

数据分析案例-基于因子分析探究各省份中心城市经济发展状况



🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、实验背景
因子分析法是一种寻找公共因子的模型分析方法,其目的是用少数几个因子去描述许多指标或因素之间的联系,将联系比较密切的几个因子变量归为同一类,每一类变量即为一个因子,用少数几个因子反映大部分的信息。运用这种模型方法,我们可以很方便的找出影响原有变量的主要因素有哪些。各省会城市通常是各省的经济、政治、文化中心,带动周边经济发展,是该省份其他地区经济和社会发展的“引路者”,由此吸引了很多人口到省会城市工作、定居。各个城市的常住人口的收入、生活便利情况受到很多因素的影响,如平均工资、房价、储蓄、医院情况等。通过因子分析模型,我们可以将这些指标进行归类,从而将影响该城市常住人口生活水平的指标进行简化。
二、实验内容及数据
2.1 概述
本项目选择各省份中心城市2018年的相关数据进行分析,数据来自于中国统计年鉴。总共选取了7个因子指标,分别是国内生产总值(亿元)、在岗职工平均工资(元)、住宅商品房平均销售价格(元/平方米)、城乡居民储蓄年末余额(亿元)、医院数(个)、社会商品零售总额(亿元)、年末总人口(万人)。
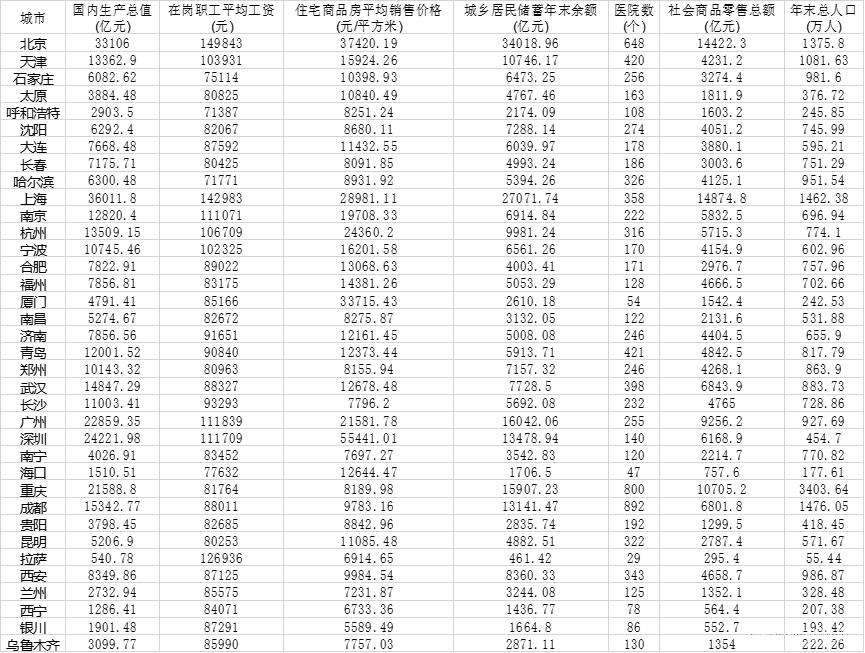
2.2 变量介绍
下面对原始数据中的变量进行相关说明,变量说明如表所示。
国内生产总值(亿元)、在岗职工平均工资(元)、住宅商品房平均销售价格(元/平方米)、城乡居民储蓄年末余额(亿元)、医院数(个)、社会商品零售总额(亿元)、年末总人口(万人)。
| 变量名 | 说明 |
| GDP | 国内生产总值(亿元) |
| AW | 在岗职工平均工资(元) |
| APH | 住宅商品房平均销售价格(元/平方米) |
| HSB | 城乡居民储蓄年末余额(亿元) |
| NH | 医院数(个) |
| TRS | 社会商品零售总额(亿元) |
| TP | 年末总人口(万人) |
三、实验步骤
3.1 导入模块和数据
先导入我们所需要的模块:
import pandas as pd import numpy as npfrom csv import reader from sklearn import preprocessingfrom sklearn.decomposition import PCAfrom factor_analyzer import *from scipy.stats import bartlettimport matplotlib.pyplot as pltimport matplotlibimport math as mathfrom matplotlib import cmimport numpy.linalg as nlg然后,对要使用到的算法步骤进行定义。为了使结果更为直观,我们可以将最后对样本的评分结果用条形图来表示,那么我们需要对这一过程进行定义,如下所示:
#画条形图def draw_hist(myname,mydata): fig = plt.figure(figsize=(10,5)) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False ax = fig.add_subplot(111) index=np.arange(0,len(myname),1) ax.bar(index,mydata,width=[0.5]) xticks = range(0,len(myname), 1) xlabels = [el for el in myname] ax.set_xticks(xticks) ax.set_xticklabels(myname,rotation=45) ax.set_xlabel("城市") ax.set_ylabel("综合得分") plt.title("常住人口生活水平") plt.show()其次,是定义KMO检验法,这一检验法可以帮助判断我们所选择的数据是否适合做因子分析。通常来说,KMO在0.9以上,非常合适做因子分析;在0.8-0.9之间,很适合;在0.7-0.8之间,适合;在0.6-0.7之间,尚可;在0.5-0.6之间,表示很差;在0.5以下应该放弃。
# KMO测度def kmo(dataset_corr): corr_inv = np.linalg.inv(dataset_corr) nrow_inv_corr, ncol_inv_corr = dataset_corr.shape A = np.ones((nrow_inv_corr, ncol_inv_corr)) for i in range(0, nrow_inv_corr, 1): for j in range(i, ncol_inv_corr, 1): A[i, j] = -(corr_inv[i, j]) / (math.sqrt(corr_inv[i, i] * corr_inv[j, j])) A[j, i] = A[i, j] dataset_corr = np.asarray(dataset_corr) kmo_num = np.sum(np.square(dataset_corr)) - np.sum(np.square(np.diagonal(A))) kmo_denom = kmo_num + np.sum(np.square(A)) - np.sum(np.square(np.diagonal(A))) kmo_value = kmo_num / kmo_denom return kmo_value另外,我们在相关系数矩阵的特征根和特征向量之后,需要对其进行排序,所以,还需要定义特征根和特征向量排序的步骤。
# 特征根与特征向量排序def sort_valvector(Teig_value, Teigvector): Temp=[] Temp.append(Teig_value) TempNames=["a"] for i in range(Teigvector.shape[0]): TempNames.append("L"+str(i+1)) TempMat=np.append(Temp,Teigvector,axis=0).T PDTempMat=pd.DataFrame(TempMat) PDTempMat.columns=TempNames PDTempMat.sort_values('a', ascending=False,inplace=True) Teig_value=np.array(PDTempMat['a']).T Teigvector=np.array(PDTempMat.iloc[0:,1:]).T return Teig_value,Teigvector最后,导入数据集,删除数据的第一列“城市”,只保留需要分析的数据。
#导入数据data1 = pd.read_csv('data.csv', sep=',')myID=data1["城市"]data=data1del data["城市"]ColName=data.columnsprint(ColName)data=data.astype(float)3.2 数据分析
3.2.1 数据标准化
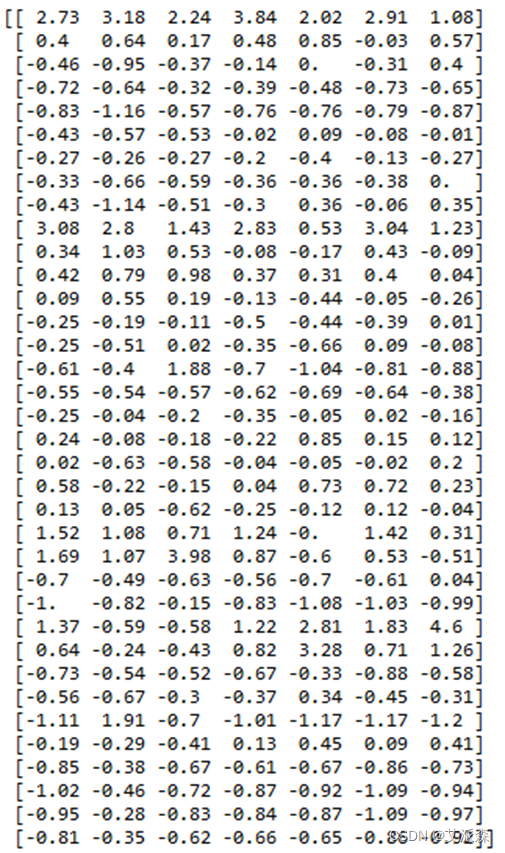
首先需要对数据进行标准化处理,计算出每列数据的平均值和标准差,利用标准化公式将每个数据标准化,计算得到标准化之后的数据,用dataz表示。
#数据标准化data=np.array(data)print(data.shape[0])tempavg=data.mean(axis=0) #计算每列的平均值tempdev=data.var(axis=0)*data.shape[0]/(data.shape[0]-1) #计算每列的标准差 tempdev=np.sqrt(tempdev)dataz = [[0 for i in range(data.shape[1])] for i in range(data.shape[0])] #定义标准化矩阵for i in range(data.shape[0]): for j in range(data.shape[1]): dataz[i][j]=(data[i][j]-tempavg[j])/tempdev[j]print(np.round(dataz,2))标准化后结果如下:
3.2.2 相关系数矩阵
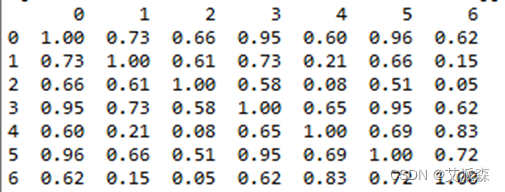
对标准化后的数据求相关矩阵:
#求相关矩阵pddataz=pd.DataFrame(dataz)print(np.round(pddataz.corr(),2))DF_corr=pddataz.corr()最后得到一个7×7的矩阵:
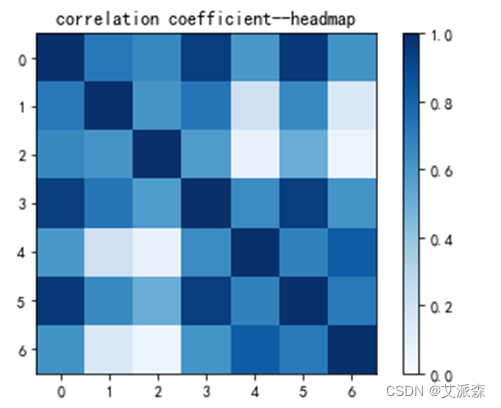
将各个因子变量用热力图来表示:
#热力图cmap = cm.Bluesfig=plt.figure()ax=fig.add_subplot(111)map = ax.imshow(DF_corr, interpolation='nearest', cmap=cmap, vmin=0, vmax=1)plt.title('correlation coefficient--headmap')ax.set_yticks(range(len(DF_corr.columns)))ax.set_yticklabels(DF_corr.columns)ax.set_xticks(range(len(DF_corr)))ax.set_xticklabels(DF_corr.columns)plt.colorbar(map)plt.show()图如下:
3.2.3 KMO方法检测
调用前面定义的KMO检测法,对数据进行检测,从而判断该数据是否适用因子分析模型进行分析。
#KMO测度from factor_analyzer.factor_analyzer import calculate_bartlett_sphericitychi_square_value,p_value=calculate_bartlett_sphericity(DF_corr)print("p值:",np.round(p_value,3))print("KMO测度:", kmo(DF_corr))最后得到的结果如下图

可知p值<0.05,KMO测度值大于0.7,该数据很适合做因子分析,因此,我们可以用因子分析法对这些因素进行分析。
3.2.4 特征值和特征向量
求相关系数矩阵的特征值及其对应的特征向量
#求特征根R= np.matrix(pddataz.corr()) eig_value, eigvector = np.linalg.eig(R)print(np.round(eig_value,3))print(np.round(eigvector,3)) 求得结果如下:
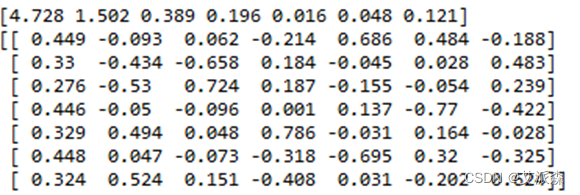
之后,按照由大到小的顺序对特征值进行排序,对应特征向量相应改变位置:
# 特征根与特征向量排序eig_value, eigvector=sort_valvector(eig_value, eigvector)print(np.round(eig_value,3))print(np.round(eigvector,3))结果如下:
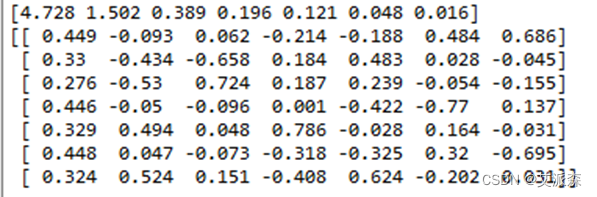
3.2.5 求因子载荷矩阵
首先,我们要确定公共因子的个数。由上一步骤可以看到,前三个特征值的比重大于85%的标准,所以,公共因子的个数为3。之后,再求因子载荷矩阵。因子载荷矩阵表示的是9个因子变量分别在3个公共因子上的相对重要性。
#计算主成分载荷矩阵 sqrt(a[i])*L[i][j]for i in range(eigvector.shape[1]): for j in range(eigvector.shape[0]): eigvector[j][i]=np.sqrt(eig_value[i])*eigvector[j][i]#以0.85为基准,求解特征根的个数k=0sa=0for i in range(len(eig_value)): sa=sa+eig_value[i] k=k+1 if sa/sum(eig_value)>=0.85: breakKeigvector=eigvector[0:,0:k] #取前K个特征向量a = pd.DataFrame(Keigvector)tempcolname=[]for i in range(k): tempcolname.append("factor" + str(i+1))a.columns = tempcolnamea.index = ColNameprint("\n因子载荷阵\n", np.round(a,3))求得的因子载荷矩阵结果如下:

3.2.6 因子分析
求特殊因子的方差及公共因子解释的总方差(贡献率)。
#因子分析fa = FactorAnalyzer(n_factors=k)fa.loadings_ = aprint("\n公共因子方差:\n", fa.get_communalities())var = fa.get_factor_variance() # 给出贡献率print("\n解释的总方差(即贡献率):\n",var)结果为:


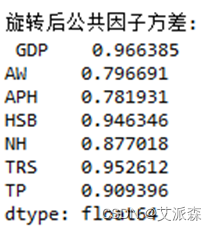
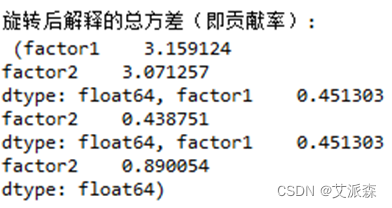
由上可以看出,最后形成2个公共因子。从方差贡献率可以看出,其中第一个公因子解释了总体方差的67.54%,2个公共因子的方差贡献率为89.01%,可以较好的解释总体方差。
3.2.7 因子旋转
为了对提取的因子更好命名,且更好解释,我们需要进行因子旋转:
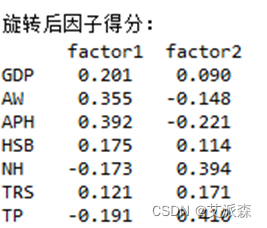
# 因子旋转rotator = Rotator()b = pd.DataFrame(rotator.fit_transform(fa.loadings_))b.columns =tempcolnameb.index = ColNameprint("\n因子旋转:\n", np.round(b,3))因子旋转后的矩阵为:
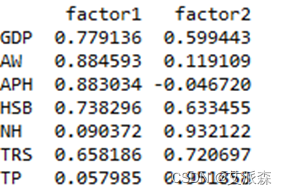
我们可以看到,公共因子factor1与GDP、AW、APH、HSB的相关系数较大;公共因子factor2与NH、TRS、TP的相关系数较大。
再次进行因子分析:
#旋转后因子分析fa = FactorAnalyzer(n_factors=k)fa.loadings_ = bprint(fa.loadings_)print("\n旋转后公共因子方差:\n", fa.get_communalities())var = fa.get_factor_variance() # 给出贡献率print("\n旋转后解释的总方差(即贡献率):\n",var)其结果为:
3.2.8 旋转后的因子得分
计算旋转后的因子得分
# 因子得分X1 = np.mat(DF_corr)X1 = nlg.inv(X1)b = np.mat(b)factor_score = np.dot(X1, b)factor_score = pd.DataFrame(factor_score)factor_score.columns = tempcolnamefactor_score.index = ColNameprint("\n旋转后因子得分:\n", np.round(factor_score,3))其结果为:
3.2.9 计算因子得分
首先,计算三个公共因子的权重:
#求各因子权重AW=np.array(var)AW=AW.TTW=AW[:,1]W=[]for i in range(TW.shape[0]): W.append(TW[i]/sum(TW))print("公共因子权重:\n",W)其结果为:
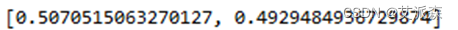
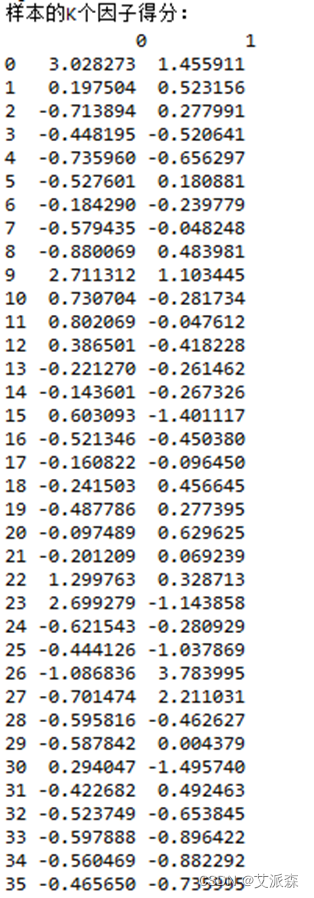
之后计算各省份的因子得分:
#计算样本得分fa_t_score = np.dot(np.mat(dataz), np.mat(factor_score))print("样本的K个因子得分:\n",pd.DataFrame(fa_t_score)) 计算结果为:
3.3 样本综合评分
根据各省份的三个因子得分,按照贡献率进行加权,可得得到各省份最后的综合得分,我们计算各省份的综合得分,并对其进行排名:
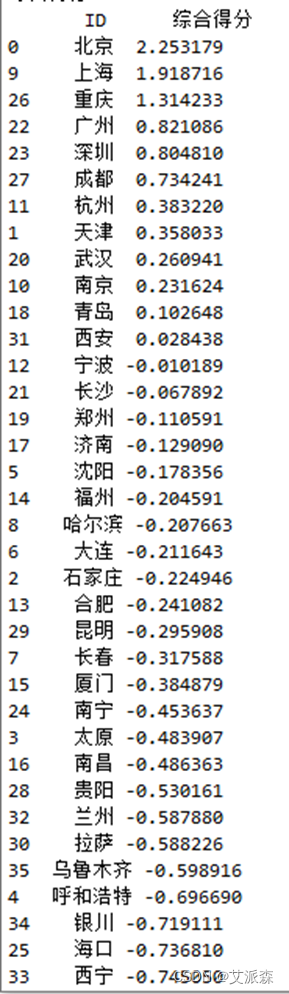
# 综合得分wei = np.mat(W).T #wei为权重向量fa_t_score = np.dot(fa_t_score, wei) fa_t_score = pd.DataFrame(fa_t_score)fa_t_score.columns = ['综合得分']fa_t_score.insert(0,'ID',myID)print("\n综合得分:\n", fa_t_score.sort_values(by='综合得分', ascending=False))计算结果为:
最后的评分结果我们可以使用条形图来表示:
myname=np.array(fa_t_score["ID"])mydata=np.array(fa_t_score["综合得分"])draw_hist(myname,mydata)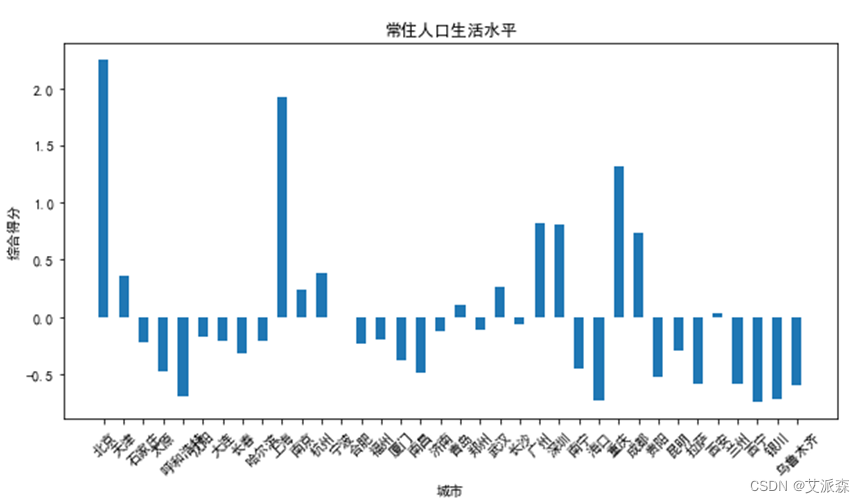 依据我们所选择的指标进行评分,北京、上海、重庆、广州、深圳的常住居民的生活水平较高,位列前五名。从原始数据来看,这几个城市的平均工资、居民储蓄年末余额等,与其他市场相比都是比较高的,因此,该得分较为合理。另外,乌鲁木齐、呼和浩特、银川、海口、西宁五个城市的生活水平较低,排名靠后,这几个城市受限于地理位置、资源等因素,经济发展较为落后,总体评分较低。
依据我们所选择的指标进行评分,北京、上海、重庆、广州、深圳的常住居民的生活水平较高,位列前五名。从原始数据来看,这几个城市的平均工资、居民储蓄年末余额等,与其他市场相比都是比较高的,因此,该得分较为合理。另外,乌鲁木齐、呼和浩特、银川、海口、西宁五个城市的生活水平较低,排名靠后,这几个城市受限于地理位置、资源等因素,经济发展较为落后,总体评分较低。
四、实验总结
本文使用因子分析法来评估各个省会城市以及直辖市常住人口的生活水平,首先对7个因子进行分析,综合得到两个公共因子,计算公共因子得分及其权重,最后计算出各个城市的综合得分,依据得分高低对城市进行排序。选择的数据虽然适合用因子分析法来分析,但只选取了7个因子指标,指标量较少,最后得到的公共因子也只有两个。另外,评价一个城市居民的生活水平不仅要从经济方面来评价,还有考虑交通、环境等因素,而本文选取的多为经济方面的评价因子,所以最后的评分结果可能有失偏颇,希望以后在选取评价因子时能有所改进。
文末福利
书籍介绍:
本书是一本非互联网行业的新媒体运营案头书,从公众号到视频号,从抖音到小红书,从公域到私域……凡涉及新媒体运营,你想了解的、掌握的,这里全都有。含认知、思维、技巧、方法、底层逻辑,大量真实实训案例来自中国移动、招商银行、海尔集团、中国石油等“大厂”。拒绝“套路式技巧”,学只学“底层逻辑”,新媒体运营全掌握,承包“鱼塘”钓“大鱼”!

内容简介:
本书为非互联网行业的新媒体运营人员量身定制,深度梳理实际运营工作中的重难点,提供快速成长的可复制经验。作者傅一声是200多家企业的新媒体辅导老师,书中内容基于真实的企业和个人新媒体运营场景撰写,实操性极强。
全书共分为8章,不仅包含对新媒体运营地图、运营思维、文案写作、短视频运营、直播运营的介绍,还详细讲解了抖音等公域平台的运营、企业微信等私域平台的运营,以及新媒体运营中常见的问题。
本书所有案例均来自近年作者亲自操盘或者参与的项目,玩法新潮,干货满满,实战性强,行文真实幽默且有趣有料,堪称非互联网行业新媒体从业人员、新媒体爱好者的必备宝典。
北京大学出版社,4月“423世界读书日”促销活动安排来啦!
当当活动日期:4.6-4.11,4.18-4.23
京东活动日期: 4.6 一天, 4.17-4.23
活动期间满100减50或者半价5折销售
希望大家关注参与423读书日北大社促销活动
参与福利
- 参与方式:关注博主、点赞、评论
- 福利:届时选取评论区点赞数最高两位小伙伴送出《运营之巅》
- 截止时间:2023-4-10 20:00:00
- 迫不及待的小伙伴可前往当当自营店购买(下单后记得私信我)链接如下:http://product.dangdang.com/29473785.html
来源地址:https://blog.csdn.net/m0_64336780/article/details/130020026
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












