

【C++】C&C++内存管理


就是你被爱情困住了?Wake up bro!

文章目录
1.
站在语言级别的角度来看,数据段其实更喜欢被叫做静态区,因为这个区域存放的都是静态数据和全局数据,其中数据段还可以细分为BSS段和data段,代码段被叫做常量区,其中存放了机器码和一些只读常量,例如常量字符串这些。
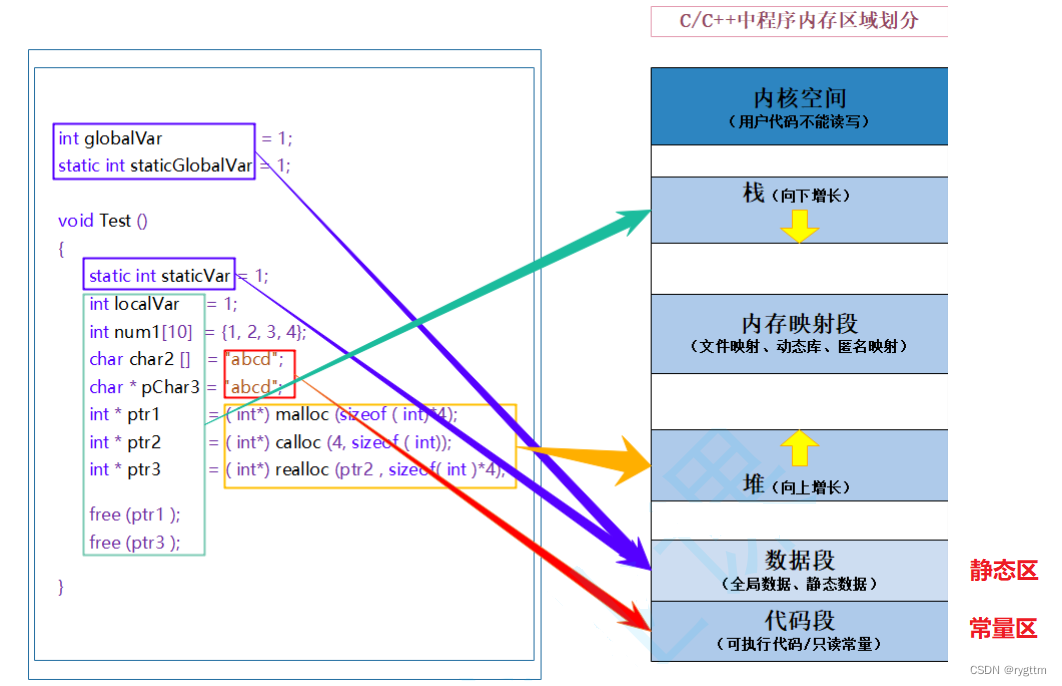
站在系统级别看待内存分布:虚拟地址空间
2.
栈又叫堆栈 — 非静态局部变量/函数参数/返回值等等,栈是向下增长的。
内存映射段 — 是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享内存,做进程间通信。
堆 — 用于程序运行时动态内存分配,堆是可以上增长的。
数据段 — 存储全局数据和静态数据。
代码段 — 可执行的代码/只读常量。
3.
下面给大家分享了许多大佬的文章,关于计算机内存大小计算,字、字长、字节、字位的,以及计算机组成原理部分的知识,有关于地址总线等等知识,这些知识了解即可,博主不是搞硬件的,所以给大家推送几篇文章,我们一起扩展一下知识。
所以指针大小固定的原因就是,无论你是什么类型的指针,指针变量中存储的就是字的地址,因为虚拟地址空间或物理地址都是用字来作为自然的数据单位,一个字在32位机器上就是4Byte大小,所以可见指针大小在32位机器上就是4Byte。
字长、字节、字、字位的区别(转载自csdn博主gxhlh的文章)


在32位机器中,一个字包含32个元器件,那么总共就有4×8×1024×1024×1024个元器件,也就是4G大小的内存,如果是64位机器下,理想情况下,一个字包含64个元器件,也就是一个字的元器件排列可能有2的64次方中可能,2的32次方下就已经有4G多的元器件了,如果是2的64次方那就是2的32次方再×4G大小,也就是非常非常多的元器件。很多人容易算成16G大小的元器件,这实际上是错误的,他们以为2的64次方是4G×4G,但显然不是这样计算的,因为m×m变成平方了都,4G×4G之后的单位怎么可能还是G?,所以有不少人以为64位机器的内存是16G,这显然是错误的。
实际中的32位机器下,一个字不是64个元器件,地址总线并非64根,而是36根或40根,如果真有64根,内存都大到天上去了。


关于地址总线、32位和64位系统区别的文章(转载自简书博主gsonliu的文章)
4.
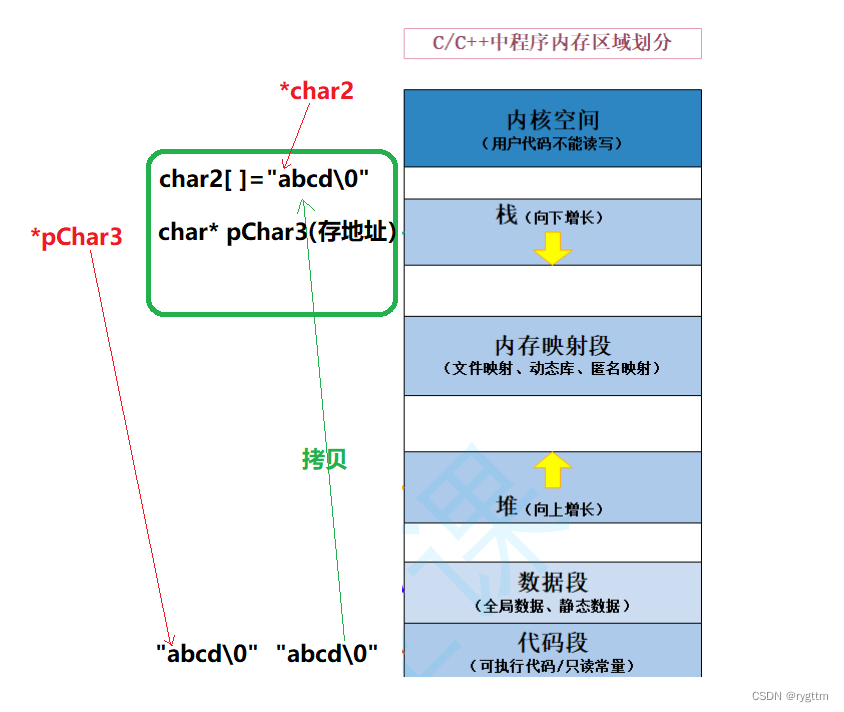
对于全局数据、静态全局数据、局部静态数据他们都存放在静态区中,非静态局部变量以及数组这些都是存放在栈区上的。
而char2数组中的内容实际上是从常量区中的常量字符串拷贝过来的,所以* char2指向的不是常量区中的字符a,指向的是栈区中拷贝到数组char2里面的字符串中的字符a。至于指针变量pChar3本身就在栈区上,只是这个变量内部存储的是常量区abcd字符串的首字符a的地址,所以* pChar3就存在常量区里面了。
同理ptr1也是指针变量,在栈区里面,其中存放的也是堆区开辟好空间的首字符的地址,所以*ptr1在堆区上。
sizeof求的是变量类型所占空间的大小,如果是数组则求的是数组所占空间大小,数组末尾的\0也会计算,指针大小取决于机器的位数,32位则为4字节,64位则为8字节。strlen求的是字符串有效长度,不包括末尾的\0。

void Test (){int* p1 = (int*) malloc(sizeof(int));free(p1);// 1.malloc/calloc/realloc的区别是什么?int* p2 = (int*)calloc(4, sizeof (int));int* p3 = (int*)realloc(p2, sizeof(int)*10);// 这里需要free(p2)吗?free(p3 );}1.
malloc就是简单的向堆区申请空间资源,calloc不仅会申请资源,还会将申请的空间内容初始化为0,calloc = malloc + memset设置为0,realloc用于空间的扩容,如果空间不够,我们可以利用realloc再向堆区申请扩大空间,扩容又分为异地扩容和原地扩容两种方式,如果是原地扩容,则p3和p2指向的是同一块空间,所以不同重复释放p2指向的空间,如果是异地扩容,则p2和p3指向的空间都需要释放,当然上述代码realloc的空间很小,一定是原地扩容,所以不需要释放p2,当申请空间过大时,才可能出现异地扩容的情况。
2.
malloc的实现原理?
glibc中malloc实现原理
1.new和delete操作内置类型
1.
申请一个空间什么都不用带,初始化用( )
申请多个空间用[ ],初始化用{ }。
delete[ ]用于释放开辟个数大于1的空间,delete用于释放仅仅开辟个数为1的空间。
#include 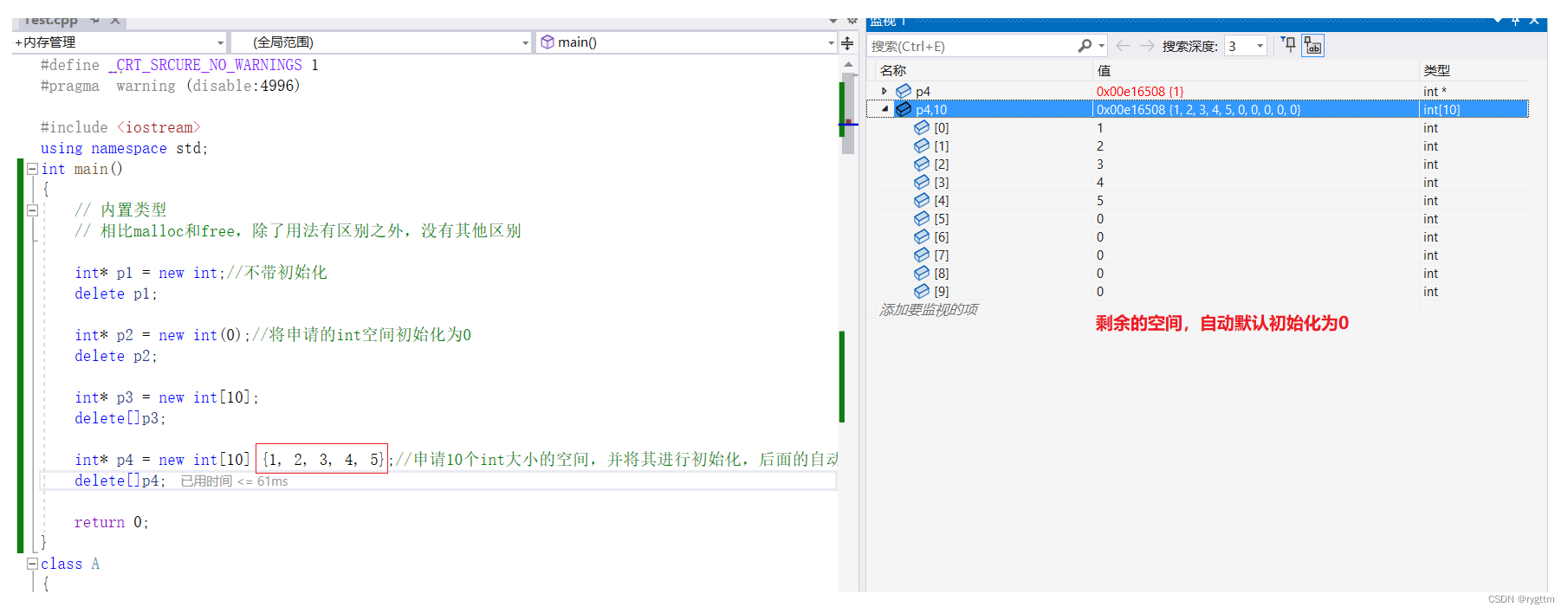
2.new和delete操作自定义类型(仅限vs的底层实现机制,new和delete一定要匹配使用,否则会出现各种各样的情况)
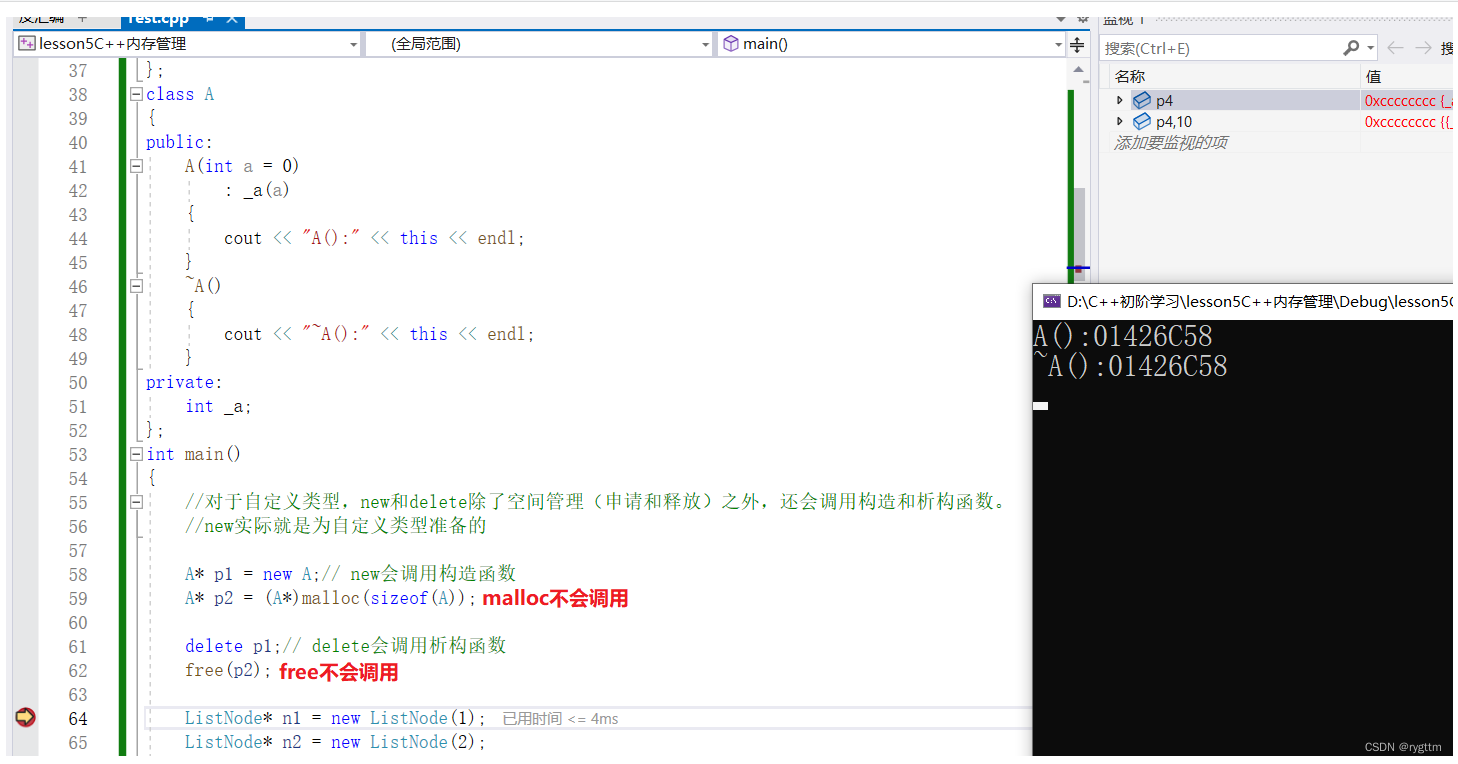
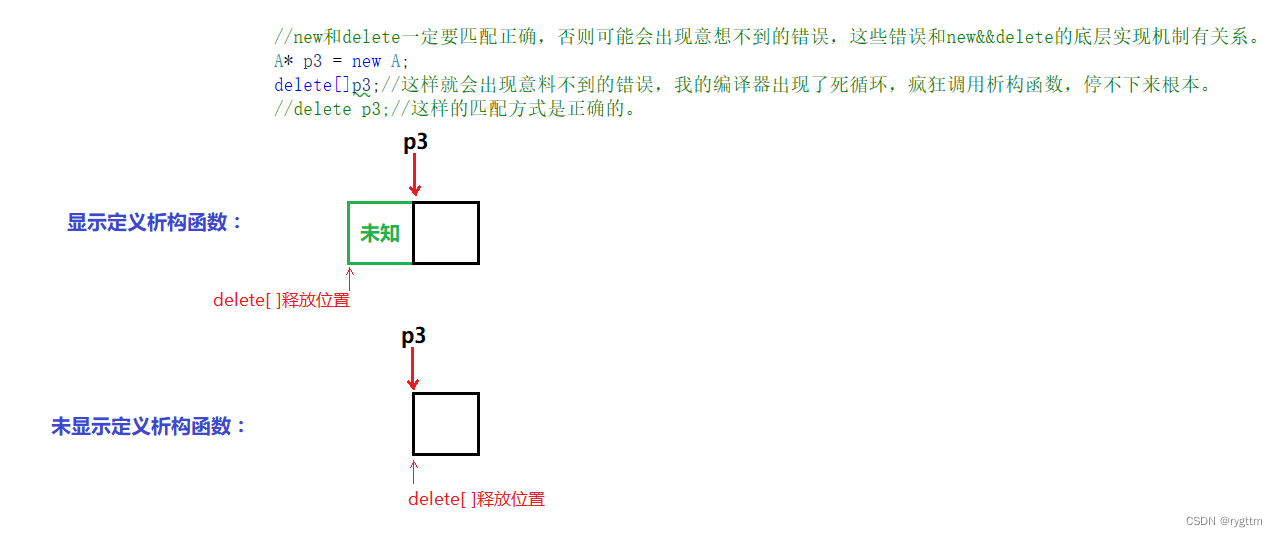
class A{public:A(int a = 0): _a(a){cout << "A():" << this << endl;}//是否屏蔽掉显示的析构函数决定了delete和new不匹配是否出现错误的问题。~A(){cout << "~A():" << this << endl;}private:int _a;};struct ListNode{ListNode* _next;int _value;ListNode(int value = 0)//缺省值搞成0:_next(nullptr), _value(value){}};int main(){//对于自定义类型,new和delete除了空间管理(申请和释放)之外,还会调用构造和析构函数。//new实际就是为自定义类型准备的A* p1 = new A;// new会调用构造函数A* p2 = (A*)malloc(sizeof(A));delete p1;// delete会调用析构函数free(p2);ListNode* n1 = new ListNode(1);ListNode* n2 = new ListNode(2);ListNode* n3 = new ListNode(3);ListNode* n4 = new ListNode(4);n1->_next = n2;n2->_next = n3;n3->_next = n4;//new和delete一定要匹配正确,否则可能会出现意想不到的错误,这些错误和new&&delete的底层实现机制有关系。A* p3 = new A;delete[]p3;//这样就会出现意料不到的错误,我的编译器出现了死循环,疯狂调用析构函数,停不下来根本。//delete p3;//这样的匹配方式是正确的。A* p4 = new A[10];delete p4;//如果存在显示的析构函数,则会报内存泄露的错误。如果屏蔽掉显示的析构函数,则编译器不会报错。A* p5 = new A;delete[]p5;//析构函数放出来会报错,不放出来就不会报错。//delete会向前找一个位置,然后开始释放空间,则一定会报错。//析构函数放出来,编译器会以为你释放的是多个空间,所以就会去向前找存放的数字,但其实前面并没有开辟空间,所以就会报错。//析构函数不放出来,编译器会很智能的从当前位置向后释放空间,不会向前找那一个空间,所以不会报错。return 0;}1.
在申请自定义类型空间时,new会调用构造函数,delete调用析构函数,malloc和free不会调用。
2.
new和delete一定要匹配,比如new和delete[ ]匹配了,或者new[10]和delete匹配了,有可能出现内存泄露和报错等问题,这些问题都是依赖于编译器的底层实现机制,在释放空间时,delete可能知道要释放多少字节的空间,但具体要释放多少个对象,编译器是不知道的,因为编译器无法确定类的大小,也就无法知道对象具体所占字节的大小,所以在vs的底层实现上,new开辟空间的时候会在开辟空间的前面多开辟一个空间,用于存储开辟的空间中具体对象的个数,然后在返回指针的时候,会将指针向后挪动,直到指向开辟的有效可用的空间,等到释放空间的时候,指针又会向后挪动,这样编译器就知道具体要释放多少个对象了,也就是调用多少次析构函数,最后将开辟的所有的空间都给释放掉,包括前面多开辟的一个空间。
3.
delete只会从指针的当前位置开始释放空间,并不会先向前挪动,指向空间的最开始位置,所以new[10]和delete匹配会发生内存泄露,因为new[10]不仅仅会开辟10个对象大小空间,还会多开辟一个存储对象大小的空间,而delete释放的时候不会自动向前挪动,只有delete[ ]释放时才会向前挪动。
但是我们看到,当显示的析构函数屏蔽掉时,编译器就不会报错了,这是因为如果显示写析构函数,编译器会觉得我们的意图是想知道释放空间时具体要释放多少个对象,所以new会多开辟一个空间。而不显示写析构函数,编译器就会很智能,它觉得我们不想知道具体要释放多少个对象,所以就不会多开辟一个空间,此时正好就可以将所有空间释放掉。

4.
而new和delete[ ]匹配的话,并且有显式定义的析构函数,一定会报错,因为编译器以为new多开辟了一个空间用于存储对象个数,所以delete[ ]释放的时候,会自动将指针前挪,从前面开始释放空间,这样就发生了越界访问,前面空间里面存的是什么,是不确定的,所以编译器会死循环调用析构函数,这就是越界访问给我们带来的未知预料错误。
而如果屏蔽显式定义的析构函数的话,编译器就不会多开辟一个空间,并且delete[ ]也不会从前面开始释放空间,因为编译器已经向delete[ ]表明意图,告诉delete[ ]不需要多释放前面那个空间,因为new的时候就没有多开辟那个空间,所以也就不会报错。
1.malloc和new的区别(malloc失败返回NULL。new失败抛异常,捕获错误,不需要检查返回值。)
void Test(){while (1){//new失败,抛异常 --- 不需要检查返回值char* p1 = new char[1024 * 1024 * 1024];//一次申请1G的空间,快速显示申请失败的结果//char* p1 = (char*)operator new(1024 * 1024 * 1024);//和malloc使用形式相似,但它申请失败,是抛异常,而不是返回空指针cout << (void*)p1 << endl;//强转打印p1指针的地址,否则cout打印的是字符串//所以用习惯new之后,就不想用malloc了,自定义类型会调用构造和析构,内置类型用起来更加简洁,不需要检查错误等等优点,更方便一些}}int main(){while (1){ //malloc失败,会返回空指针,所以我们需要在malloc之后,进行if判断,检测空间是否申请成功int* p1 = (int*)malloc(1024*100);//一次申请100KB的空间if (p1){cout << p1 << endl;}else{cout << "申请失败" << endl;break;}}try//捕获异常,有异常,则直接跳转到catch{Test();}catch (exception& e)//如果new失败,则直接会抛异常,代码执行位置直接跳转到catch,也就是捕获错误的位置。{cout << e.what() << endl;}A* p1 = new A[10];//delete[] p1;//下面这俩殊途同归free(p1);//在析构函数未显示实现的情况下,用free也不会发生内存泄露,//因为delete和free底层调用的都是_free_dbgreturn 0;}1.
malloc失败返回空指针,new失败,抛异常,异常是面向对象语言处理错误的一种方式,new失败,调试光标从当前位置会直接跳转到catch部分,也就是捕获错误的地方。所以使用new不需要判断返回值,直接用捕获错误的方式,抛异常即可。
2.operator new && operator delete(调用new和delete实际上是调用系统提供的这两个全局函数)
1.
new申请内存的底层机制是operator new,operator new的底层又是malloc实现的,operator new不是new的运算符重载,因为运算符重载的目的是让自定义类型能够像内置类型一样使用,而内置类型的原生符号里面是没有new的,由此可见operator new不是运算符重载。
所以operator new和operator detele是系统提供的全局函数,在库里面实现的。另一方面,运算符重载的operator和运算符是连在一起的,而这两个全局函数的opsrator和new或delete是分开的,这也可以帮助我们区分。
2.
下面这段代码是C++库中的代码,从operator new的参数可以看出,他是没有this指针的,由此可以证明这个函数一定不是运算符重载,因为运算符重载都是非静态类成员函数,是有this指针的。
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc){// try to allocate size bytesvoid *p;while ((p = malloc(size)) == 0) if (_callnewh(size) == 0) { // report no memory // 如果申请内存失败了,这里会抛出bad_alloc 类型异常 static const std::bad_alloc nomem; _RAISE(nomem); }return (p);}void operator delete(void *pUserData){ _CrtMemBlockHeader * pHead; RTCCALLBACK(_RTC_Free_hook, (pUserData, 0)); if (pUserData == NULL) return; _mlock(_HEAP_LOCK); __TRY pHead = pHdr(pUserData); _ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse)); _free_dbg( pUserData, pHead->nBlockUse ); __FINALLY _munlock(_HEAP_LOCK); __END_TRY_FINALLY return;}#define free(p) _free_dbg(p, _NORMAL_BLOCK)3.
通过上述两个全局函数的实现知道,operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
4.
所以operator new其实是malloc的封装,申请内存失败,会抛异常,这样才符合C++面向对象处理错误的方式。operator delete也是free的封装,free是一个宏函数,等效于_free_dbg。

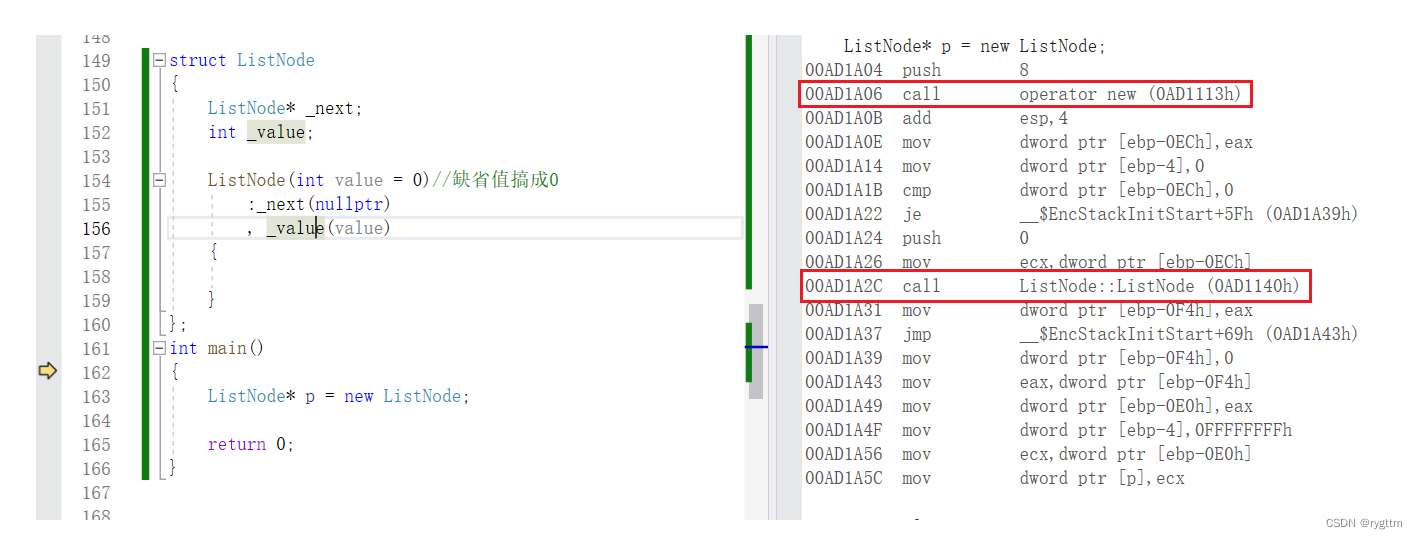
从new的反汇编代码可以看到,new底层的确是调用(call)了operator new全局函数
delete和free底层调用的都是_free_dbg函数,所以在析构函数未显示实现的情况下,delete和free实际上没有区别,因为释放空间都是从当前位置向后释放。

1.
下面是关于函数的实现原理,帮助我们更好的理解new、new T[N]、delete、delete[ ]这些函数。

2.
下面拿new来举例,从汇编角度可以看到operator new和operator new[ ]函数的调用,其实operator new[ ]也要调用operator new函数,而operator new的底层又会调用malloc,operator new就是malloc的封装。

1.
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
2.
使用格式:
new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
class A{public:A(int a = 0): _a(a){cout << "A():" << this << endl;}~A(){cout << "~A():" << this << endl;}private:int _a;};int main(){A* p1 = new A;//A* p2 = new A[10];A* p3 = (A*)malloc(sizeof(A));if (p3 == nullptr){perror("malloc fail\n");exit(-1);}//定位new --- 对p3所指向空间,显示调用构造函数初始化new(p3)A(1);//下面这两种释放空间的方式都可以p3->~A();//析构函数可以显示调用,构造函数不能显示调用free(p3);delete p3;//delete = 析构 + operator delete函数(底层还是_free_dbg,和free一样的底层函数)return 0;}3.
如果特别不想使用new抛异常的方式,可以使用定位new表达式,然后显式调用构造函数来替代new抛异常。但是吧,这样的使用方式太挫了,寂然一行代码可以解决的问题,我为什么还要先malloc在定位new表达式将已开辟空间初始化呢?这不是把原来一步就可以完成的工作硬生生拆分为两步吗?这样的使用方式简直太挫了。
然而,定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定位表达式来显示调用构造函数进行对象的初始化。
4.
我们可以把malloc或new开辟的空间,比喻为村口的一口井,所有村民都需要每天去井那里打水,而内存池就相当于村长家的蓄水池,这个蓄水池有一根管道直接连接到村口的井,所以对于村长来说,池化技术大大提高了村长家的效率。
池化技术(转载自腾讯云开发者社区博主用户5325874的文章)
1. malloc/free和new/delete的区别(从用法功能和底层两个角度来回答)
相同点:
malloc/free和new/delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。
不同点:
1.用法功能:
a.malloc和free是函数,new和delete是操作符
b.对于自定义类型,malloc申请的空间不会初始化,new可以初始化
c.malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可
d.malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
2.底层:
a. 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理
b.malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常
2.内存泄露(除定义和危害外,其他知识了解即可)
2.1 内存泄露的定义和危害(是指针丢了,而不是内存丢了)
1.
什么是内存泄漏:内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
2.
内存泄漏的危害:长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
3.
一般出现内存泄露有两种情况,一种是我们手动申请了,但由于疏忽导致忘记释放了指针指向的内存,另一种是由于某些原因,例如抛异常代码跳转,导致错过执行了释放空间的代码。
void MemoryLeaks(){// 1.内存申请了忘记释放int* p1 = (int*)malloc(sizeof(int));int* p2 = new int;// 2.异常安全问题int* p3 = new int[10];Func(); // 这里Func函数抛异常导致 delete[] p3未执行,p3没被释放.delete[] p3;}2.2 内存泄露的分类
C/C++程序中一般我们关心两种方面的内存泄漏:
1.堆内存泄漏(Heap leak):
堆内存指的是程序执行中依据须要分配通过malloc / calloc / realloc / new等从堆中分配的一块内存,用完后必须通过调用相应的 free或者delete 删掉。假设程序的设计错误导致这部分内存没有被释放,那么以后这部分空间将无法再被使用,就会产生Heap Leak。
2.系统资源泄漏:
指程序使用系统分配的资源,比方套接字、文件描述符、管道等没有使用对应的函数释放掉,导致系统资源的浪费,严重可导致系统效能减少,系统执行不稳定。
2.3 如何检测内存泄露
1.
在vs下,可以使用windows操作系统提供的_CrtDumpMemoryLeaks() 函数进行简单检测,该函数只报出了大概泄漏了多少个字节,没有其他更准确的位置信息。
int main(){int* p = new int[10];// 将该函数放在main函数之后,每次程序退出的时候就会检测是否存在内存泄漏_CrtDumpMemoryLeaks();return 0;}// 程序退出后,在输出窗口中可以检测到泄漏了多少字节,但是没有具体的位置Detected memory leaks!Dumping objects ->{79} normal block at 0x00EC5FB8, 40 bytes long.Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CDObject dump complete.2.
因此写代码时一定要小心,尤其是动态内存操作时,一定要记着释放。但有些情况下总是防不胜防,简单的可以采用上述方式快速定位下。如果工程比较大,内存泄漏位置比较多,不太好查时一般都是借助第三方内存泄漏检测工具处理的。
在linux下内存泄漏检测:linux下几款内存泄露检测工具
在windows下使用第三方工具:VLD工具说明
其他工具:内存泄露工具比较
2.4 如何避免内存泄露
工程前期良好的设计规范,养成良好的编码规范,申请的内存空间记着匹配的去释放。ps:这个理想状态。但是如果碰上异常时,就算注意释放了,还是可能会出问题。需要下一条智能指针来管理才有保证。
2.采用RAII思想或者智能指针来管理资源。
3.有些公司内部规范使用内部实现的私有内存管理库。这套库自带内存泄漏检测的功能选项。
4.出问题了使用内存泄漏工具检测。ps:不过很多工具都不够靠谱,或者收费昂贵。
总结一下:
内存泄漏非常常见,解决方案分为两种:
1、事前预防型。如智能指针等。2、事后查错型。如内存泄漏检测工具。
来源地址:https://blog.csdn.net/erridjsis/article/details/128921902
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














