



首先
1.为方便以下进行
谷歌浏览器里要安装xpath脚本
2.下载一个lmxl 命令:pip install lxml
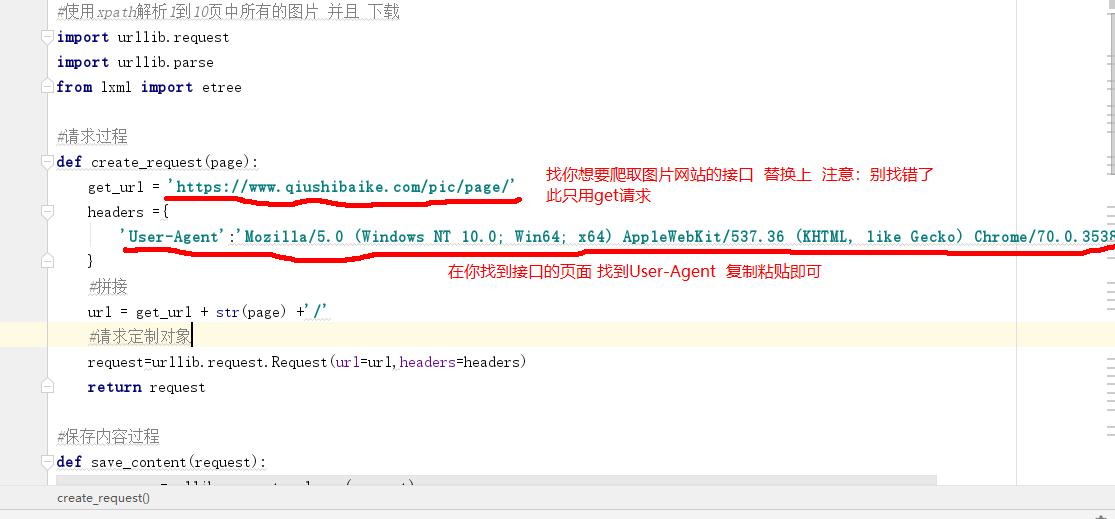
3. 以下三张图是一个,当时爬的 《糗事百科》里的图片
值的注意的是:在爬取接口时,要仔细看看 ,当时用的谷歌浏览器 当然也可以借用工具 EditPlus 这个比较好使,看个人喜好吧 用浏览器或Ediutplus工具 都行 。
使用谷歌浏览器 打开你要你想要下载的图片的网站 右键点击检查 打开network 找接口
找到接口的同时 User-Agent 也就有了 就在下面 找一找就能找到
4.使用xpath时 选中Elements 逐步按标签查找图片的路径,把找到的标签写在xpath简搜 ,直到你想要的。
建议:用xpath之前先看看怎么使用xpath


就先这样吧!
各位博友,请多多指教!












