

MySQL数据库学习


目录
从管理员cmd页面打开数据库
win+R

输入cmd shift+ctrl+enter 进入管理员cmd窗口
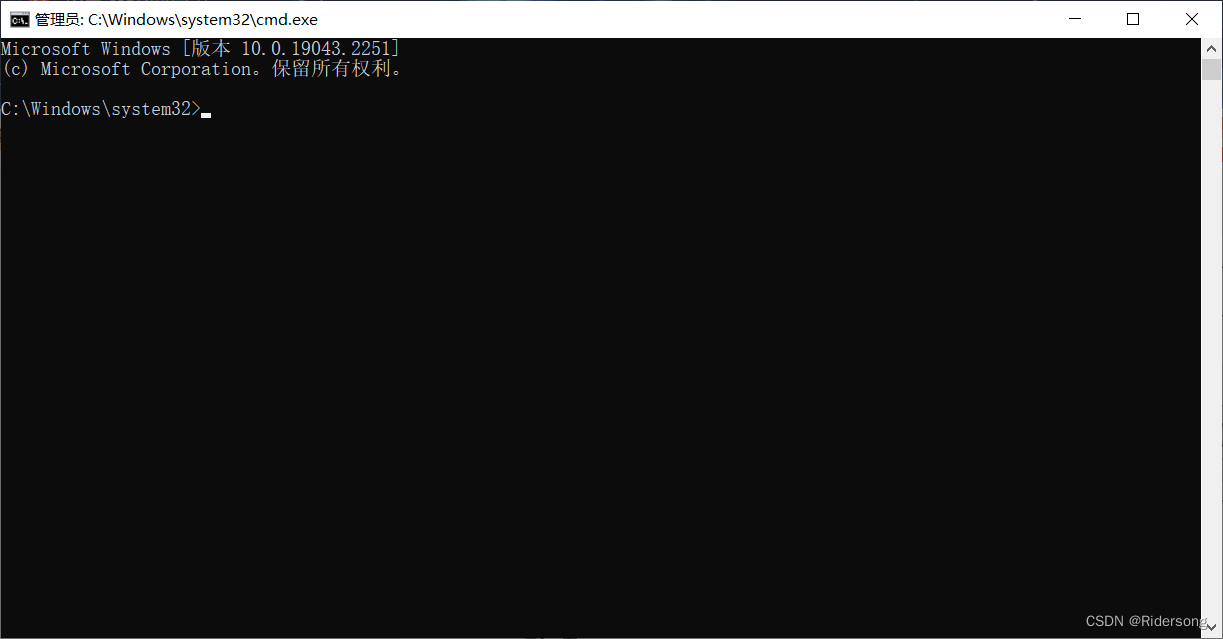
net start mysql80 启动服务器,80表示数据库版本
d: 到D盘
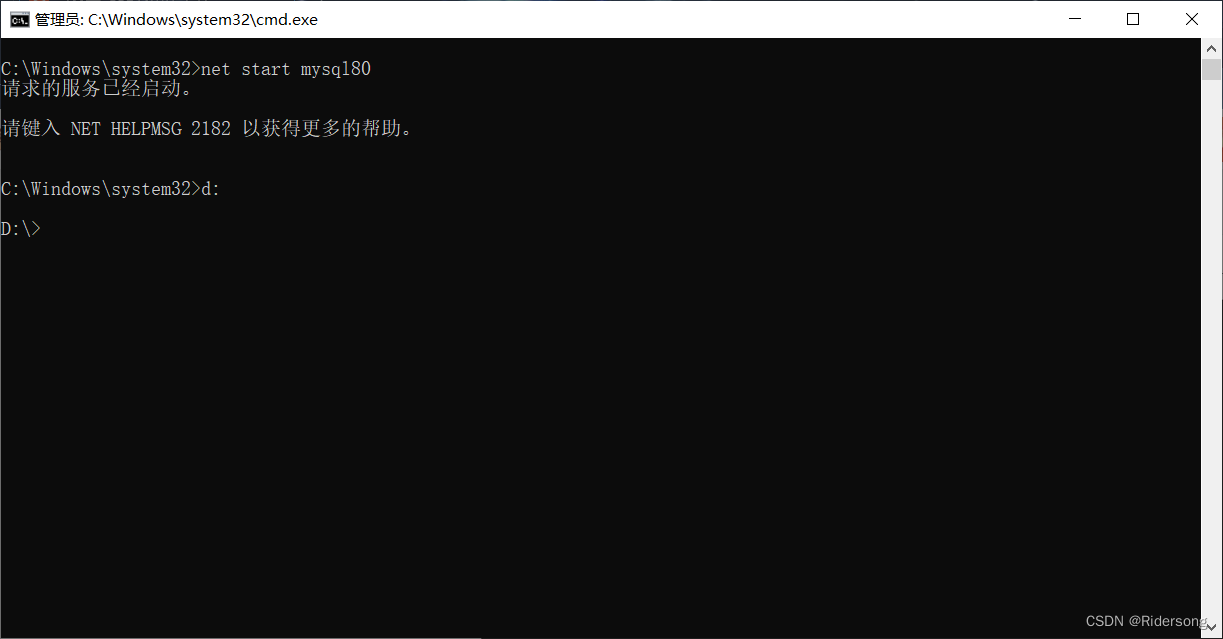
cd D:\JSp\MySQL Server 8.0\bin //定位到bin,你的数据库下在到哪里就定位到哪里

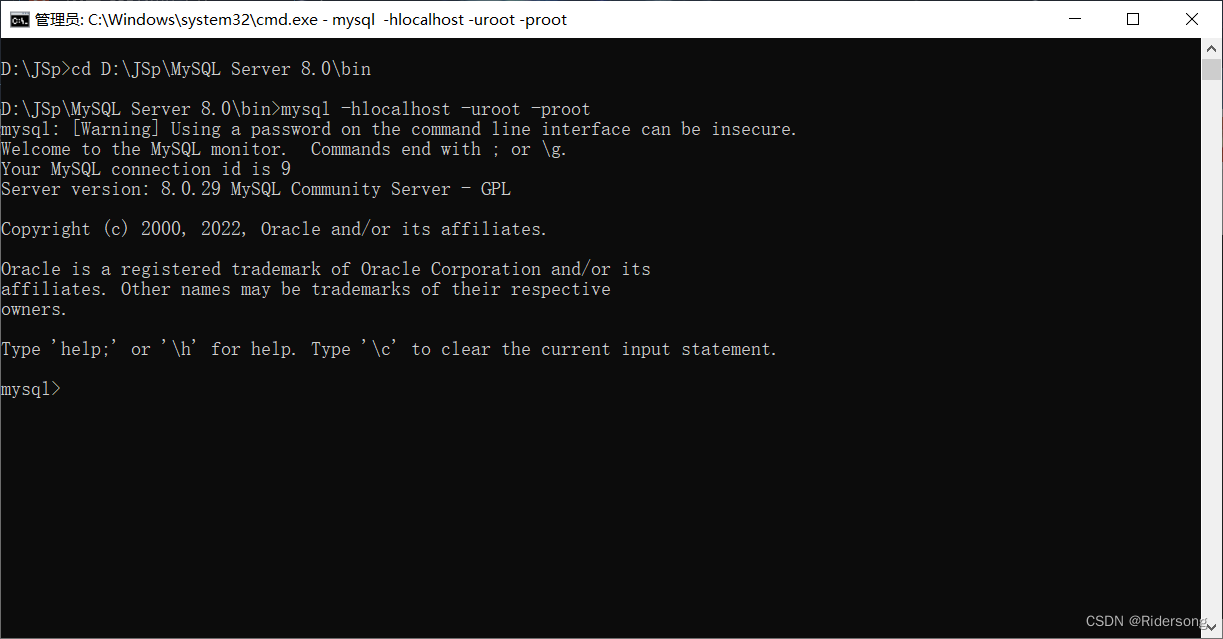
启动数据库:mysql -hlocalhost -uroot -proot //-h 主机名 -u 用户名 -p 密码
创建一个用户
新建一个用户,用户名:Song1,用户主机:localhost,用户密码(可以不设置):ridersong,该用户没有任何权限,需要设置。
create user 'Song1'@'localhost' identified by'ridersong';
数据库的基本操作
创建一个数据库school,if not exists 是判断该数据库是否存在,可以不写:
create database(if not exists) school; 
查看数据库的编码:
show variables like 'character%';
在创建数据库时设置它的字符集编码:
create database tmp default character set utf8;
查看所有的数据库:
show databases;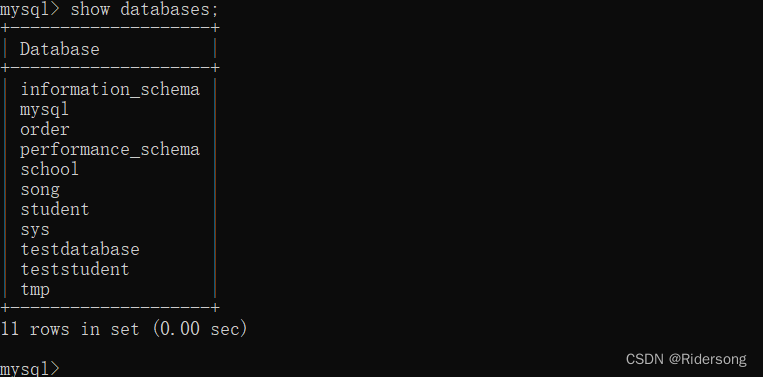
选择数据库,database是要使用的数据库名,必须选择数据库后才能对它里面的数据进行操作:
use database; 
删除数据库:
drop database tmp;
查看数据库支持的存储引擎类型:
show engines; 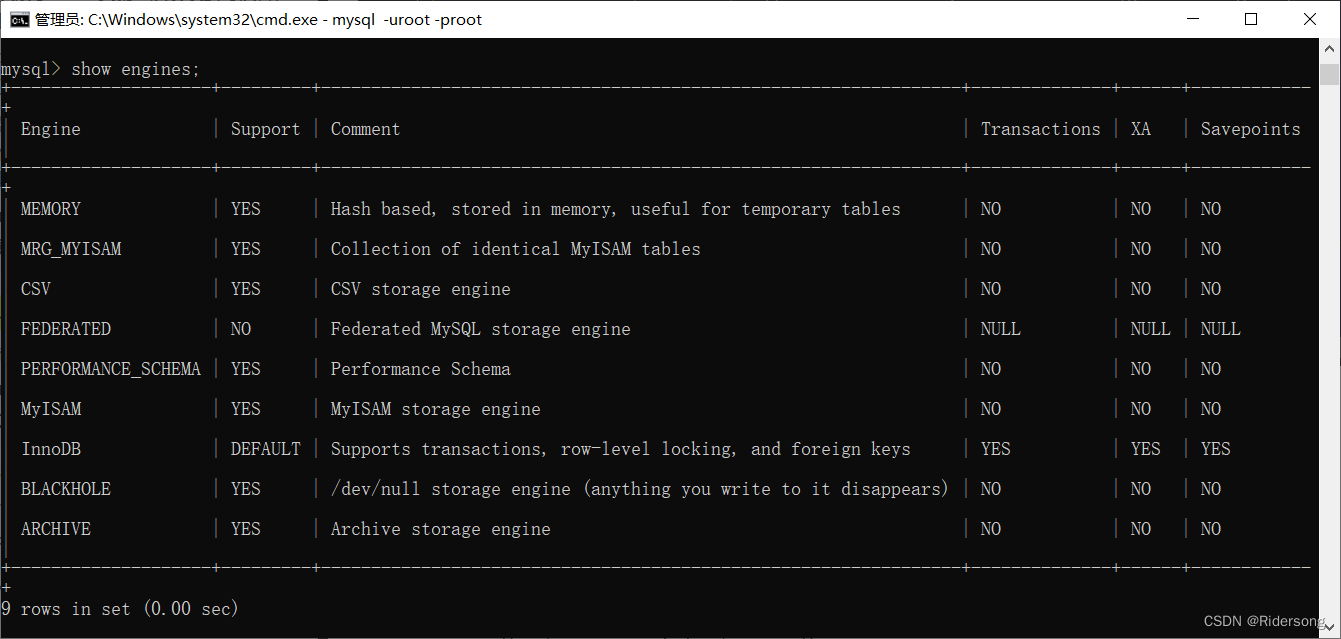
查看默认存储引擎的信息:
show variables like 'default_storage_engine%';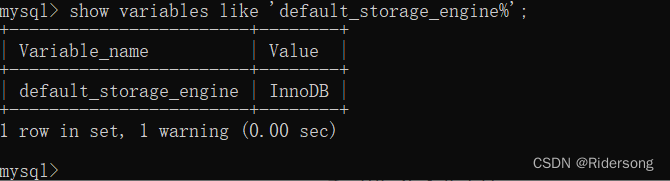
数据完整性
1:域(列)完整性:
列值非空(not null):默认值为null,not null必须输入值
列值唯一(unique):指定表中列保持唯一值,不能出现重复,可以为null
默认值(default):为某一列指定了默认值,当向表中输入数据时,可以不输入该列数据值,采用默认值
2:实体(行)完整性:
主键(primary key)
唯一索引(unique)
自增长列(auto_increment)
3:参照完整性:
外键(foreign key references on delete on update)
4:用户定义完整性
完整性约束管理
constraint 约束名 为约束命名
create table 表名( <字段1><数据类型>[<列级约束>] //对一个数据列建立的约束叫列级约束 ..... [<表级约束>] //对多个数据列建立的约束叫表级约束 ); 一般情况下,not null 和default 使用列级约束;主键,外键和唯一约束既可以表级也可以列级。
1:primary key(主键约束):一个表只能有一个主键,主键可以为一个或多个字段(多个时只能定义为表级约束),不允许为空也不可重复,其值可以唯一标识表中每一行。
2:foreign key(外键约束):一个表可以有多个外键,用于构建一个表的两个字段,或两个表的两个字段之间的参照关系。主表作为参照,从表(存在外键)使用参照。
格式:
foreign key [字段名] references <表名>[字段名] on delete[参照动作] on update[参照动作] 参照动作:(不是必须的,可以不设定,效果同restrict一样)
1:restrict:限制,当要删除或更新一个父表的值时,如果它被子表参照了,则拒绝删除或更新操作
2:cascaade:级联,从父表删除或更新在外键中的值时,自动删除或更新在子表中匹配的行
3:set null:置为空,当子表相应字段为not null 时,从父表更新或删除外键中出现的值时,自动将子表中对应的值设置为null。
4:no action:不动作,与1一样
3:unique(唯一约束):一个表可以有多个唯一约束,可以为一个或多个字段,可以为空值,必须唯一。
4:default(默认值):为某一列指定了默认值,当向表中输入数据时,可以不输入该列数据值,采用默认值。
5:check(检查约束-MySQL不支持)
表的基本操作
创建一个表(在school数据库里):
CREATE TABLE deptinfo ( dept_ID int NOT NULL AUTO_INCREMENT, dept_code varchar(16) NOT NULL, dept_name varchar(50) NOT NULL, dept_desc varchar(200) DEFAULT NULL, PRIMARY KEY (dept_ID));CREATE TABLE classinfo ( class_id INT(10) AUTO_INCREMENT NOT NULL , class_name VARCHAR(255) NOT NULL DEFAULT '软件', class_code INT(10), dept_id INT(10) COMMENT'系部ID', PRIMARY KEY (class_id) ); create table classinfo ( class_id int(10) auto_increment not null , //属性名 数据类型 自动增长 是否为空 class_name varchar(255) not null default '软件', // 属性名 数据类型 是否为空 默认值‘软件’ class_code int(10), //属性名 数据类型 dept_id int(10) comment'系部ID', // 属性名 数据类型 解释 primary key (class_id) //设置主键为class_id ); 1:数据类型括号里的是数据大小;
2:是否为空默认为null(null不是0也不是空格或空字符串,而是没有值),not null 的属性必须给值;
3:自动增长(auto_increment)是在上一个表数据的基础上+1;
4:解释(comment)是对该属性的一种描述,可在表结构里查看;
5:主键(primary key)只能有一个,它的值唯一不能重复,它默认not null。
查看表结构,desc是describe的简写。
describe classinfo;desc classinfo; 
查看表的详细结构
show create table classinfo; 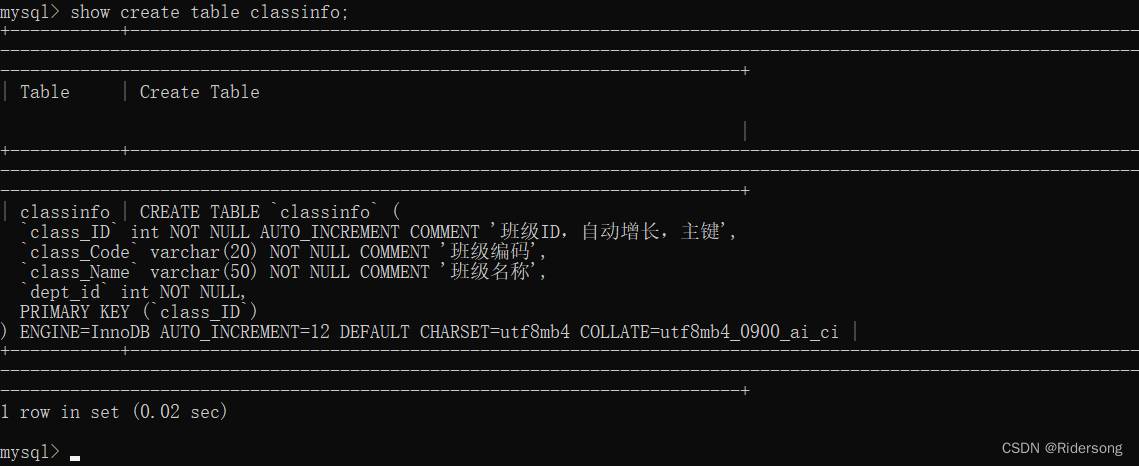
复制一个表(只复制表结构,不复制表数据)
create table classinfo_copy like classinfo; 

重命名表名
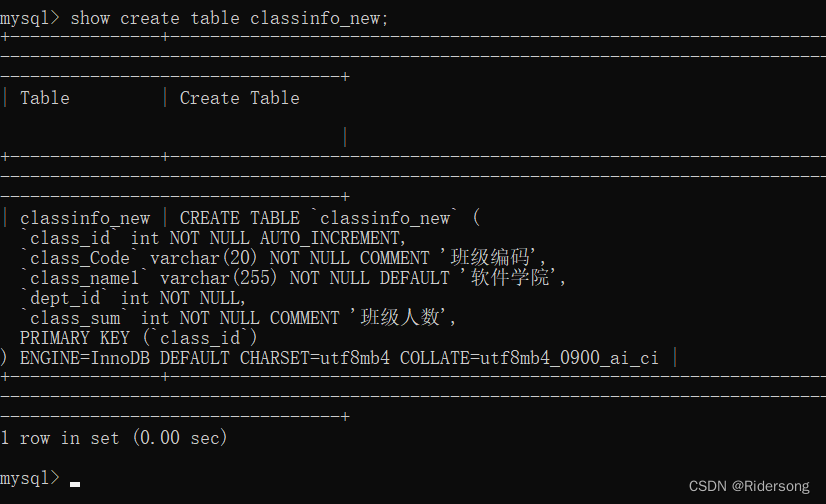
alter table classinfo rename classinfo_new; 
修改表classinfo_new属性(class_id)的数据类型及其他约束
alter table classinfo_new modify class_id int(20) auto_increment not null; 
修改表classinfo_new的class_name的属性名,数据类型及其他约束
alter table classinfo_new change class_name class_name1 varchar(255) not null default'软件学院'; 
增加一个表属性
alter table classinfo_new add class_sum int(100) not null comment'班级人数'; 
删除表的一个属性
alter table classinfo_new drop class_sum; 
修改表的存储引擎
alter table classinfo_new engine= MyISAM; 
删除表
drop table classinfo_new; 
插入一条数据,不指定表属性,需要按照顺序填写插入的数据,defluat为默认值(注意要使它为默认值,不能直接不填写它的值,要写default,不然会报错,跟not null无关)
insert into classinfo values(1,defluat,'1001',2); 插入两条数据,插入class_id,class_code,dept_id三个属性的值,因为class_name设置了default,所以它的值不插入也会使用默认值
insert into classinfo(class_id,class_code,dept_id) values(7,'1007',1),(8,'1008',2);
修改表数据,where条件是class_id=1,如果不加条件,那就默认所有的数据都修改
update classinfo set class_name='会计',class_code='1000',dept_id=4 where class_id=1;
删除一个class_id=8的数据,如果不加where条件,那么就会删除全部数据 (会变成一张空表)
delete from classinfo where class_id=8; 判断关键字
where:跟在from后进行判断
group by :根据字段进行分组
order by :根据字段进行排序 asc为升序,desc为降序
根据dept_id进行降序排序:
select * from classinfo order by dept_id desc;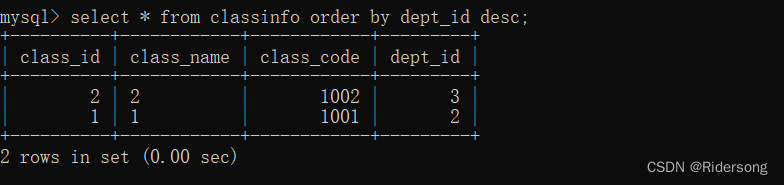
having :跟在group by 后进行选择
limit:限制select返回的行数
聚合函数
1:sum()计算某列值的总和
2:count()计算某列的个数
3:avg()计算某列的平均值
4:max()计算某列最大值
5:min()计算某列最小值
6:variance/stddev()计算特定表达式中所有值的方差/标准差
多表连接查询
1:全连接:通过dept_id连接两个表,查找dept_name和class_name
select dept_name,class_name from deptinfo,classinfo where classinfo.dept_id=deptinfo.dept_id; 2:join连接:inner,left outer,right outer,cross
内连接(inner join):通过dept_id内连接两个表,连接结果仅包含符合连接条件的行。
select dept_name,class_name from deptinfo inner join classinfo on classinfo.dept_id=deptinfo.dept_id;
外连接(outer join):
左外连接(left outer join),左外连接会显示左表所有信息和右表符合搜索条件的信息
select dept_name,class_name from deptinfo left outer join classinfo on classinfo.dept_id=deptinfo.dept_id;
右外连接(right outer join):右外连接会显示右表所有信息和左表符合搜索条件的信息
select dept_name,class_name from deptinfo right outer join classinfo on classinfo.dept_id=deptinfo.dept_id; 嵌套查询
嵌套在where:
查找class_nama为20205的班级所在部门的全部信息:
select * from deptinfo where dept_id=(select dept_id from classinfo where class_name='20205');
2:嵌套在select:
as 关键字:给该列的列名重新命名。
select dept_name as '部门名字' from deptinfo;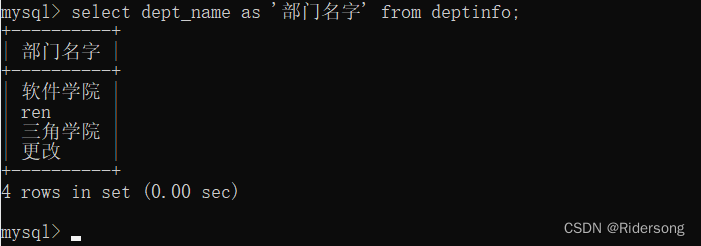
嵌套在select里时一般要给它重新命名,且子查询里返回行数只能是一行
select (select dept_id from classinfo where dept_id=2)as 'dept_id' from deptinfo;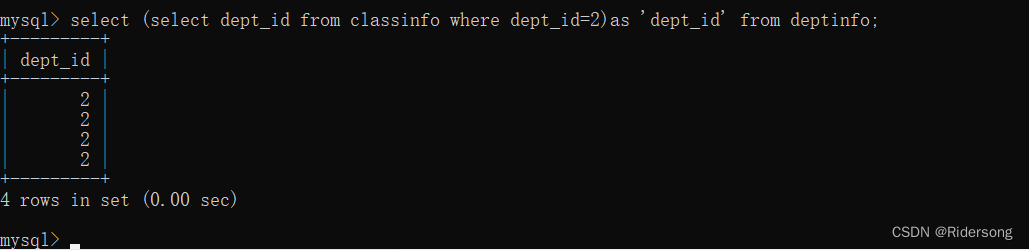
嵌套在from:
子查询返回的是一个派生表,含dept_id和dept_name字段,必须给派生表用as关键字取一个表名
select * from (select dept_id,dept_name from deptinfo) as x where dept_id=2;
4:in包含(not in)子查询:
查询班级信息,除非该班级的dept_id不在deptinfo表里的的0,1
select * from classinfo where dept_id not in(select dept_id from deptinfo where dept_id=1 or dept_id=0 );
5:比较子查询(<|<=|=|>|>=|!=|<>|all|some|any)
除最小的dept_id(也就是0)之外的所有部门的信息
select * from deptinfo where dept_id>some(select dept_id from classinfo); 
6:exists存在(not exists)子查询:
查询dept_id当dept_id=0存在时,exists后面一般跟子查询,不能直接跟条件
select dept_id from deptinfo where exists (select dept_id from deptinfo where dept_id=0);

联合查询
将多个select语句返回的结果通过union组合到一个结果集中。参与的select语句中的列数和列的顺序必须相同,数据类型必须兼容。
查询class_name=20205,且dept_name=软件学院的dept_id
select dept_id as '部门ID' from classinfo where class_name='20205' union select dept_id as '部门ID' from deptinfo where dept_name='软件学院'; 
事务
事务是用户定义的一个数据库操作系统系列,这些操作要么全部执行,要么一个都不执行,是一个不可分割的工作单位。
性质:
1:A(Atomicity)原子性
2:C(Consistency)一致性
3:I(Isolation)隔离性
4:D(Durability)持久性
结构:
start transaction/begin; //设置事务起点,start transaction或者begin commit; //提交事务 rollback; //回滚,撤销一个事务 save; //建立标签,用作部分回滚锁
锁(LOCK)是最常用的并发控制机构。是防止其他事务访问指定的资源控制、实现并发控制的一种主要手段。锁是事务对某个数据库中的资源(如表和记 录)存取前,先向系统提出请求,封锁该资源,事务获得锁后,即取得对数据的控制权,在事务释放它的锁之前,其他事务不能更新此数据。当事务撤消后,释放被 锁定的资源。
当一个用户锁住数据库中的某个对象时,其他用户就不能再访问该对象
排他锁:当数据对象被加上排它锁时,其他的事务不能对它读取和修改。
共享锁:加了共享锁的数据对象可以被其他事务读取,但不能修改。
索引
用于快速找出在某个列中有一特定值的行,提高查找速度
分类:
普通索引:index 索引名()
唯一索引:unique index 索引名()
单列索引:index 索引名()
组合索引:index 索引名()
全文索引:fulltext index 索引名()
空间索引:spatial index 索引名()
视图
是一张虚拟存在的表,主要作用是保证数据安全。
创建一个视图:
create[or replace][algorithm=(算法机制)] view [view_name] [column_list]asselect statement;view_name:视图名字
select statement:sql语句
创建一个classinfo表的视图:
create view class_view as select * from classinfo;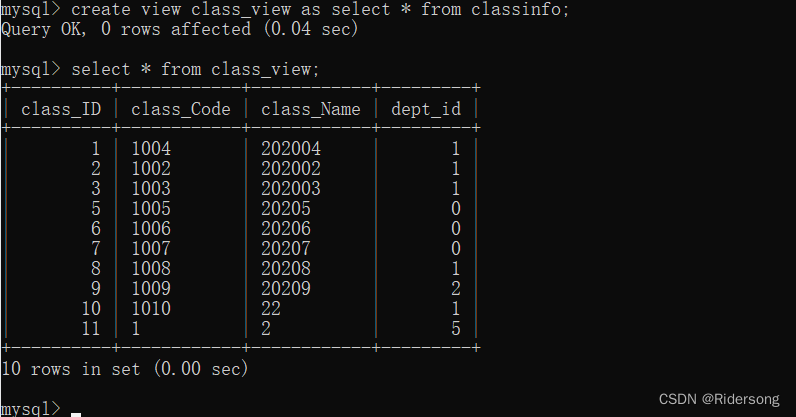
查看视图:
状态信息:
show table status like 'view_name';
相关信息:
select * from information_schema.views where table_name='view_name';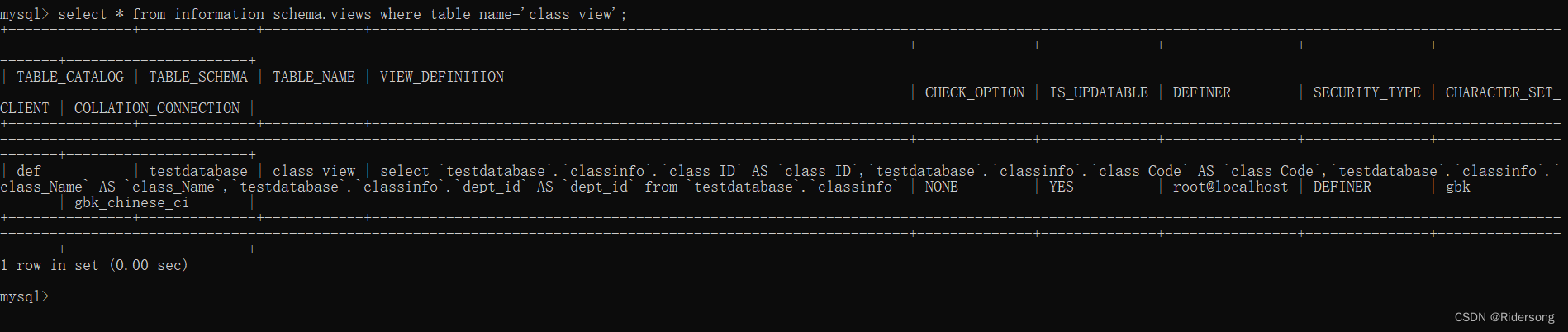
视图结构:
describe view_name;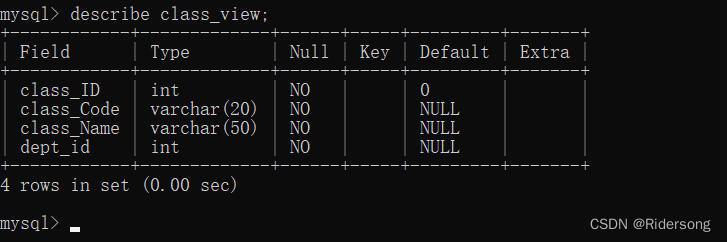
视图定义:
show create view view_name;
查看内容:(与表的操作一样)
select * from view_name; 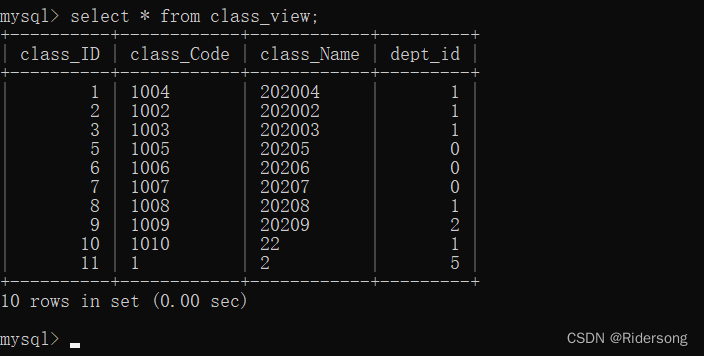
修改视图:
alter view [view_name]asselect satament;修改视图class_view的内容:
alter view class_view as select class_id from classinfo;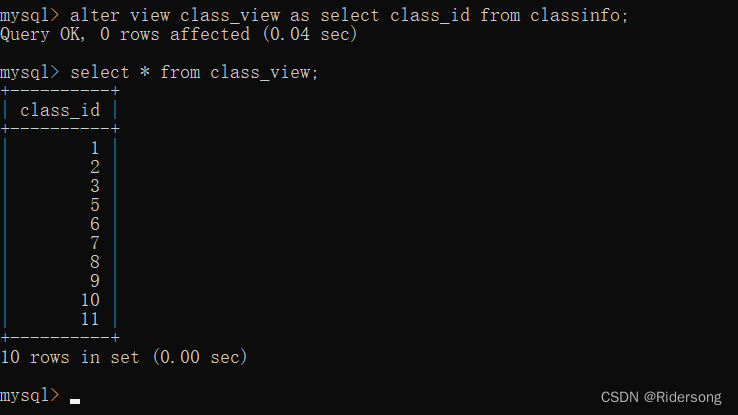
更新视图数据:
与表的操作一致,因为是虚拟表,所以对视图数据的更改都最终是对基本表的更改。
若依赖多个表,则只能一次对一个表进行更改,不可以同时对多个表进行更改。
不可更新视图:
1:包含聚合函数
2:distinct 关键字
3:group by 子句
4:order by 子句
5:having 子句
6:union 运算符
7:位于选择列表的子查询
8:from子句中包含多个表
9:select语句中引用了不可更新视图
10:where子句中的子查询,引用了from子句中的表
11:算法机制为:temptable
12:没有包含基本表中没有默认值的列
删除视图:
drop view view_name;
存储过程
存储过程是一组为了完成特定功能的SQL语句集,这些语句集先经过编译存储在数据库中,用户就可以通过指定存储过程来调用执行它
结束标志修改命令(delimiter):
SQL语句默认的结束标志是‘;’,在我们写存储过程时,存储过程内的sql语句用‘;’结束时并不是要结束整个存储过程的编写,所以修改结束标志,在存储过程编写完毕后再改回来。
将结束标志改为##
delimiter ##创建存储过程:
create procedure sp_name([proc_parameter[,...]])[characteristic...]routine_bodysp_nmae:存储过程的名称
2:proc_parameter[,...]表示存储过程的参数,()里可以为空但是必须写(),多个参数逗号隔开,参数格式为:参数类型+参数名+数据类型
参数为三个类型:
in:输入参数
out:输出参数 在存储过程内配合 select ...into..(赋值)使用
inout:既可以是输出也可以是输入
3:character:参数指定存储过程的特性
4:routine_body:表示存储过程的主体,里面包含了调用存储过程时必须执行的语句,总是以begin开始,end结束,begin-end可以嵌套
创建一个存储过程用于返回classinfo表里的数据个数:
delimiter ##CREATE PROCEDURE idsum1(out allsum int)beginselect count(*) into allsum from classinfo;end ##delimiter ;
调用存储过程:
call sp_name([proc_parameter[,...]]);调用时,如果()内有参数要写入对应数量的参数。
调用idsum1:
call idsum1(@x);
这里的@x是用户变量
存储过程体的过程式编程:
1:用户变量:
是会话级变量,与连接有关,一个客户端定义的变量不能被其他客户端看到或者使用,客户端退出时,该客户端的所有变量将自动释放
建立用户变量:
set @var_name=value[,@var_name=value.....];1:@为声明符号,@后紧跟变量名,不能有空格
2:var_name为用户变量的名字,不需要声明变量的类型
set @w=1;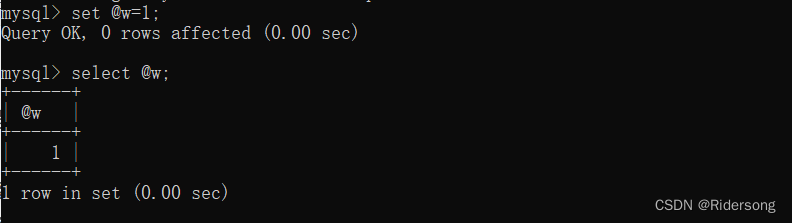
还有可以用:select @var_name:=value来给变量重新赋值(在set以外用‘:=’来赋值):
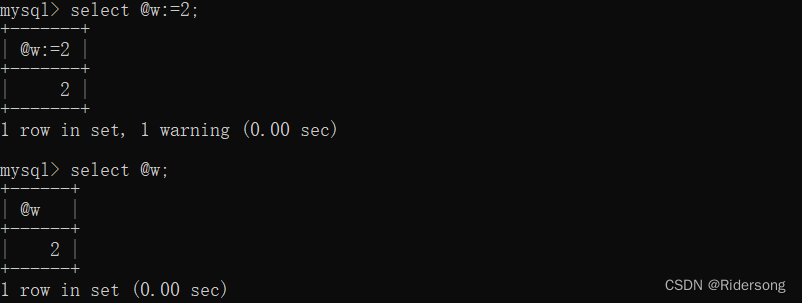
局部变量:
只能在begin-end语句块中声明,并且只能在声明的语句块中使用,可以用来存储临时结果
定义局部变量:
declare var_name[,....]type[default value];1:declare为声明符号
2:var_name为局部变量的名称,可以同时定义多个数据类型一致的局部变量
3:type为变量的类型
4:default value 给变量一个默认值,不指定则为null
为局部变量赋值:
1:set var_name=value[,var_name=value]...; 2:select col_name[,clo_name....] into var_name[,....] from table_name where condition ;(注意返回结果只能有一行)1:col_name表示查询的字段名
2:var_name表示要赋值的变量名
3:table_name表示参数表示表的名称
4:condition表示参数表示的查询条件
流程控制语句:(只能在begin-end语句块中使用)
(1):if 语句:
if search_condition then statement_list [elseif earch_condition then statement_list].... [else statement_list] end if1:seaech_condition是判断条件
2:statement_list包含一个或多个SQL语句,表示不同条件的执行语句
3: 当seaech_condition是真的时候,就执行相应SQL语句
(2):case 语句:
case case_value when when_value then statement_list [when when_value then statement_list]... [else statement_list]end casecase_value是要被判断的值或者表达式,接下来的每个when_value都要与case_value比较,如果为真则执行,如果每一个when都为假,就会执行else
case when search_condition then statement_list [when search_condition then statement_list]... [else statement_list]end casesearch_condition指定了一个比较表达式,表达式为真时执行,这种形式更方便
(3):循环语句:(while,repeat,loop)
1:while语句:
当满足条件时执行循环体内语句(先判断后执行)
[begin_lable:]while search_condition do statement_list end while[end_lable]1:search_condition 是否为真,为真则执行statement_list,直到不为真结束循环。
2:begin_lable和end_lable是while语句的标注
2:repeat语句:
当满足条件时跳出循环体内语句(先执行后判断)
[begin_lable:]repeat statement_list until search_condition end repeat[end_lable]
1:search_condition 是否为真,不为真则执行statement_list,直到为真结束循环
2:begin_lable和end_lable是repeat语句的标注
3:与while的区别就是它是先执行后判断,while是先判断后执行
3:loop语句:
是某些语句重复执行,没有停止循环语句,遇到leave才能停止循环
[begin_lable:]loop statement_list end loop[end_lable] 1:leave关键字:leave lable lable是语句中标注的名字,加上leave就可以跳出该名字的循环语句
2:iterate关键字:iterate lable lable是语句中标注的名字,加上iterate就可以跳出本次循环进入下一次循环
修改存储过程:
不可以修改存储过程中的内容,也不能修改存储过程的名称。如果想要修改存储过程的内容,只能删除原有的存储过程,然后再重新写一个存储过程;如果想要修改存储过程的名称,只能删除原有的存储过程,然后重新创建一个新的存储过程,并且把原有存储过程的内容写入到新的存储过程名称里面。能修改的只有存储过程的的特性。
alter procedure sp_name[characteristic....]查看存储过程:
查看存储过程状态:
show procedure status like 'sp_name';查看存储过程定义:
show create procedure sp_name;删除存储过程:
drop procedure sp_name;函数(与存储过程类似)
创建函数:
create functin f_name ([f_parameter])returns typeroutine_body1:f_name为函数名
2:f_parameter[,...]表示函数的参数,()里可以为空但是必须写(),多个参数逗号隔开 ,参数格式:参数名+数据类型
3:return type:返回值类型
4:routine_body:表示函数的主体,里面包含了调用函数时必须执行的语句,总是以begin开始,end结束,begin-end可以嵌套,注意主体里必须包含一个return语句返回一个与3相同类型的值
光标
用于逐条读取查询select结果集中的记录,只能在存储过程或函数中使用
1:声明光标:
declare c_name cursor for select_statement;c_name表示光标的名称
select_statement 表示selecte语句的内容
打开光标:
open c_name;使用光标:
fetch c_name into var_name[,var_name....];var_name表示将光标中的select语句查询出来的信息存入该参数中,该参数必须提前定义好
关闭光标:
close c_name;
触发器
由 insert update delete 等事件来触发特定操作[不能多种事件同时触发],相同触发时间相同触发事件只能定义一个触发器
1:创建触发器:
create trigger tr_name tr_time tr_event on tbl_name for each row tr_stmt;1:tr_name是触发器的名称
2:tbl_name是触发器关联的表
3:tr_time是触发时间(包括:befor检查约束前触发,after检查约束后触发)
4:tr_evnet 是触发事件包括:insert,load,data,replace,update,delete,replace
5:for each row 表示每行受影响,触发器都执行
6:tr_stmt是触发器的执行语句,可以多条,需要用begin-end语句块包括
执行语块中经常使用old,new来引用触发器关联表中正在发生变化的记录内容。
insert:new.column_name引用新插入的那一行的某个值
delete:old.column_name引用正被删除的那一行的某个值
update:old.column_name引用被更新之前的旧列值,new.column_name引用被更新之后的新列值
创建一个触发器,在deptinfo表插入一个数据时向classinfo表也插入一个数据
delimiter ##CREATE TRIGGER tr_dept_insert AFTER INSERT ON deptinfo FOR EACH ROW BEGININSERT INTO classinfo(class_code,class_name,dept_id) VALUES ('1','2',new.dept_id);END##delimiter ;查看触发器:
show triggers;删除触发器:
drop trigger tr_name;JAVA访问MySQL数据库
安装JDBC驱动:
到MySQL官网下载JDBC驱动,将MySQL-connector-java-版本号.jar复制到lib里然后重构
java.sql接口的作用:
DriverManager类:JDBC管理层,作用于用户和驱动程序之间。
Connection接口:建立与数据库的连接
Statement接口:容纳并操作执行SQL语句
ResultSet接口:控制执行查询语句得到的结果集
加载驱动程序:
Class.forName("com.MySQL.jdbc.Driver")
括号里是相应数据库的驱动程序,这里是MySQL数据库的
创建数据连接对象:
创建一个JDBC Connection连接对象,通过DriverManager类的 getConnection方法连接数据库
Connection connection = DriverManager.getConnection(URL,user,password)
URL为数据库连接地址,user为用户,password为密码
连接类:
import java.sql.*;public class JDBCUtil { //四个静态常量public static final String Url="jdbc:mysql://localhost:3306/order";//连接地址public static final String User="root";//使用者public static final String Password="root";//密码public static final String Driver="com.mysql.cj.jdbc.Driver";//MySQL驱动程序static {//注册一个Driver,将它放入DriverMannager中try{Class.forName(Driver);//加载驱动程序}catch(Exception e){e.printStackTrace();}}//加载JDBC-MySQL连接器public static Connection getConnection() throws SQLException{//获得连接对象return DriverManager.getConnection(Url,User,Password);}//关闭连接类public static void close(Connection con,PreparedStatement sql,ResultSet rs) {try {if(rs!=null) {rs.close();}if(sql!=null) {sql.close();}if(con!=null) {con.close();}}catch (SQLException e) {e.printStackTrace(); }}public static void main(String[] args) throws SQLException{System.out.print(getConnection());}}通过Java操作数据库:
通过Connection对象的createStatement()方法可以创建一个Statement对象
Statement statement=connection.createStatement();
通过调用Statement对象里的方法来进行数据的更新,查询
int result=statement.executeUpdate(sql);
通过sql语句进行数据的删除,更新,添加操作,返回值是一个整数,成功为1,失败为0
ResultSet result=statement.executeQuery(sql)
通过sql语句进行数据查询,查询结果会给到ResultSet的对象
可以通过result.next()方法将光标移动到下一条数据,result.get数据类型 来得到一条数据的数据,从而得到结果集里的所有数据。
来源地址:https://blog.csdn.net/qq_54414566/article/details/127835858
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341








![[mysql]mysql8修改root密码](https://static.528045.com/imgs/35.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









