从各个方面来认识和理解Impala的架构设计

宣传部部长
2024-04-23 22:37

欢迎各位小伙伴阅读本篇文章。今天,我一起来全面的认识和理解Impala的架构设计,有需要的小伙伴,可以参考一下。文章里面有很多细节的重要知识,还望小伙伴们认真阅读哦!
我们知道,在实时性要求不是很高的应用场景中,比如,月度统计报表生成等,我们基于传统的HadoopMapReduce来处理海量大数据(包括使用Hive),在各方面表现都还不错,只需要离线处理数据,然后存储结果即可。但是如果在一些实时性要求相对较高的应用场景中,哪怕处理时间能够在原有的基础有大幅度地减少,也能很好地提升用户体验。对于大数据的实时性要求,其实是相对的,比如,传统使用MapReduce计算框架处理PB级别的查询分析请求,可能耗时30分钟甚至更多,但是如果能够使这个延迟大大降低,如3分钟计算出结果,这是很令人震撼的。Impala就是基于这样的需求驱动而出现的。
Impala是Cloudera开发的一款用来进行大数据实时查询分析的开源工具,它能够实现通过我们熟悉的传统关系数据库的SQL风格来操作大数据,数据可以是存储到HDFS或HBase中的。
下面,我们从不同的角度来认识和理解ClouderaImpala:
设计目标
官网给出的介绍是,使用Impala来实现SQLonHadoop,实现对海量数据的实时查询分析,它的优势有如下几点:
快速
可以方便地执行SQL语句,在数秒内返回查询分析结果。
这一点,其实还要依赖于你在HDFS或HBase上存储的数据的规模,依赖于你对Impala系统的配置调优情况,可能还依赖于你写的SQL语句的执行效率。
灵活
可以直接查询存储在HDFS上的原生数据,也可以查询经过优化设计而存储的数据,只要数据的格式它们能够兼容MapReduce、Hive、Pig等等。
整合&开放
可以非常容易地与Hadoop系统整合,并使用Hadoop生态系统的资源和优势,也不需要将数据迁移到特定的存储系统就能满足查询分析的要求。
可伸缩性
可以很好地与一些BI应用系统协同工作,如Microstrategy、Tableau、Qlikview,等等。
支持特性
Impala支持的特性,主要包括如下几点:
对ANSI-92SQL标准的支持
Impala支持ANSI-92SQL所有子集,包括CREATE、ALTER、SELECT、INSERT、JOIN、GROUPBY以及子查询。它还支持分区JOIN、常用的聚合函数(SUM、COUNT、MAX、MIN、AVG等等)、topN查询。你使用这些语句时,可以像使用关系数据库中使用的SQL语句一样去设计,很容易上手。
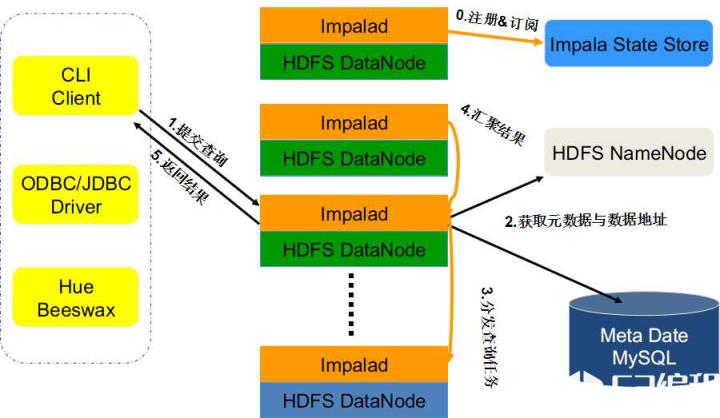
Impala的查询处理过程
Impalad分为java前端与C++处理后端,接受客户端连接的Impalad即作为这次查询的Coordinator,Coordinator通过JNI调用Java前端对用户的查询SQL进行分析生成执行计划树,不同的操作对应不用的PlanNode,如:SelectNode,ScanNode,SortNode,AggregationNode,HashJoinNode等等。
执行计划树的每个原子操作由一个PlanFragment表示,通常一条查询语句由多个PlanFragment组成,PlanFragment0表示执行树的根,汇聚结果返回给用户,执行树的叶子结点一般是Scan操作,分布式并行执行。
Java前端产生的执行计划树以Thrift数据格式返回给ImpalaC++后端(Coordinator)(执行计划分为多个阶段,每一个阶段叫做一个PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragment只能由一个Impalad实例执行,如聚合操作),整个执行计划为一执行计划树),由Coordinator根据执行计划,数据存储信息(Impala通过libhdfs与HDFS进行交互。通过hdfsGetHosts方法获得文件数据块所在节点的位置信息),通过调度器(现在只有simple-scheduler,使用round-robin算法)Coordinator::Exec对生成的执行计划树分配给相应的后端执行器Impalad执行(查询会使用LLVM进行代码生成,编译,执行。对于使用LLVM如何提高性能这里有说明),通过调用GetNext()方法获取计算结果,如果是insert语句,则将计算结果通过libhdfs写回HDFS当所有输入数据被消耗光,执行结束,之后注销此次查询服务。
Impala的查询处理流程大概如图所示:
数据来源与数据格式
Impala可以操作HDFS、HBase中存储的数据,支持如下HDFS的支持文件格式:Textfile、SequenceFile、RCFile、Avrofile、Parquet,支持的压缩格式有:Snappy、GZIP、Deflate、BZIP,其中Snappy压缩格式的性能更好一些。
支持的数据访问接口
主要包括Hive所支持的如下接口:JDBCDriver、ODBCDriver、HueBeeswax、ClouderaImpalaQueryUI.,另外,还可以通过CLI接口(也就是ImpalaShell)访问。
Impala与Hive的异同:
数据存储:使用相同的存储数据池都支持把数据存储于HDFS,HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
Hive:依赖于MapReduce执行框架,执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala:把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
Hive:采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala:采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
Hive:在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala:在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
Hive:任务调度依赖于Hadoop的调度策略。
Impala:调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
容错:
Hive:依赖于Hadoop的容错能力。
Impala:在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败,再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不会影响服务。对于StateStore目前只有一个,但当StateStore失效,也不会影响服务,每个Impalad都缓存了StateStore的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
适用面:
Hive:复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
架构设计要点
Impala的架构设计视图,如图所示:
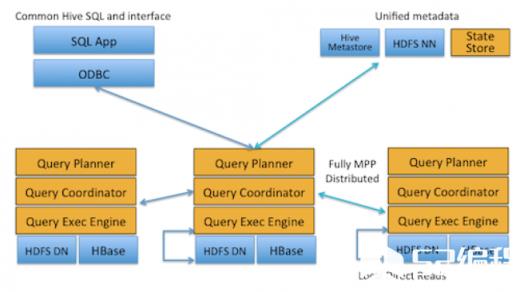
上面可以看出,位于Datanode上的每个impalad进程,都具有QueryPlanner、QueryCoordinator、QueryExecEngine这几个组件,每个Impala节点在功能集合上是对等的,也就是说,任何一个节点都能接收外部查询请求。当有一个节点发生故障后,其他节点仍然能够接管,这还要得益于,在HDFS上,数据的副本是冗余的,只要数据能够取到,某些挂掉的impalad进程所在节点的数据,在整个HDFS中只要还存在副本(impalad进程正常的节点),还是可以提供计算的。除非,当多个impalad进程挂掉了,恰好此时的查询请求要操作的数据所在的节点,都没有存在impalad进程,这是肯定是无法计算了。
ClouderaImpala在实际应用场景中所处的位置,如图所示:
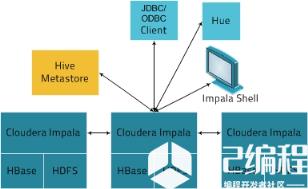
上图展示了Impala方案的相关的各种组件,简单说明如下:
客户端
有三类客户端可以与Impala进行交互:基于驱动程序的客户端(ODBCDriver和JDBCDriver,其中JDBCDriver支持Hive1与Hive2风格的驱动形式);Hue接口,可以通过HueBeeswax接口来与Impala进行交互;ImpalaShell命令行接口,类似关系数据库提供一些命令行即可,可以直接使用SQL语句与Impala交互。
HiveMetastore
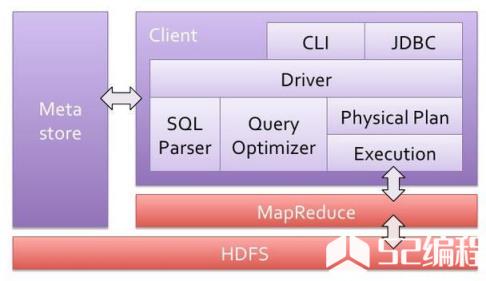
Impala使用HiveMetastore来存储一些元数据,为Impala所使用,通过存储的元数据,Impala可以更好地知道整个集群中数据以及节点的状态,从而实现集群并行计算,对外部提供查询分析服务。
ClouderaImpala
Impala会在HDFS集群的Datanode上启动进程,协调位于集群上的多个Impala进程(impalad),以及执行查询。在Impala架构中,每个Impala节点都可以接收来自客户端的查询请求,然后负责解析查询,生成查询计划,并进行优化,协调查询请求在其他的多个Impala节点上并行执行,最后有负责接收查询请求的Impala节点来汇总结果,响应客户端。
HBase和HDFS
HBase和HDFS存储着实际需要查询的大数据。
总结
Cloudera官网所言,使用Impala比使用Hive能提高3~90的效率,我们可以参考Cloudera的官网博客。我相信,使用Impala比使用Hive能大大提升计算性能,这是真实的。Impala从发布到现在也不过一年左右时间,它还在发展之中,能有这样的表现我还是感觉很欣慰,至少让我们看到了一些商业系统能够实现的功能已经在开源项目中落地。
在我们使用Impala的过程中,我总结一下遇到的相关问题:
SQL解析
我发现Impala目前在SQL解析方面还有优化的余地,当前的问题,一个是SQL解析速度很慢,另一个是如果SQL比较复杂的话存在硬解析的问题,非常耗时。虽然和现在更加成熟的关系数据库Oracle、MySQL等还有一定差距,但是我相信这些只是时间问题。
稳定性
可能是因为依赖于Hive的原因,通过Thrift接口来与后端进行交互,并发性比较差。当并发稍微高一点点的时候,就会出现impalad进程挂掉的问题,有时候可能还会出现类似的僵尸进程。
以笔者愚见,其实对大数据分析的项目来说,技术往往不是最关键的。例如Hadoop中的MapReduce和HDFS都是源于Google,原创性较少。事实上,开源项目的生态圈,社区,发展速度等,往往在很大程度上会影响Impala和Shark等开源大数据分析系统的发展。
想要了解更多详细内容尽在编程学习网哦!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341