

Canal+Kafka实现Mysql数据同步


Canal介绍
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据。
canal是应阿里巴巴存在杭州和美国的双机房部署,存在跨机房同步的业务需求而提出的。
阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
canal主要用途是基于 MySQL 数据库增量日志解析,并能提供增量数据订阅和消费,应用场景十分丰富。
目前canal主要支持mysql数据库。
github地址:https://github.com/alibaba/canal
版本下载地址:https://github.com/alibaba/canal/releases
文档地址:https://github.com/alibaba/canal/wiki/Docker-QuickStart
Canal应用场景
1)、电商场景下商品、用户实时更新同步到至Elasticsearch、solr等搜索引擎;
2)、价格、库存发生变更实时同步到redis;
3)、数据库异地备份、数据同步;
4)、代替使用轮询数据库方式来监控数据库变更,有效改善轮询耗费数据库资源。


MySQL主从复制原理
1)、MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
2)、MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
3)、MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
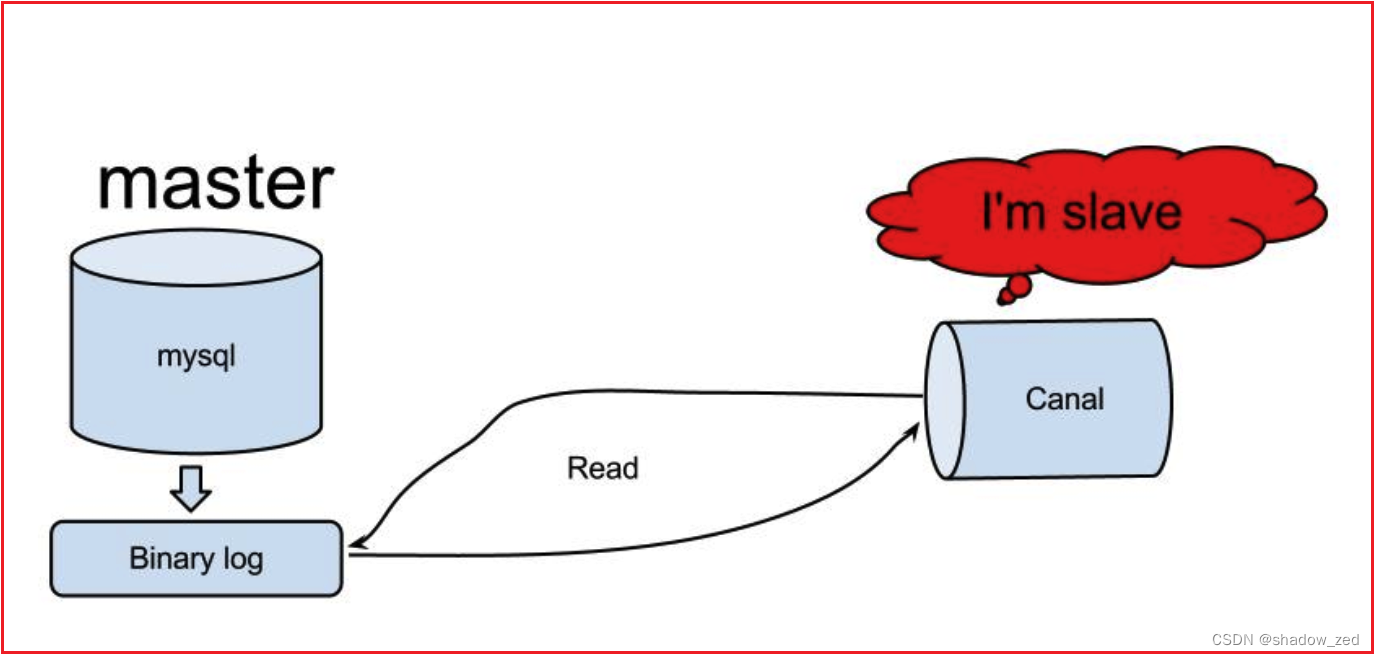
Canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
![]()
![image.png]() Canal安装
Canal安装
 Canal安装
Canal安装参考文档:https://github.com/alibaba/canal/wiki/QuickStart
Canal配置
mq相关参数说明 (>=1.1.5版本)
在1.1.5版本开始,引入了MQ Connector设计,参数配置做了部分调整
| 参数名 | 参数说明 | 默认值 |
|---|---|---|
| canal.aliyun.accessKey | 阿里云ak | 无 |
| canal.aliyun.secretKey | 阿里云sk | 无 |
| canal.aliyun.uid | 阿里云uid | 无 |
| canal.mq.flatMessage | 是否为json格式 如果设置为false,对应MQ收到的消息为protobuf格式 需要通过CanalMessageDeserializer进行解码 | false |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.accessChannel = local | 是否为阿里云模式,可选值local/cloud | local |
| canal.mq.database.hash | 是否开启database混淆hash,确保不同库的数据可以均匀分散,如果关闭可以确保只按照业务字段做MQ分区计算 | true |
| canal.mq.send.thread.size | MQ消息发送并行度 | 30 |
| canal.mq.build.thread.size | MQ消息构建并行度 | 8 |
|---|---|---|
| kafka.bootstrap.servers | kafka服务端地址 | 127.0.0.1:9092 |
| kafka.acks | kafka为 | all |
| kafka.compression.type | 压缩类型 | none |
| kafka.batch.size | kafka为 | 16384 |
| kafka.linger.ms | kafka为 | 1 |
| kafka.max.request.size | kafka为 | 1048576 |
| kafka.buffer.memory | kafka为 | 33554432 |
| kafka.max.in.flight.requests.per.connection | kafka为 | 1 |
| kafka.retries | 发送失败重试次数 | 0 |
| kafka.kerberos.enable | kerberos认证 | false |
| kafka.kerberos.krb5.file | kerberos认证 | ../conf/kerberos/krb5.conf |
| kafka.kerberos.jaas.file | kerberos认证 | ../conf/kerberos/jaas.conf |
|---|---|---|
| rocketmq.producer.group | rocketMQ为ProducerGroup名 | test |
| rocketmq.enable.message.trace | 是否开启message trace | false |
| rocketmq.customized.trace.topic | message trace的topic | 无 |
| rocketmq.namespace | rocketmq的namespace | 无 |
| rocketmq.namesrv.addr | rocketmq的namesrv地址 | 127.0.0.1:9876 |
| rocketmq.retry.times.when.send.failed | 重试次数 | 0 |
| rocketmq.vip.channel.enabled | rocketmq是否开启vip channel | false |
| rocketmq.tag | rocketmq的tag配置 | 空值 |
|---|---|---|
| rabbitmq.host | rabbitMQ配置 | 无 |
| rabbitmq.virtual.host | rabbitMQ配置 | 无 |
| rabbitmq.exchange | rabbitMQ配置 | 无 |
| rabbitmq.username | rabbitMQ配置 | 无 |
| rabbitmq.password | rabbitMQ配置 | 无 |
| rabbitmq.deliveryMode | rabbitMQ配置 | 无 |
|---|---|---|
| pulsarmq.serverUrl | pulsarmq配置 | 无 |
| pulsarmq.roleToken | pulsarmq配置 | 无 |
| pulsarmq.topicTenantPrefix | pulsarmq配置 | 无 |
|---|---|---|
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.enableDynamicQueuePartition | 动态获取MQ服务端的分区数,如果设置为true之后会自动根据topic获取分区数替换canal.mq.partitionsNum的定义,目前主要适用于RocketMQ | false |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.dynamicTopicPartitionNum | mq里的动态队列分区数,比如针对不同topic配置不同partitionsNum | 无 |
| canal.mq.partitionHash | 散列规则定义 库名.表名 : 唯一主键,比如mytest.person: id 1.1.3版本支持新语法,见下文 | 无 |
canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test\\.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:.*\\..* 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test\\..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1\\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test\\.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:.*\\..* 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test\\..* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1\\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.*\\..*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.*\\..*:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.*\\..* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- •
按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- •
- 例子6: test\\.test:id,.\\..* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
其他详细参数可参考Canal AdminGuide
mq顺序性问题
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
- 1.
canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
- 2.
canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
- 1.
canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
性能表现
Kafka + 混合DML场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 | 2个topic+1分区 | 2个topic+3分区 |
|---|---|---|---|---|
| 不开启flatMessage | 6k rps (9.71k tps) | 54k rps (6.53k tps) | 6k rps (7.9k tps) | 8k rps (5.71k tps) |
| 开启flatMessage | 79k rps (4.36k tps) | 97 rps (5.94k tps) | 91k rps (4.45k tps) | 96k rps (6.26k tps) |
Kafka + 单表的batch insert场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 |
|---|---|---|
| 不开启flatMessage | 6k rps | 1k rps |
| 开启flatMessage | 3k rps | 6k rps |
RocketMQ + 混合DML场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 | 2个topic+1分区 | 2个topic+3分区 |
|---|---|---|---|---|
| 不开启flatMessage | 6k rps (10.71k tps) | 3k rps (8.59k tps) | 7k rps (9.46k tps) | 7k rps (7.66k tps) |
| 开启flatMessage | 75k rps (6.17k tps) | 96k rps (5.55k tps) | 83k rps (6.63k tps) | 93k rps (6.26k tps) |
RocketMQ + 单表的batch insert场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 |
|---|---|---|
| 不开启flatMessage | 2k rps | 3k rps |
| 开启flatMessage | 6k rps | 9k rps |
附录:
canal官方文档:https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
Canal+MQ性能表现:https://github.com/alibaba/canal/wiki/Canal-MQ-Performance
参考文档:https://www.cnblogs.com/zwh0910/p/17043265.html
来源地址:https://blog.csdn.net/shadow_zed/article/details/132209818
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341



![[mysql]mysql8修改root密码](https://static.528045.com/imgs/3.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









