剖析数据的数据采集

宣传部部长
2024-04-23 22:51

编程学习网教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!
我在一次社区活动中做过一次分享,演讲题目为《大数据平台架构技术选型与场景运用》。在演讲中,我主要分析了大数据平台架构的生态环境,并主要以数据源、数据采集、数据存储与数据处理四个方面展开分析与讲解,并结合具体的技术选型与需求场景,给出了我个人对大数据平台的理解。本文讲解数据采集部分。
数据采集的设计,几乎完全取决于数据源的特性,毕竟数据源是整个大数据平台蓄水的上游,数据采集不过是获取水源的管道罢了。
在数据仓库的语境下,ETL基本上就是数据采集的代表,包括数据的提取(Extract)、转换(Transform)和加载(Load)。在转换的过程中,需要针对具体的业务场景对数据进行治理,例如进行非法数据监测与过滤、格式转换与数据规范化、数据替换、保证数据完整性等。
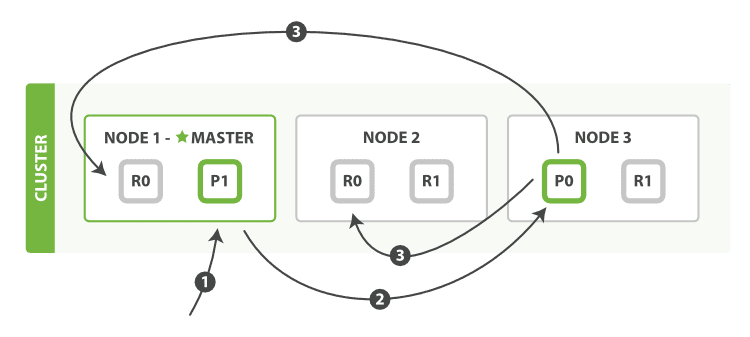
但是在大数据平台下,由于数据源具有更复杂的多样性,数据采集的形式也变得更加复杂而多样,当然,业务场景也可能变得迥然不同。下图展现了大数据平台比较典型的数据采集架构:
以下是几种比较典型的业务场景。

场景1:为了提升业务处理的性能,同时又希望保留历史数据以备数据挖掘与分析。
业务处理场景访问的数据库往往是RDB,可伸缩性较差,又需要满足查询与其他数据操作的实时性,这就需要定期将超过时间期限的历史数据执行清除。但是在大数据场景下,这些看似无用的历史数据又可能是能够炼成黄金的沙砾。因而需要实时将RDB的数据同步到HDFS中,让HDFS成为备份了完整数据的冗余存储。在这种场景下,数据采集就仅仅是一个简单的同步,无需执行转换。
场景2:数据源已经写入Kafka,需要实时采集数据
在考虑流处理的业务场景,数据采集会成为Kafka的消费者,就像一个水坝一般将上游源源不断的数据拦截住,然后根据业务场景做对应的处理(例如去重、去噪、中间计算等),之后再写入到对应的数据存储中。这个过程类似传统的ETL,但它是流式的处理方式,而非定时的批处理Job。
场景3:数据源为视频文件,需提取特征数据
在当今的数字革命浪潮中,大数据成为公司企业分析客户行为和提供个性化定制服务的有力工具,大数据切切实实地帮助这些公司进行交叉销售,提高客户体验,并带来更多的利润。
随着大数据市场的稳步发展,越来越多的公司开始部署大数据驱动战略。
Apache Hadoop是目前最成熟的大数据分析工具,但是市场上也不乏其他优秀的大数据工具。目前市场上有数千种工具能够帮你节约时间和成本,带你从全新的角度洞察你所在的行业。
以下介绍18种功能实用的大数据工具:
Avro:由Doug Cutting公司研发,可用于编码Hadoop文件模式的数据序列化。
Cassandra:一种分布式的开源数据库。可用于处理商品服务器在提供高可用性服务时产生的大量分布式数据。这是一种非关系型数据库(NoSQL)解决方案,最初由Facebook主导研发。
目前很多公司组织都在使用这一数据库,如Netflix,Cisco,Twitter。
Drill:一种开源分布式系统,用于大规模数据集的交互分析。Drill与谷歌的Dremel系统类似,由Apache公司管理运行。
Elasticsearch:Apache Lucene开发的开源搜索引擎。Elasticsearch是基于java的系统,可以实现高速搜索,支持你的数据搜索工作。
Flume:使用网络服务器、应用服务器和移动服务器的数据来填充Hadoop的大数据应用框架,是数据源和Hadoop之间的一种连接纽带。
HCatalog:是针对Apache Hadoop的集中元数据管理和分享服务。可以通过它集中查看Hadoop集群中的所有数据,并可以在不知道数据在集群中存储位置的情况下,通过Pig和 Hive等多种工具处理所有数据元素。
Impala: 使用与Apache Hive相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(HueBeeswax),直接帮助您对存储在HDFS或HBase中的Apache Hadoop数据进行快速的交互式SQL查询。
它为批量导向或实时查询提供了一个方便操作的统一平台。

JSON:今天的许多非关系型数据库(NoSQL)都以JSON(JavaScript对象符号)格式存储数据,这些格式在Web开发人员中很受欢迎。
Kafka:这是种分布式“发布——订阅”的消息传送系统,它能够提供一种解决方案,帮助处理所有数据流活动,并在消费者网站上处理这些数据。
这种类型的数据(包括页面查看数据,搜索数据和其他用户操作数据)是当前社交网络的关键组成部分。
MongoDB:是一个在开源概念指导下开发出来的面向文档的非关系型数据库(NoSQL)。它具有完整的索引支持,同时可以灵活地对任何属性进行索引,并在不影响功能的情况下进行横向扩容。
Neo4j:是一个图形数据库,与关系数据库相比,性能提升高达1000多倍或更高。
Oozie:一种工作流程处理系统,可以让用户自定义不同语言编写的一系列工作,如Map Reduce,Pig 和 Hive。它还可以实现不同工作项目之间的智能连接,Oozie还支持用户指定依赖关系。
Pig:是由雅虎开发的基于Hadoop的一种语言,对于用户来说,学习起来相对简单,且Pig擅长处理非常深入且非常长的数据管道(data pipeline)。
Storm:是一种免费的进行实时分布式计算的开源系统。通过Storm,用户可以非常轻松的在能够进行实时处理操作的范围内,对非结构化数据流进行可靠处理。
系统具有容错特性,支持几乎所有编程语言,当然最常用的语言还是Java。Storm最初是Apache家族的一个分支,现在已被Twitter收购。
Tableau:是一种主要关注商业智能的数据可视化工具。用户无需编程,就可以利用Tableau创建地图,条形图,散点图等可视化图像。
他们最近发布了一个Web连接器,允许用户直接连接数据库或应用程序界面(API),从而使用户能够在进行可视化项目时获取实时数据。
针对视频文件的大数据处理,需要在Extract阶段加载图片后,然后根据某种识别算法,识别并提取图片的特征信息,并将其转换为业务场景需要的数据模型。在这个场景下,数据提取的耗时相对较长,也需要较多的内存资源。如果处理不当,可能会成为整个数据阶段的瓶颈。
在数据采集阶段,一个棘手问题是增量同步,尤其针对那种可变(即可删除、可修改)的数据源。在我们无法掌控数据源的情况下,通常我们会有三种选择:
放弃同步,采用直连形式;

放弃增量同步,选用全量同步;
编写定期Job,扫描数据源以获得delta数据,然后针对delta数据进行增量同步
坦白说,这三种选择皆非最佳选择,但我也未尝发现有更好的方案。如果数据源端可以控制,我们当然也可以侦听数据源的变更,然后执行Job来更新采集后存储的数据。这些又可能牵涉到数据存储的选型,假设我们选择了Parquet格式作为数据存储,则Parquet是不允许变更的。若要应对这种场景,或许应该考虑ORC格式。
为了更高效地完成数据采集,通常我们需要将整个流程切分成多个阶段,在细分的阶段中可以采用并行执行的方式。在这个过程中,可能牵涉到Job的创建、提交与分发,采集流程的规划,数据格式的转换等。除此之外,在保证数据采集的高性能之外,还要考虑数据丢失的容错。
如果大家还想了解更多方面的详细内容的话呢,不妨关注编程学习网教育平台,在这里你肯定会有意想不到的收获的!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341