

springboot jpaRepository为什么一定要对Entity序列化


这篇文章主要介绍“springboot jpaRepository为什么一定要对Entity序列化”,在日常操作中,相信很多人在springboot jpaRepository为什么一定要对Entity序列化问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”springboot jpaRepository为什么一定要对Entity序列化”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
springboot jpaRepository对Entity序列化
1. 问题
一开始,我没有对实体类Inventory序列化,导致在使用内嵌数据库H2的JPA时,它直接安装字母序列把表Inventory的字段生成。
举例,原来我按照
inventory(id, name, quantity, type, comment)顺序写的数据库导入表,但是因为没有序列化,导致表结构变成
inventory(id, comment,name, quantity, type )所以后面JPA处理失败。
2. 写个基本的JpaRepository的使用
顺便记录一下写spring cloud 基于和H2 database的jpa简单restful 程序。
实体类Inventory
package com.example.demo; import java.io.Serializable; import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.SequenceGenerator; @Entitypublic class Inventory implements Serializable{ private static final long serialVersionUID = 1L; @Id @SequenceGenerator(name="inventory_generator", sequenceName="inventory_sequence", initialValue = 2) @GeneratedValue(generator = "inventory_generator") private Integer id; @Column(nullable = false) private String name; @Column(nullable = false) private Integer quantity; @Column(nullable = false) private Integer type; @Column(nullable = false) private String comment; public Inventory(Integer id, String name, Integer quantity, Integer type, String comment) { super(); this.id = id; this.name = name; this.quantity = quantity; this.type = type; this.comment = comment; } public Inventory() { super(); } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getQuantity() { return quantity; } public void setQuantity(Integer quantity) { this.quantity = quantity; } public Integer getType() { return type; } public void setType(Integer type) { this.type = type; } public String getComment() { return comment; } public void setComment(String comment) { this.comment = comment; } @Override public String toString() { return "Inventory [id=" + id + ", name=" + name + ", quantity=" + quantity + ", type=" + type + ", comment=" + comment + "]"; }}下面使用JpaRepository简化开发流程,非常舒服地定义简单的service 接口即可,会自动实现,大赞。
package com.example.demo; import org.springframework.data.jpa.repository.JpaRepository; public interface InventoryRepository extends JpaRepository<Inventory, Integer> { Inventory findById(Integer id); }我把controller方法放到了springboot启动类里面,这又是一个大问题,因为我的项目只有放在这才能被dispatcher转发,简直了。
这里的@EnableDiscoveryClient 是因为我在做spring cloud的eureka 服务发现,需要这个注解让注册中心发现这个服务。
package com.example.demo; import java.time.LocalTime; import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.client.discovery.EnableDiscoveryClient;import org.springframework.transaction.annotation.Transactional;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.ResponseBody;import org.springframework.web.bind.annotation.RestController; @SpringBootApplication@EnableDiscoveryClient@RestControllerpublic class InventoryApplication { public static void main(String[] args) { SpringApplication.run(InventoryApplication.class, args); } @Autowired private InventoryRepository inventoryRepository; @Value("${server.port}") private Integer port; @RequestMapping("/info") public String info(){ inventoryRepository.save(new Inventory(1, "火锅底料", 10000, 1, "你吃火锅,我吃底料")); inventoryRepository.save(new Inventory(2, "微服务架构", 100, 2, "微服务还是要考虑 一波")); return "{Inventory[port:"+port+", info:库存微服务"+"]}"; } @GetMapping("/get/{id}") @ResponseBody @Transactional public String getById(@PathVariable("id")Integer id){ return inventoryRepository.findById(id).toString(); } @GetMapping("/") @ResponseBody @Transactional public String re(){ return inventoryRepository.findAll().toString(); } @GetMapping("/delete/{id}") @ResponseBody @Transactional public String delete(@PathVariable("id")Integer id){ inventoryRepository.delete(id); return "delete successfully"; } @GetMapping("/save/id={id}&name={name}&quantity={quantity}&type={type}&comment={comment}") public String save(@PathVariable("id")Integer id,@PathVariable("name")String name, @PathVariable("quantity")Integer quantity,@PathVariable("type")Integer type, @PathVariable("comment")String comment){ inventoryRepository.save(new Inventory(id,name,quantity,type,comment)); System.out.println(new Inventory(id,name,quantity,type,comment)); //强调一下identity和auto return "save successfully"; } @GetMapping("/update/id={id}&name={name}&quantity={quantity}&type={type}&comment={comment}") @ResponseBody @Transactional public String update(@PathVariable("id")Integer id,@PathVariable("name")String name, @PathVariable("quantity")Integer quantity,@PathVariable("type")Integer type, @PathVariable("comment")String comment){ Inventory inventory=inventoryRepository.findById(id); if(inventory.getComment().length()<LocalTime.now().toString().length()){ inventory.setComment(inventory.getComment()+LocalTime.now()); }else{ inventory.setComment(inventory.getComment().substring(0,inventory.getComment().length()- LocalTime.now().toString().length())+LocalTime.now()); } inventoryRepository.save(inventory); inventoryRepository.flush(); return "update successfully"; }}application.properties的配置很关键,搜了不少教程。
spring.jpa.show-sql=truelogging.pattern.level=traceserver.port=8765spring.application.name=inventoryserver.tomcat.max-threads=1000eureka.instance.leaseRenewalIntervalInSeconds= 10eureka.client.registryFetchIntervalSeconds= 5eureka.client.serviceUrl.defaultZone=http://localhost:8889/eureka#eureka.client.service-url.defaultZone=http://${eureka.instance.hostname}:${eureka.instance.server.port}/eureka #spring.thymeleaf.prefix=classpath:/templates/ #spring.thymeleaf.suffix=.html #spring.thymeleaf.mode=HTML5 #spring.thymeleaf.encoding=UTF-8 # ;charset=<encoding> is added #spring.thymeleaf.content-type=text/html # set to false for hot refresh spring.h3.console.enabled=truespring.thymeleaf.cache=false spring.jpa.hibernate.ddl-auto=update#这里是把h3持久化到本地文件夹,这可以保持数据spring.datasource.url=jdbc:h3:file:C\:/h3/h3cache;AUTO_SERVER=TRUE;DB_CLOSE_DELAY=-1logging.file=c\:/h3/logging.loglogging.level.org.hibernate=debug#spring.datasource.data=classpath:import.sql数据库是自动导入的,只要命名方式是import.sql, 放在class="lazy" data-src/main/resources下面就可以
insert into inventory(id, name, quantity, type, comment) values (1, "火锅底料", 10000, 1, "你吃火锅,我吃底料")insert into inventory(id, name, quantity, type, comment) values (2, "微服务架构", 100, 2, "微服务还是要考虑 一波")最后一个简单的测试
junit测试一波
package com.example.demo; import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class)@SpringBootTestpublic class InventoryApplicationTests { @Autowired private InventoryRepository inventoriRepository; @Test public void test2() { System.out.println(inventoriRepository.findAll()); } }
上图是项目结构图
springboot 使用JpaRepository
在对数据库操作时使用 MissionInfoRepository,对应的实体类必须用下面两个注解修饰
@Entity@Table(name = "mission_info")主键用下面修饰
@Id @GeneratedValue(strategy = IDENTITY) @Column(name = "id", nullable = false)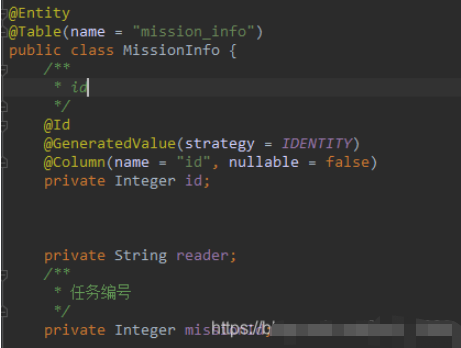
到此,关于“springboot jpaRepository为什么一定要对Entity序列化”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














