0x0/0x1000000的意思就是把X的第25位重置为0,其他位保留不变。
这个mark位的含义我在官方中没有找到,在Calico网络的原理、组网方式与使用这篇文章找到了相关资料:
node一共使用了3个标记位,0x7000000对应的标记位
0x1000000: 报文的处理动作,置1表示放行,默认0表示拒绝
0x2000000: 是否已经经过了policy规则检测,置1表示已经过
0x4000000: 报文来源,置1,表示来自host-endpoint
即第25位表示报文的处理动作,为1表示通过,0表示拒绝,第5、6条规则也可以看出第25位的意义,匹配0x1000000/0x1000000直接RETRUN,不匹配的直接DROP。
因此第3条规则的意思就是清空第25位标志位重新评估,谁来评估呢?这就是第4条规则的作用,根据虚拟网络设备cali-XXX所处的网络跳转到指定网络的子链中处理,由于 calia2656637189属于calico-net-1,因此会跳转到 cali-pri-calico-net-1子链处理。
我们观察 cali-pri-calico-net-1的规则:
# iptables-save -t filter | grep -- '-A cali-pri-calico-net-1'-A cali-pri-calico-net-1 -m comment --comment "cali:Gvse2HBGxQ9omCdo" -m set --match-set cali4-s:VFoIKKR-LOG_UuTlYqcKubo class="lazy" data-src -j MARK --set-xmark 0x1000000/0x1000000-A cali-pri-calico-net-1 -m comment --comment "cali:0vZpvvDd_5bT7g_k" -m mark --mark 0x1000000/0x1000000 -j RETURN规则很简单,只要IP在cali4-s:VFoIKKR-LOG_UuTlYqcKubo在这个ipset集合中就设置mark第25位为1,然后RETURN,否则如果IP不在ipset中则直接DROP(子链的默认行为为DROP)。
# ipset list cali4-s:VFoIKKR-LOG_UuTlYqcKuboName: cali4-s:VFoIKKR-LOG_UuTlYqcKuboType: hash:ipRevision: 4Header: family inet hashsize 1024 maxelem 1048576Size in memory: 280References: 1Number of entries: 4Members:197.19.38.143197.19.26.7197.19.186.199197.19.38.144到这里终于真相大白了,Calico是通过iptables + ipset实现多网络隔离的,同一个网络的IP会加到同一个ipset集合中,不同网络的IP放到不同的ipset集合中,最后通过iptables的set模块匹配ipset集合的IP,如果class="lazy" data-src IP在指定的ipset中则允许通过,否则DROP。
5.5 Calico跨网段通信
我们知道Flannel host-gw不支持Node主机跨网段,Calico是否支持呢,为此我增加了一个node-4(192.168.0.33/24),显然和其他三个Node不在同一个子网。
在新的Node中启动一个busybox:
docker run -d --name busybox-node-4 --net calico-net-1 busybox sleep 36000
docker exec busybox-node-4 ping -c 1 -w 1 197.19.38.144
PING 197.19.38.144 (197.19.38.144): 56 data bytes
64 bytes from 197.19.38.144: seq=0 ttl=62 time=0.539 ms
--- 197.19.38.144 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.539/0.539/0.539 ms
验证发现容器通信时没有问题的。
查看node-1路由:
# ip r | grep 197.19197.19.26.0/26 via 192.168.1.245 dev eth0 proto birdblackhole 197.19.38.128/26 proto bird197.19.38.142 dev cali459cc263d36 scope link197.19.38.143 dev cali6d0015b0c71 scope link197.19.38.144 dev calic8e5fab61b1 scope link197.19.65.128/26 via 192.168.0.33 dev tunl0 proto bird onlink197.19.186.192/26 via 192.168.1.254 dev eth0 proto bird和其他路由不一样的是,我们发现197.19.65.128/26是通过tunl0出去的:
# ip -d link show tunl05: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0 ipip any remote any local any ttl inherit nopmtudisc addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535# ip -d tunnel showtunl0: any/ip remote any local any ttl inherit nopmtudisc由此可知,如果节点跨网段,则Calico通过ipip隧道传输,相当于走的是overlay。
对比Flannel host-gw,除了静态与BGP动态路由配置的区别,Calico还通过iptables + ipset解决了多网络支持问题,通过ipip隧道实现了节点跨子网通信问题。
另外,某些业务或者POD需要固定IP,比如POD从一个节点迁移到另一个节点保持IP不变,这种情况下可能导致容器的IP不在节点Node上分配的子网范围内,Calico可以通过添加一条32位的明细路由实现,Flannel不支持这种情况。
因此相对来说Calico实现的功能相对要多些,但是,最终也导致Calico相对Flannel要复杂得多,运维难度也较大,光一堆iptables规则就不容易理清了。
六、与OpenStack网络集成的Kuryr
Kuryr是OpenStack中一个较新的项目,其目标是“Bridge between container framework networking and storage models to OpenStack networking and storage abstractions.”,即实现容器与OpenStack的网络集成,该方案实现了与虚拟机、裸机相同的网络功能和互通,比如多租户、安全组等。
网络模型和虚拟机基本一样,唯一区别在于虚拟机是通过TAP设备直接挂到虚拟机设备中的,而容器则是通过VETH连接到容器的namespace。
vm Container whatever
| | |
tapX tapY tapZ
| | |
| | |
qbrX qbrY qbrZ
| | |
---------------------------------------------
| br-int(OVS) |
---------------------------------------------
|
----------------------------------------------
| br-tun(OVS) |
----------------------------------------------
感谢你能够认真阅读完这篇文章,希望小编分享的“主流Docker网络的实现原理是什么”这篇文章对大家有帮助,同时也希望大家多多支持编程网,关注编程网行业资讯频道,更多相关知识等着你来学习!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














