


编码及运算符
1.编码
1.编码的概念
在计算机硬件中,编码(coding)是指用代码来表示各组数据资料,使其成为可利用计算机进行处理和分析的信息。代码是用来表示事物的记号,它可以用数字、字母、特殊的符号或它们之间的组合来表示。
2.编码的种类(常用种类)
①ASCCI
1.ASCCI的产生
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
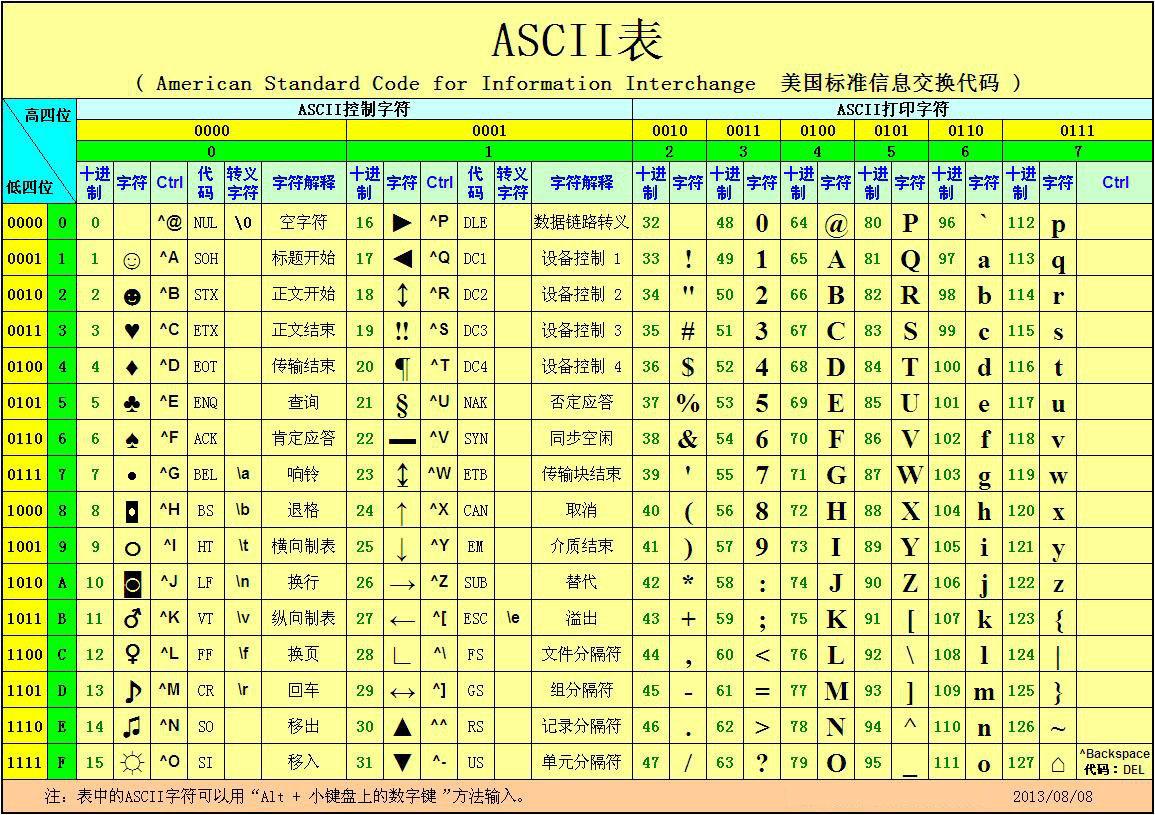
2.ASCCI的表述
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
字母A用ASCII编码是十进制的65,二进制的01000001;②unicode
1.Unicode的产生
unicode码扩展自ASCII 字元集。在严格的ASCII中,每个字元用7位元表示,或者电脑上普遍使用的每字元有8位元宽。如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
2.Unicode的表述
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。③UTF-8
1.UTF-8的产生
事实证明,对可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。这里只介绍UTF-8。
2.UTF-8的表述
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
| Unicode编码(十六进制) | UTF-8 字节流(二进制) |
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
字符 ASCII Unicode UTF-8
A 01000001 00000000 01000001 01000001
中 x 01001110 00101101 11100100 10111000 10101101注意(你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码)
④GBK
1.GBK的产生
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。这一版的GBK规范为1.0版。因为目前大家使用的主要是GB编码字库,此编码标准只收录了6763个常用汉字,而GB字库以外大量汉字,只能通过方正女娲补字软件拼字或其它造字程序补字。尽管补出的汉字在字形上满足需要,但在字体风格、大小、结构方面难以协调统一,而采用手工贴图的方式补字,更不雅观。进而言之,如果用户建立信息系统,或需要查询新闻、出版内容时,靠补字是无法实现的。方正开发的GBK字库,将极大地缓解缺字现象。
2.GBK的表述
GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。兼容ASCCI。
2.Python中的编码转码
1.Python的编码方式
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言
2.python中的字符串编码
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)3.Python中的转码解码和len()方法
encode(转码),decode(解码)。
x = b'ABC'
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文' len()函数:计算一个对象长度,如果换成bytes,len()函数就计算字节数。
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
63.运算符
1.运算符概念
运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算。例如:2+3,其操作数是2和3,而运算符则是“+”。在vb2005中运算符大致可以分为5种类型:算术运算符、连接运算符、关系运算符、赋值运算符和逻辑运算符。
2.Python中的运算符
-
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
- 运算符优先级
运算符优先级 ↓
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| and or not | 逻辑运算符 |
PS(时间原因,博主没有对每一个运算符介绍,大家自行查阅,养成查找问题习惯)












