

Pytorch写数字怎么识别LeNet模型

这篇文章主要为大家分析了Pytorch写数字怎么识别LeNet模型的相关知识点,内容详细易懂,操作细节合理,具有一定参考价值。如果感兴趣的话,不妨跟着跟随小编一起来看看,下面跟着小编一起深入学习“Pytorch写数字怎么识别LeNet模型”的知识吧。
LeNet网络
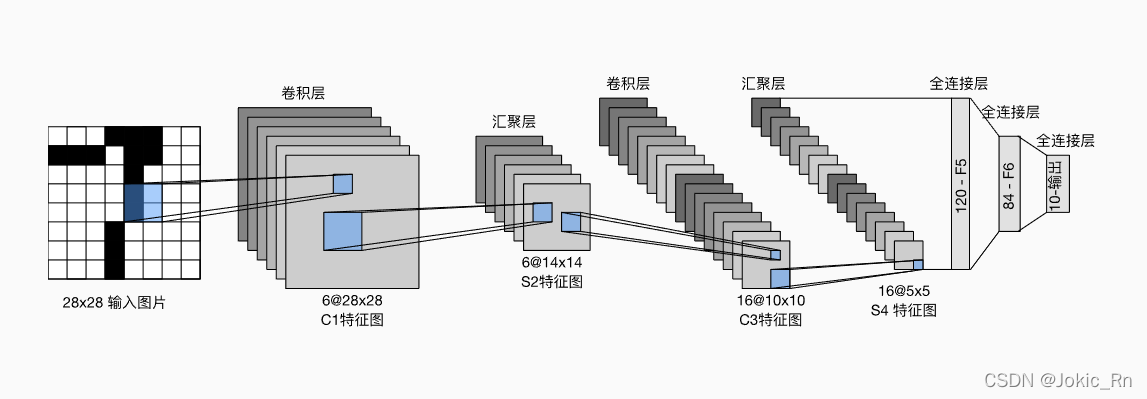
LeNet网络过卷积层时候保持分辨率不变,过池化层时候分辨率变小。实现如下
from PIL import Imageimport cv2import matplotlib.pyplot as pltimport torchvisionfrom torchvision import transformsimport torchfrom torch.utils.data import DataLoaderimport torch.nn as nnimport numpy as npimport tqdm as tqdmclass LeNet(nn.Module): def __init__(self) -> None: super().__init__() self.sequential = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(), nn.AvgPool2d(kernel_size=2,stride=2), nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(), nn.AvgPool2d(kernel_size=2,stride=2), nn.Flatten(), nn.Linear(16*25,120),nn.Sigmoid(), nn.Linear(120,84),nn.Sigmoid(), nn.Linear(84,10)) def forward(self,x): return self.sequential(x)class MLP(nn.Module): def __init__(self) -> None: super().__init__() self.sequential = nn.Sequential(nn.Flatten(), nn.Linear(28*28,120),nn.Sigmoid(), nn.Linear(120,84),nn.Sigmoid(), nn.Linear(84,10)) def forward(self,x): return self.sequential(x)epochs = 15batch = 32lr=0.9loss = nn.CrossEntropyLoss()model = LeNet()optimizer = torch.optim.SGD(model.parameters(),lr)device = torch.device('cuda')root = r"./"trans_compose = transforms.Compose([transforms.ToTensor(), ])train_data = torchvision.datasets.MNIST(root,train=True,transform=trans_compose,download=True)test_data = torchvision.datasets.MNIST(root,train=False,transform=trans_compose,download=True)train_loader = DataLoader(train_data,batch_size=batch,shuffle=True)test_loader = DataLoader(test_data,batch_size=batch,shuffle=False)model.to(device)loss.to(device)# model.apply(init_weights)for epoch in range(epochs): train_loss = 0 test_loss = 0 correct_train = 0 correct_test = 0 for index,(x,y) in enumerate(train_loader): x = x.to(device) y = y.to(device) predict = model(x) L = loss(predict,y) optimizer.zero_grad() L.backward() optimizer.step() train_loss = train_loss + L correct_train += (predict.argmax(dim=1)==y).sum() acc_train = correct_train/(batch*len(train_loader)) with torch.no_grad(): for index,(x,y) in enumerate(test_loader): [x,y] = [x.to(device),y.to(device)] predict = model(x) L1 = loss(predict,y) test_loss = test_loss + L1 correct_test += (predict.argmax(dim=1)==y).sum() acc_test = correct_test/(batch*len(test_loader)) print(f'epoch:{epoch},train_loss:{train_loss/batch},test_loss:{test_loss/batch},acc_train:{acc_train},acc_test:{acc_test}')训练结果
epoch:12,train_loss:2.235553741455078,test_loss:0.3947642743587494,acc_train:0.9879833459854126,acc_test:0.9851238131523132
epoch:13,train_loss:2.028963804244995,test_loss:0.3220392167568207,acc_train:0.9891499876976013,acc_test:0.9875199794769287
epoch:14,train_loss:1.8020273447036743,test_loss:0.34837451577186584,acc_train:0.9901833534240723,acc_test:0.98702073097229
泛化能力测试
找了一张图片,将其分割成只含一个数字的图片进行测试

images_np = cv2.imread("/content/R-C.png",cv2.IMREAD_GRAYSCALE)h,w = images_np.shapeimages_np = np.array(255*torch.ones(h,w))-images_np#图片反色images = Image.fromarray(images_np)plt.figure(1)plt.imshow(images)test_images = []for i in range(10): for j in range(16): test_images.append(images_np[h//10*i:h//10+h//10*i,w//16*j:w//16*j+w//16])sample = test_images[77]sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device)sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28))predict = model(sample_tensor)output = predict.argmax()print(output)plt.figure(2)plt.imshow(np.array(sample_tensor.squeeze().to('cpu')))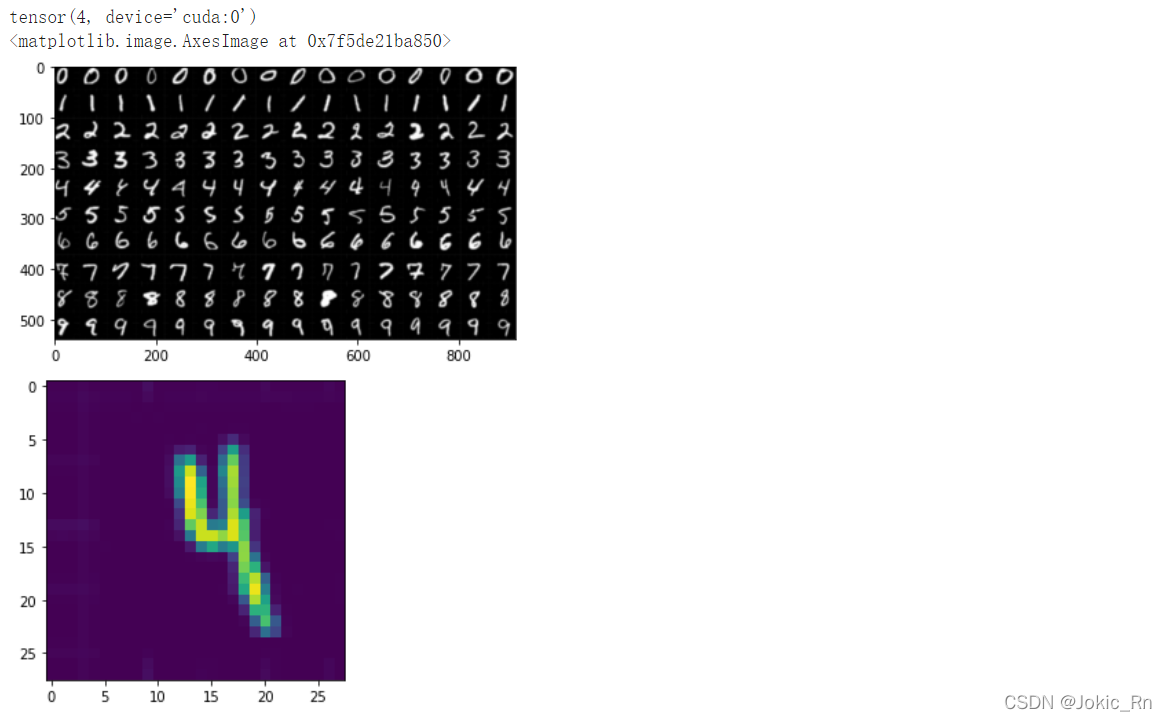
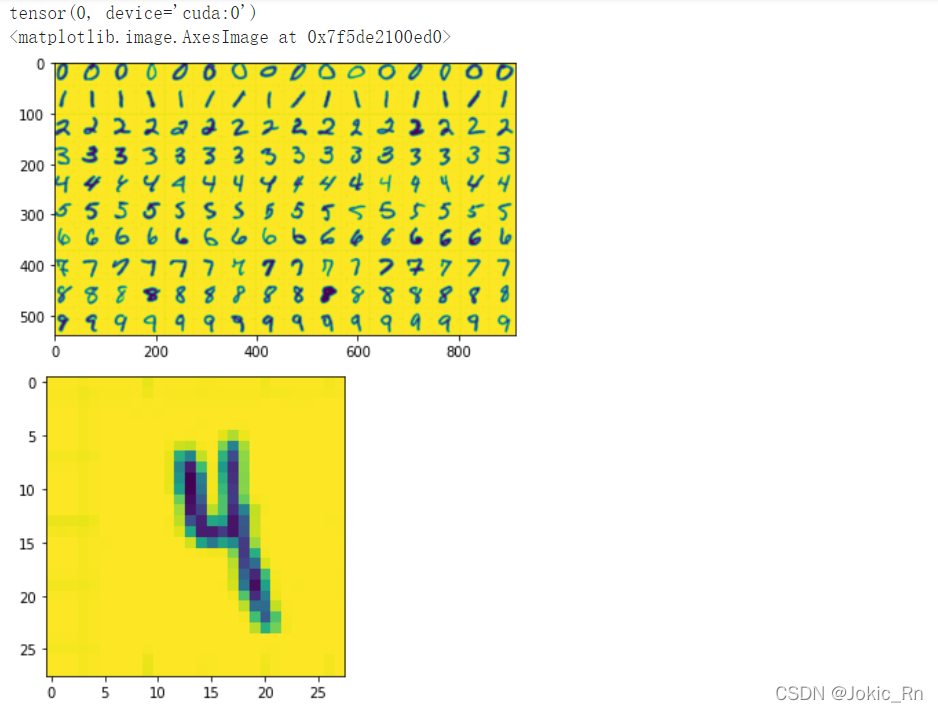
此时预测结果为4,预测正确。从这段代码中可以看到有一个反色的步骤,若不反色,结果会受到影响,如下图所示,预测为0,错误。
模型用于输入的图片是单通道的黑白图片,这里由于可视化出现了黄色,但实际上是黑白色,反色操作说明了数据的预处理十分的重要,很多数据如果是不清理过是无法直接用于推理的。
将所有用来泛化性测试的图片进行准确率测试:
correct = 0i = 0cnt = 1for sample in test_images: sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device) sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28)) predict = model(sample_tensor) output = predict.argmax() if(output==i): correct+=1 if(cnt%16==0): i+=1 cnt+=1acc_g = correct/len(test_images)print(f'acc_g:{acc_g}')如果不反色,acc_g=0.15
acc_g:0.50625pytorch的优点
1.PyTorch是相当简洁且高效快速的框架;2.设计追求最少的封装;3.设计符合人类思维,它让用户尽可能地专注于实现自己的想法;4.与google的Tensorflow类似,FAIR的支持足以确保PyTorch获得持续的开发更新;5.PyTorch作者亲自维护的论坛 供用户交流和求教问题6.入门简单
关于“Pytorch写数字怎么识别LeNet模型”就介绍到这了,更多相关内容可以搜索编程网以前的文章,希望能够帮助大家答疑解惑,请多多支持编程网网站!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













