

DevOps元数据管理


元数据是自动化运维的基础,对元数据的管理和查询贯穿整个运维的生命周期。我们从一个元数据的使用场景开始:
双十一抢购火热进行中,某电商后端实例的日志中出现了502错误码,运维平台监测到该异常并发送告警给相关运维。
在这个过程中,运维元数据发挥了什么作用?回答这个问题前,我们先回顾下元数据是什么。
一、元数据的管理
运维系统中的元数据包括服务、机器及其关联关系。服务元数据有服务名称、所属节点、运维人员以及域名等;机器元数据包含序列号、内存等资产信息,IP、机房等网络信息、自定义标签信息以及运行实例等部署信息。这些数据由资源管理模块维护。
资源管理模块对业务以树的形态划分层级,形成服务树,从上到下依次为产品线、系统和应用三类节点。
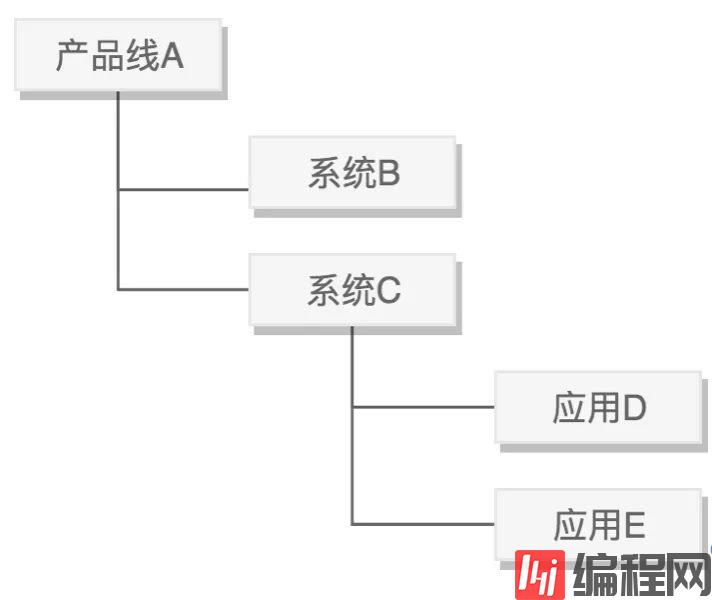
每个层级都可以关联机器,且上层节点包含下层节点的机器。
通过添加节点的运维及研发角色,可以实现对服务和机器的权限控制。
这种层级结构将服务与服务,服务与机器关联起来,可以直观的表达服务和机器的归属关系,便于实现权限和配置的继承。
二、元数据的应用场景
智能监控
回到上面的问题,报警流程中,服务所在机器的监控客户端查询自己所属的应用,然后从配置管理模块拉取相应监控配置,实现对日志的监控;监控业务端收到监控数据后,查找该机器对应的节点信息,将报警发送给节点的运维等人员。
此外,在DevOps落地实践中,还存在多种其他应用场景
拓扑视图
服务间关系拓扑可由远程过程调用协议(RPC)间的调用关系链自动更新或者在应用上简单维护服务间上下游关系。根据RPC调用关系链自动更新的关系拓扑图主要用在业务运维上,可以帮助运维人员进行故障诊断,对整个业务系统运行状态和部署架构全局一览,清晰便捷. 应用上手工维护服务间上下游关系,可以用于上线版本依赖控制。上线申请单中指定上线版本依赖服务的版本,上线时系统自动检查依赖的版本是否已经完成上线,如果依赖版本未上线,终止本次操作。
批量运维
基于应用服务树节点及权限,规范化批量任务执行操作。日常运维过程中,运维需要对线上机器进行一些批量操作,比如升级软件版本、打补丁,清理日志等。为了避免手工操作带来的风险,只允许运维同学,选择所属权限目标机器,进行操作。对于高危命令,可添加审批机制,增加流程规范。
堡垒机
当机器规模、人员规模逐渐扩大时,如何管理人、机器、权限会变得很复杂。通过元数据的动态管理,用户只需要在服务树上对人员进行角色设置,即可登录堡垒机,获得自己有权限的列表。通过服务树的角色同样可以添加哪些角色拥有su权限等访问策略控制。
持续交付
持续集成、自动化测试、持续交付都可以基于元数据,实现数据的唯一性管理。研发侧,提交代码,自动触发服务树应用对应的编译任务,根据编译规范生成部署包,放到版本库;运维侧,则对资源进行分配抽象到服务树,将版本库里面的代码发布到服务树实例对应的机器上;对于用户侧,通过负载均衡的接入,可以动态的进行服务树实例流量的开关和扩缩容;部署日志则可以按照应用日志服务模块进行检索,方便排查问题。
三、元数据的查询
在上面的监控流程中,客户端和业务端是机器和服务关系数据的消费方,现实的运维场景中,二者也是运维数据的主要需求方。
客户端指安装在机器上,用以执行特定任务的程序,其需要的数据包括当前机器相关的信息,如机器机房、机架等设备属性和归属节点、部署服务等业务属性。
业务端主要指运维平台中的上层系统,比如监控、部署等,当然也有跨平台的其他系统,其需求涵盖服务、机器与权限之间的相互查询。
大规模运维场景中元数据查询面临的压力
生产环境中,客户端需要频繁发起查询请求,以保证其数据的准确性。持续增长的机器规模给系统带来的压力不容小觑。业务端由于复杂多样的业务场景,其查询条件多种多样,查询频率和规模无法估量、难以控制,对系统可靠性和可用性提出了较高的要求。
传统关系型数据库难以承受高并发的查询压力,简单的缓存又难以满足条件复杂的查询需求。
如何面对以上压力,提供高效高可用的查询服务,是亟需解决的问题。
实现高可用查询--名字服务
为了应对以上两种场景的挑战,Devops引入了专注于提供数据查询的名字服务,既可以实现服务的解耦,防止外部查询影响资源管理模块的性能,又可以提供高效稳定的查询功能。
服务和机器数据由资源管理模块维护,存储到数据库。名字服务定时从资源管理模块同步数据,直接面向其他业务端和客户端提供查询服务。为提高响应速度,减少IO,元数据以map的形式存储于内存中。
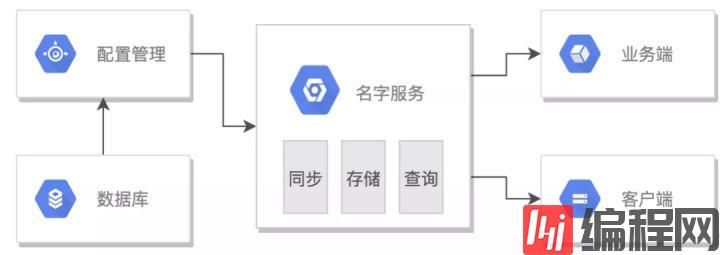
名字服务有三个逻辑层级,分别是同步、存储和查询,我们从这三个方面了解下其如何实现高可用:
保证数据的实效性和服务的可扩展性
同步的流程如下
- 服务启动时:优先从本地存在缓存文件恢复数据,然后增量从资源管理模块同步数据,以减小数据库压力,并快速提供服务;如果没有缓存文件,则从资源管理模块查询全量数据。
- 服务正常运行时:实时与资源管理模块进行增量数据同步,同步的时间点以上次同步的时间戳为准;为进一步保证数据准确,需定期全量同步数据;定期更新缓存文件。
- 若同步数据出现异常:不更新当前数据,仅保存异常时时间戳,以后的每次同步时间点从该时间戳开始。
由于该模块定时从资源管理模块增量/全量更新数据,在保证数据的准确性的同时对数据库的压力是线性且可控的,并且运行过程不依赖其他服务,因此查询压力增加时,可以通过水平扩容来迅速提高请求承载量。
通过缓存热点数据提高查询效率
回顾下开始的那个场景:监控客户端会定期查询获取最新的数据。假设每分钟请求一次,那么10万台机器就带来了上千的 qps,如果每个客户端请求多个接口或者每个机器部署多种客户端,这个数值就会翻倍。
针对这种常用的查询场景,名字服务通过缓存热点数据来提高查询性能。
假设客户端需要通过 ip(也可能是uuid)查询实例列表,而内存中实例是以id为key存储的。如果依次遍历全部实例进行ip匹配,会有一定的性能开销。此时如果有一份ip与实例id的关联关系的缓存,即可首先定位到对应实例的id,然后直接获取id对应实例的详情。
诸如此类的缓存,可以是产品线与机器的归属关系、机房与机器的关联关系以及应用与实例从属关系等。
由于数据同步环节是由名字服务主动发起的,所以该索引可以在每次更新之后重新生成,来保证其准确性。
支持多维度数据查询
上述缓存不能穷举所有查询信息,服务节点和机器的属性(如机房、运行环境等)和标签(如报警策略和其他运维自定义的标识等)都可能成为数据查询的条件。针对此种情况,名字服务在缓存数据时将属性和标签解析为key-value模型,使用规定的请求格式便可实现查询。
格式定义为Key1_value1.Keys_value2.keyN_valueN,其中常规属性的key以大写字母开头,自定义标签的 key以小写字母开头。例如,当名字服务收到格式为Product_trade.Idc_huabei.env_pre的查询请求时,会先根据Product获取trade产品线的机器ID集合,然后与huabei机房的机器ID集合取交集,再根据该ID集合获取机器集合,最后在机器集合中根据标签匹配出pre环境的机器集合。
DevOps将元数据的管理与查询业务分开维护,元数据的变更通过资源管理实现,数据查询通过名字服务实现。
资源管理通过层级结构维护了服务和机器的关系,并通过角色实现权限的划分。
名字服务只依赖资源管理,便于搭建,易于扩容,可以提供稳定的服务;结合业务场景,通过对热数据缓存实现了较高的查询效率;支持多条件查询,满足复杂的业务需求。
欢迎点击“京东云”了解更多精彩内容


免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
DevOps元数据管理
下载Word文档到电脑,方便收藏和打印~
猜你喜欢
DevOps元数据管理
MySQL红黑树索引元数据管理


怎么配置和管理Hive元数据存储

如何通过PHP8的Attributes来管理代码元数据?
如何在PHP8中使用Attributes管理代码元数据?
什么是元数据?元数据库又怎么理解?


Mysql:MySQL数据管理

图形文件元数据管理工具exiv2有什么用
C++ 元编程在元数据管理和动态属性访问中的作用?














