

Router-Based HDFS Federation在滴滴大数据中如何应用

这篇文章给大家分享的是有关Router-Based HDFS Federation在滴滴大数据中如何应用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
一、背景
HDFS 的 Master/Slave 架构,使得其具有单点瓶颈,即随着业务数据的大规模膨胀,Master 节点在元数据存储与提供服务上都会存在瓶颈。为了克服 HDFS 单点瓶颈存在的扩展性、性能、隔离问题,社区提出了Federation(https://issues.apache.org/jira/browse/HDFS-1052 )方案来进行解决。
但是使用该方案之后,暴露给客户的问题就是,同一个集群出现了多个命名空间(namespace),客户需要知道读写的数据在哪个命名空间下才可以进行操作。为了解决统一命名空间的问题,社区提出了基于客户端(client-side)的解决方案 ViewFS(https://issues.apache.org/jira/browse/HADOOP-7257 ),该方案会在客户端做好配置,用户目录一对一的挂载到具体的命名空间目录上,滴滴在解决 Federation 问题时使用的就是这个方案。
ViewFS 方案也存在一些问题:
对于已经发布出去客户端升级比较困难;
对于新增目录需要增加挂载配置,与产品对接,维护起来比较困难。
社区在 2.9 和 3.0 版本中发布了一个新的解决统一命名空间问题的方案 Router-Based Federation(https://issues.apache.org/jira/browse/HDFS-10467 ),该方案是基于服务端进行实现的,在升级管理方面比较好维护,滴滴最近引入了该方案,并进行了一些改造。
二、Router-Based Federation 方案介绍
Router-Based Federation 对外提供了 Router 服务,包含在 Federation layer 中,如下图所示。这个 Router 服务将允许用户透明地访问任何子集群,让子集群独立管理自己的 Blockpool。为了实现这些目标,Federation layer 必须将 Block 访问引导至适当的子群集。同时,它具有可扩展性,高可用性和容错性。
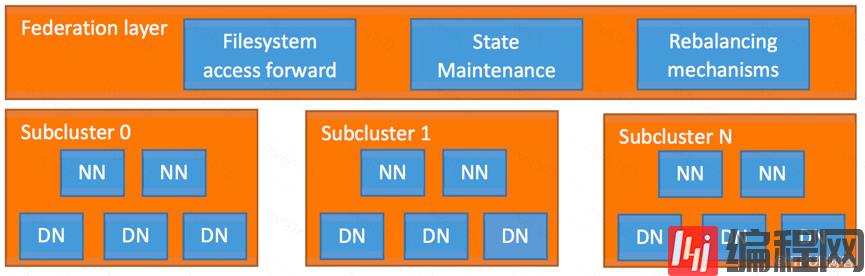
Federation layer 包含多个组件。Router 是一个与 Namenode 具有相同接口的组件,根据 State Store 的元数据信息将客户端请求转发给正确的子集群。State Store 组件包含了远程挂载表(具有 ViewFS 特性,但在客户端之间共享)和有关 SubCluster 的负载/空间信息。
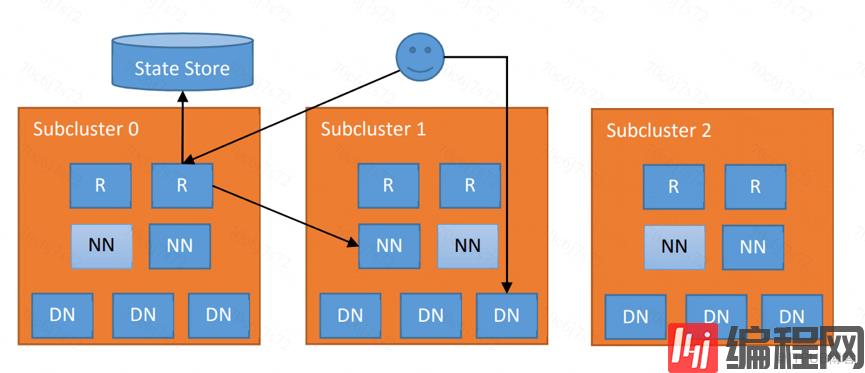
下图架构中显示每个子集群增加了 Router(标记为“R”)和逻辑集中式(但物理分布式)的状态存储(State Store),以及每个 SubCluster 的 Namenodes(“NN”)和 Datanodes(“DN”)。这种方法与 YARN Federation(YARN-2915)具有相同的架构。
2.1 Router 组件
系统中可以有多个的 Router,每个 Router 有两个角色:
向客户端提供一个全局 Namenode 接口并负责转发请求正确的子群集中的 Active Namenode;
在 State Store 中维护关于 Namenode 的信息。
Router 在收到客户端请求,根据 mount-table 中的信息查找正确的子集群,然后转发对该集群请求到对应子集群 Active Namenode。在收到 Active Namenode 的响应结果之后,将结果返回给客户端 。 为了提升性能,Router 可以缓存远程挂载表条目和子集群的状态。
对于 Namenode 信息的维护,Router 定期检查一个 Namenode 的状态和向 State Store 报告其高可用性(HA)状态和负载/空间状态。 为了提高 Namenode HA 的性能,Router 使用 State Store 中的高可用性状态信息,以将请求转发到最有可能处于活动状态的 Namenode。
2.1.1 可用性与容错性
Router 是无状态的,所有 Router 同时提供服务。如果某个 Router 变成不可用,不影响其他任何 Router 提供服务。
客户端配置他们的 DFS HA 客户端(例如 ConfiguredFailoverProvider 或 RequestHedgingProxyProvider)与 Federation 中的所有 Router 配合使用。
为了实现高可用性和灵活性,多个 Router 可以监控相同的 Namenode 并把心跳发送信息到 State Store。 如果 Router 出现故障,这会增加信息的恢复能力。
2.1.2 Safe Mode
如果 Router 不能连接到 State Store,它可能会错误地提供过期 locations 的访问,让 Federation 进入不一致的状态。
为防止这种情况发生,当 Router 无法连接到 State Store 一段时间后,它会进入安全模式(类似于 Namenode 的 safe mode)。当客户端尝试访问 safe mode 的 Router 时候,会抛出异常,客户端的 Proxy 捕获后,会尝试连接其他的 Router。类似于 Namenode,Router 保持在这个安全模式,直到它确定 State Store 可用为止。
这可以防止 Router 启动时出现不一致。 假定一个 Router 如果在一段时间内没有心跳(例如,心跳间隔的五倍),则它已经死亡或处于安全模式。
2.1.3 交互接口
为了与用户和管理员进行交互,Router 公开了多个接口。包括 RPC、Admin、WebUI 。
RPC 实现了客户端与 HDFS 交互的最常见接口。 目前仅支持使用普通 MapReduce,Spark 和 Hive ( on Tez,Spark 和MapReduce)。一些高级特性,如快照、加密和分层存储在未来版本实现。 所有未实现的功能都会抛出异常。
Admin 为管理员实现的一个 RPC 接口,包括从子集群获取信息、添加/删除条目到 mout table。也可以通过命令行获取和修改 Federation 信息。WebUI 实现了一个可视化 Federation 状态,模仿了当前的 Namenode UI,除此之外,还包含 mout table,每个子集群的成员信息以及 Router 的状态。
2.2 State Store 组件
State Store 维护的信息包括:
子集群的块访问负载,可用磁盘空间,HA 状态等状态;
文件夹/文件和子集群之间的映射,即远程 Mount Table;
Router 的状态。State Store 的后端存储是可配置的。 既可以可以存储在文件中,也可以存在 ZooKeeper 中。
2.2.1 Membership
Membership 反映了 Federation 中的 Namenode 的状态。包括有关子集群的信息,例如存储量和节点数量。Router 定期检测一个或多个 Namenode 的信息。
2.2.2 Mount Table
管理文件夹和子集群之间的映射。 它与 ViewFS 中的 Mount Table 类似:hdfs://tmp → hdfs://C0-1/tmp
2.2.3 Router State
为了跟踪 Router 中 caches 的状态,Router 将其版本信息、状态信息等存储在 State Store 中。
2.3 未来计划
目前 RBF 只是实现了一些基本 Namenode 接口,有些接口并不支持,HDFS-13655(https://issues.apache.org/jira/browse/HDFS-13655 )中会实现一些不支持的协议接口;当前 RBF 的稳定性也还存在一些问题,HDFS-13891(https://issues.apache.org/jira/browse/HDFS-13891 )会跟踪一些稳定性问题进而解决掉。
三、Router-Based Federation 在滴滴的应用
3.1 部署情况
社区 Hadoop 在 2.9 和 3.0 中发布了 RBF 这个 Feature,滴滴目前的 Hadoop 版本是 2.7.2,我们的做法是将 branch-2 分支里关于 RBF 的提交都移植到了我们的代码中,做了一些必要的修改工作。
在滴滴的大数据集群中,Federation 拆成了 5 组 Namenode。经过性能测试,我们得出这样的结论:一个 Router 对应服务一组 Namenode 不存在压力,因此我们选择部署 5 个 Router 来服务整个集群。目前 Router-Based Federation 方案在滴滴已经稳定运行 2 月有余。
3.2 兼容性
直接引入 RBF 在运行 Hive 任务时会出现一些错误,例如 Wrong FS 等等。为此我们将 Hive 客户端代码做了修改,使其兼容 RBF。在 Hive 的元数据存储中,location 信息存储的是带HDFS Schema 的绝对路径信息,在 Hive 代码中处理 move 逻辑时,我们都会将路径做一个 resolve 得到实际的 HDFS 路径,然后再进行处理,这样可以避免该问题的出现。
3.3 RBF 社区贡献
在实际测试中,我们也发现了 RBF 的一些性能问题和 BUG,包括 Quota 问题、mount-table cache 使用不当问题、mount-table 创建 znode 出现 Null 问题等等。在解决这些问题之后,将 patch 贡献给了社区,大部分被社区接收,具体修复和优化如下:
HDFS-13710:https://issues.apache.org/jira/browse/HDFS-13710
HDFS-13821:https://issues.apache.org/jira/browse/HDFS-13821
HDFS-13836:https://issues.apache.org/jira/browse/HDFS-13836
HDFS-13844:https://issues.apache.org/jira/browse/HDFS-13844
HDFS-13845:https://issues.apache.org/jira/browse/HDFS-13845
HDFS-13854:https://issues.apache.org/jira/browse/HDFS-13854
HDFS-13856:https://issues.apache.org/jira/browse/HDFS-13856
HDFS-13857:https://issues.apache.org/jira/browse/HDFS-13857
HDFS-13802:https://issues.apache.org/jira/browse/HDFS-13802
HDFS-13852:https://issues.apache.org/jira/browse/HDFS-13852
HDFS-14114:https://issues.apache.org/jira/browse/HDFS-14114
感谢各位的阅读!关于“Router-Based HDFS Federation在滴滴大数据中如何应用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341


















