

Python中怎么构建一个FP-growth算法

本篇文章为大家展示了Python中怎么构建一个FP-growth算法,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
FP算法发现频繁项集的过程是:
(1)构建FP树;
(2)从FP树中挖掘频繁项集
FP表示的是频繁模式,其通过链接来连接相似元素,被连起来的元素可看成是一个链表
将事务数据表中的各个事务对应的数据项,按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以 NULL为根节点的树中,同时在每个结点处记录该结点出现的支持度。
假设存在的一个事务数据样例为,构建FP树的步骤如下:

结合Apriori算法中最小支持度的阈值,在此将最小支持度定义为3,结合上表中的数据,那些不满足最小支持度要求的将不会出现在***的FP树中。
据此构建FP树,并采用一个头指针表来指向给定类型的***个实例,快速访问FP树中的所有元素,构建的带头指针的FP树如图:
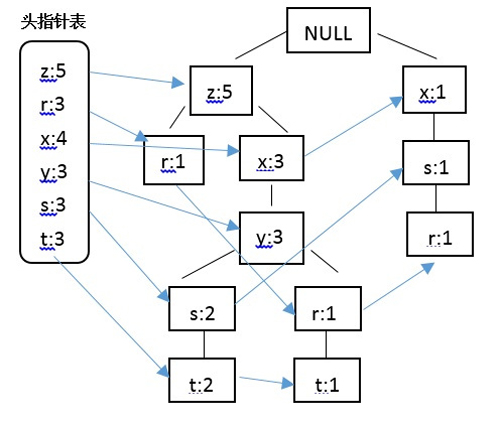
结合绘制的带头指针表的FP树,对表中数据进行过滤,排序如下:

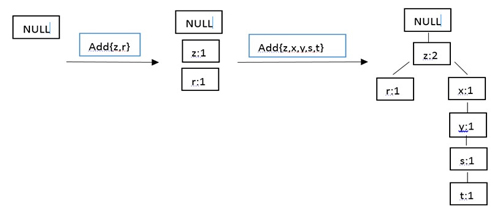
在对数据项过滤排序了之后,就可以构建FP树了,从NULL开始,向其中不断添加过滤排序后的频繁项集。过程可表示为:
上述内容就是Python中怎么构建一个FP-growth算法,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341











