

基于Python的selenium

一、安装
1.1安装Python,安装Python时需要勾选增加环境变量
如果之前已经安装过Python,需要将Python相关文件以及环境变量删除
1.2安装成功:在命令行界面下输入Python,最终展示>>>即可成功
2.1安装pycharm,直接自定义安装即可
3、安装selenium
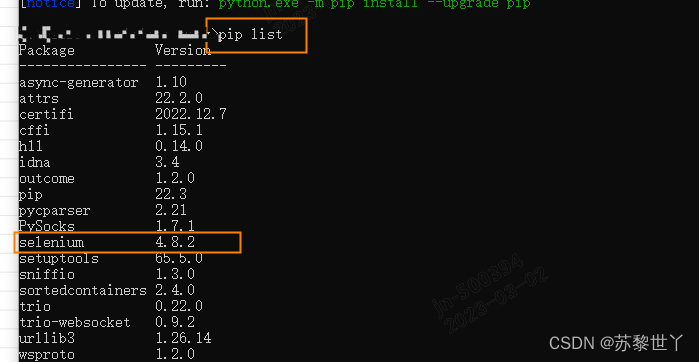
命令行界面,输入pip install selenium

再次输入pip list 看下安装列表是否有selenium,如果有,就安装成功
二、各个浏览器驱动下载
1、谷歌浏览器
1找到谷歌浏览器的版本,设置-关于Chrome,进行查看
1.2进入以下网址,根据Windows系统进行下载谷歌浏览器驱动器
谷歌浏览器驱动下载
建议:将所有浏览器的驱动放到一个文件夹中,进行管理—最后将该driver文件的路径添加到系统环境变量path中
2、火狐浏览器
1 进入以下网址,下载火狐浏览器驱动当前系统下最新的驱动即可
火狐浏览器驱动地址
3、Edge浏览器驱动
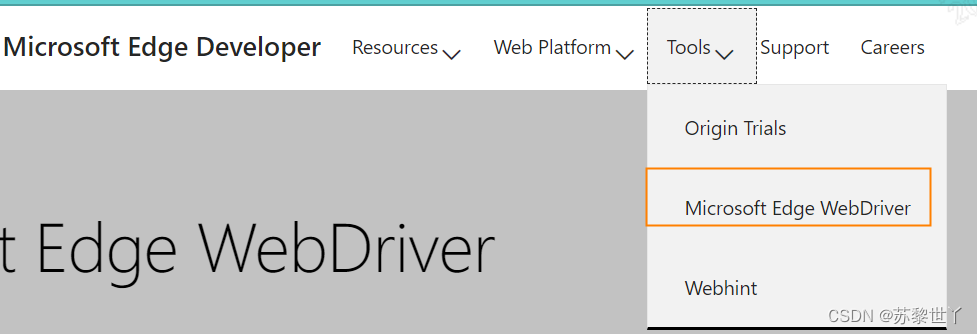
1找到Edge的版本,点击浏览器右上角“···”,选择“帮助和反馈”,点击“关于Microsoft Edge”,查看浏览器版本
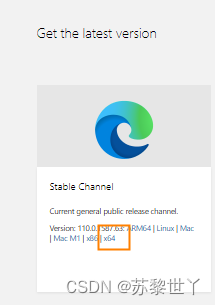
3.2,点击下面链接,下载对应的驱动
Edge浏览器驱动
三、selenium使用
1、下载好驱动器,添加好路径后,使用基础的代码进行浏览器驱动的调试
rom selenium import webdriverfrom selenium.webdriver.common.by import Byimport time#不同浏览器驱动'''driver = webdriver.Firefox()driver = webdriver.Edge()'''driver = webdriver.Chrome()# 打开浏览器窗口driver.get("https://www.baidu.com/")driver.find_element(By.ID, "kw").click()driver.find_element(By.ID, "kw").send_keys("hello word")# 停留当前页面3秒钟time.sleep(3)driver.quit()发现控制台并不报错,但是无法调用浏览器
此时,方法一是可以关闭pycharm,重新启动一次,再次运行即可正常
webelement.click()实际上是点击元素正中间
可以使用webelement.clear()清空输入框已输入内容
webelement.text可以获取展示在页面上的文本内容
get_attribute(‘属性名称’),如class ,可以获取class的值
也可以使用get_attribute(‘placeholder’)验证默认提示语是否正确
2、爬虫应用:
page_source方法用于获取页面源码,同re模块进行结合,使用正则表达式进行爬取,re模块的使用放入Python基础语法了解(加入链接)
3、等待机制
背景:在测试过程中遇到页面加载较慢时测试人员需要等待加载后才能继续操作;也存在点击按钮后出现弹窗,测试人员继续操作;同时存在程序Bug 导致页面无法加载成功,均需要测试人员进行等待,selenium提供了完善的等待机制应对以上场景
分类:页面级等待机制、元素级等待机制、校本级等待机制
4、点击元素
向元素输入内容:webElement.send_keys(“要输入的内容”)
用于
支持输入内容,上传文件(一般用于输入框元素:input)
上传文件时()内放置本地的文件路径webElement.send_key(“E:\auto_test\20230505124740_.xlsx”)
5、清空文本框
清空文本框元素:webElement.clear()整个文本框内容全部清空
再使用send.key后面如果直接再次send.key,则文本内容会叠加
6、提交表单
应用场景:有些情况下,无法在页面直接提交表单,只能通过函数将表单内容进行提交driver.find_element(By.ID, "form").submit()
可以不触发提交按钮,而是通过代码直接提交↑↑↑↑↑
7、下拉框选择
同基础的“单击、输入、清空、提交”使用的webelement对象不同,下拉框选择使用Select对象,需要导入
from selenium.webdriver.support.select import Select
下拉框的类别:单选框;多选框
下拉框操作:
- 按照选项文本来选择:
selectWebElement.select_by_visible_text("选项的文本")#按文本选择 - 按照选项值来选择:
selectWebElement.select_by_value("选项的值")#按选项值选择 - 按照选项索引来选择:
selectWebElement.select_by_index(选项的索引)#按选项索引选择,索引从0开始
多选框和单选框的区别:
多选框支持单选框支持的操作,也支持取消
selectWebElement.deselect_all()#取消所有选择
selectWebElement.deselect_by_visible_text("选项的文本")#按文本取消选择
selectWebElement.deselect_by_value("选项的值")#按选项值取消选择
selectWebElement.deselect_by_index(选项的索引)#按选项索引取消选择,索引从0开始
四、项目经验
1、报错
1.1、参与不同项目时,发现了一个文件,requirements.txt,需要在命令行中运行该文件,但是身为小白找不到运行的位置,所以先搜索了一下该文件的用途是什么
背景:项目需要下载很多包时,需要不断用 pip命令去下载,找到一个更高效的方法,一次性下载所有Python包
保存数据内容:当前项目中所需要的Python包集合
用途:可以一次性将该文件中的需要用的包全部下载
格式: 包名==版本号
使用:
1、手动维护:在项目根目录下,创建文件名为: requirements.txt 的文件,以包名==版本号输入,每一行一个依赖包,如:pytest==6.2.5
应用场景:项目正在维护阶段,会不断增加包/依赖包较少
2、使用命令一次性维护进入项目:终端输入:pip freeze > requirements.txt
应用场景:项目已经完成/依赖包较多
3、一次性下载该文件的依赖包:终端输入: pip install -r ./requirements.txt ,可以自动下载;包已存在也没关系,会自动覆盖
再次打开Python 解释器,就可以看到文件中的依赖包了
1.2 、接上个问题,找不到命令行运行位置
在网上搜索了下,找到Python项目所在文件,在文件路径中输入cmd,然后回车,命令行界面就会展示出来,可以使用上面的命令试试
2.1也可以直接打开pycharm,打开requirements.txt文件,文件上方有提示语,可以直接按照提示语进行安装
1.3、安装pandas的包时提示error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: https://visualstudio.microsoft.com/visual-cpp-build-tools/
原因:这个包中有C++的内容,这部分内容需要先编译才能安装,没有安装C++的平台
解决办法1: 安装Microsoft C++ Build Tools软件
解决办法2:
2.1 首先在终端安装wheel:pip install wheel,终端提示安装成功后,
2.2 在whl文件下载网站中找到对应需要下载的包(如本次安装pandas,就在浏览器中搜索pandas,找到对应的包,pandas-1.4.3-cp311-cp311-win_amd64.whl,cp311—Python3.11版本;amd64----win 系统64位)
2.3 找到后,放入项目文件下,再次使用pip install 文件名,如:pip install pandas-1.4.3-cp311-cp311-win_amd64.whl,安装,然后提示安装成功
2.4 再次运行pip install -r requirements.txt ,提示
ERROR: pandas-1.4.3-cp310-cp310-win_amd64.whl is not a supported wheel on this platform.
发现是下载的包和python版本不一致
使用pip debug --verbose查看Python对应版本,重新下载后,重新执行命令,可以安装成功,
再次执行pip install -r requirements.txt ,依然报相同的错—最终结果失败
1.4运行时提示:Message: element click intercepted: Element ... is not clickable at point (277, 189). Other element would receive the click:
出现原因:项目中某个页面加载慢,导致某个元素无法点击,并且提示如上内容
出现现象:
场景:等待页面1跳转到页面2,点击页面2的新增按钮,但页面2加载过慢,导致实际上看到的是,页面2未完全加载出来,直接关掉自动化调用的浏览器页面
排查原因:在页面2未完全加载出来时,程序实际上已经运行到,找到新增按钮,点击新增按钮,此时点击新增按钮时报错
网上找到解释:元素定位相互覆盖,元素已经找到,但是无法点击
尝试方法一:使用显性等待方法:
element_to_be_clickable--元素是否可点击vibility _of_ element_ located--元素是否可见presence_of_element_located--元素是否存在之前使用的方法是vibility _of_ element_ located--,更改为element_to_be_clickable依然报相同的错误
尝试方法二:
猜测原因是:点击事件可能被父级元素拦截,需要将Xpath路径改成上面一层,改后,依然不生效
尝试方法三:强制等待,使用time.sleep(2),试下,管用
缺点:降低程序运行效率,且不能永久解决问题
优点:符合实际测试场景,在实际测试中,需要等待页面加载完成后,再进行后续操作
尝试方法四:使用javascript的代码来替代
缺点:不符合测试的实际应用场景,在load未完全加载完成后直接进行后续操作
优点:绕过检查机制,可以百分百解决问题
element = self.browser.find_element(By.XPATH, "//div")self.browser.execute_script("qrguments[0].click()",element)尝试方法五:使用Exception_Condition中的方法进行处理
1.5 运行登录的代码打开浏览器提示data:
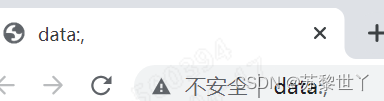
- 猜测原因1:驱动器和谷歌浏览器版本不匹配导致
解决办法一:验证驱动器和浏览器的版本是否一致,然后再次启动验证----验证一致,启动后依然有data提示
办法二:把驱动器放到Python-Script中,重新启动验证----放入后重新启动,依然有data提示 - 猜测原因2:没有设置用户数据目录,需要找一个文件夹存放谷歌数据
补充代码:
from selenium import webdriveroptions = webdriver.ChromeOptions()options.add_argument(r"user-data-dir=此处填任意文件夹路径")browser = webdriver.Chrome(chrome_options=options)browser.get('http://www.baidu.com')再次重新启动----依然有data提示
- 猜测原因三:可能是因为定义了多个驱动,但是没有关闭?
1.6 点完第一个页面的按钮,进入第二个页面点击相同位置的按钮,程序运行时点击第二个,但页面上看来点击的是一个页面的按钮
场景:步骤:页面1新增(填写数据后提交)—>切换至页面2,点击相同位置新增,在弹窗内(填写数据)
运行效果:页面1新增(填写数据后提交)—>切换至页面2,点击相同位置新增,实际出现的弹窗为页面1的弹窗
猜测原因:
1、初步排查页面2按钮Xpath路径错误(实际上路径正确)
2、猜测层级不对,向上找到更高几层的(✘)
3、猜测缺少当前页面是否存在这个元素的判断,所以增加判断后再次运行(✘)
4、猜测缺少该元素是否可点击的判断,所以增加判断后再次运行(✘)
解决办法:
万能time.sleep(2),强制等待后解决了
2、与Jenkins集成
2.1 目的:在合适的机会触发,持续集成的自动化构建、部署、测试,可以最大限度发挥自动化测试的优势
优势:减少人为的遗忘,降低流程中自动化的缺失;提高触发的效率和准确性(在开发提交代码时、或者定期执行,保证及时检验、准时检验)
2.2、持续集成概念介绍
2.2.1 持续集成的概念:在开发周期的每一天,开发同事都会多次集成当天工作的一种模式
2.2.2 自动化集成的概念:自动化构建(包括编译、部署、自动化测试)
2.2.3 持续交付的概念:将集成后的代码自动部署到预生产环境,进行相关测试和验证后,验证通过后手动部署到生产环境的方法
2.2.4 持续部署的概念:即将手动部署生产环境的过程自动化
2.3 jenkins 集成selenium类型
2.3.1 基于代码更新
时间点:开发同事集成代码后,触发自动化执行
前提条件:测试网站代码以及自动化测试代码均放在一个平台上(如GitHub),也放在同一个源地址下
流程:开发同事集成代码到GitHub上,Jenkins会监控到该项目的代码变动,会自动构建、部署,自动化测试此次集成是否影响核心功能
由于当前项目已经在Jenkins上存在,只需要将自动化测试代码部署到Jenkins上,可以在Jenkins上手动执行
步骤:
1、将源码地址放入Jenkins上:
点击item 小三角,选择配置,切换至流水线,在流水线Repository URL中输入自动化测试源码地址,其他内容不做修改
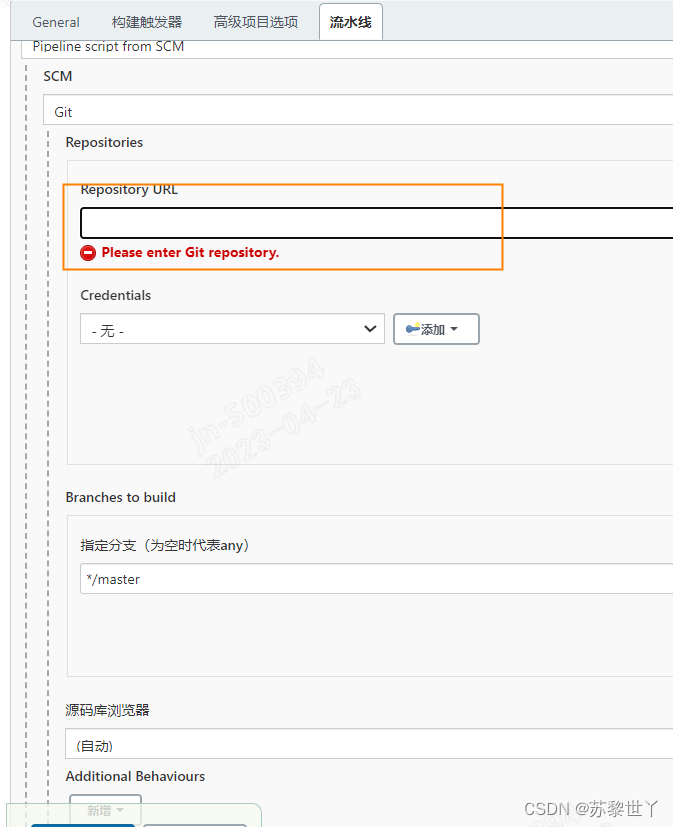
2、设置触发点
切换至“构建触发器”,选择Poll SCM(意义为定时检查源码更新),在日程表中输入H/1* * * *(Jenkins cron语法,代表每隔1小时检查一次),然后点击保存即可
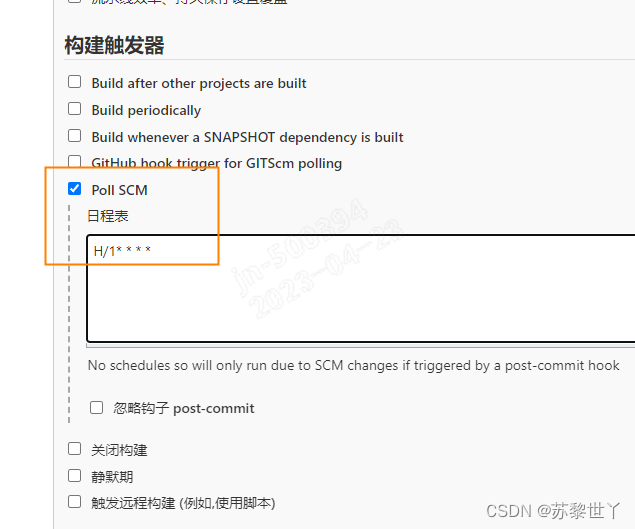
此时修改源码后,Jenkins就会自动执行测试代码进行验证
2.3.2 基于时间定期执行
与基于代码更新不同的是,在设置触发点时,修改为Build periodically(表示基于时间设定,定制执行),填入H/30* * * *”,表示每隔30分钟执行一次,点击保存即可
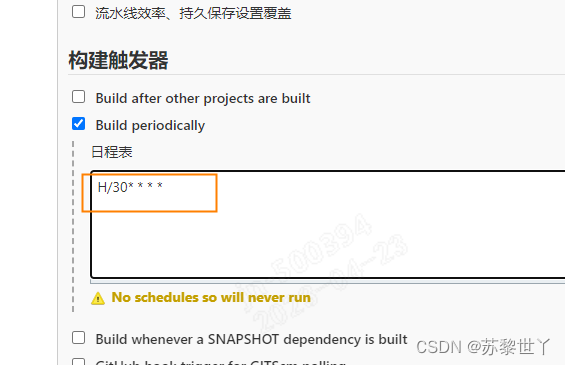
设置成功后,则会每30分钟执行一次自动化测试
4 反馈测试报告
2.4.1 直接使用控制台进行报告
2.4.2 使用测试报告
2.4.3使用邮件进行报告
来源地址:https://blog.csdn.net/weixin_43490695/article/details/129306876
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












