

Python利器openpyxl之操作excel表格的示例分析


这篇文章将为大家详细讲解有关Python利器openpyxl之操作excel表格的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
python处理数据时,可以将数据保存至excel文件中,此处安利一个python利器,openpyxl,可以自动化处理数据值excel表格中。
1、安装
pip install openpyxl
2、使用
在使用前,需理清excel的几个概念
workbook:工作薄,即一个excel文件
worksheet:工作表,一个excel文件包含多个sheet,即包含多个工作表
colunm:列,excel中一竖列
row:行,excel中一横行
cell:单元格,组成工作表的最小单位
2.1 Workbook对象
创建工作薄
from openpyxl import Workbook# 创建一个工作簿w=Workbook()# 获取当前工作sheetw_s=w.active# 指定sheet的标题w_s.title="demo1"# 创建一个工作表,index指定创建的工作表的位置,默认在最后面,title指定工作表的名称w_s=w.create_sheet(index=0, title="demo2")# 指定sheet按钮的颜色w_s.sheet_properties.tabColor="FFA500"# 保存文件w.save('data/demo.xlsx')其中当创建一个一个工作簿时,会默认创建一个名字为Sheet的工作表。以下即上面代码所创建的excel工作簿(即excel文件)
加载工作簿
from openpyxl import load_workbook# 打开一个工作簿,w=load_workbook("data/demo.xlsx")# 获取工作簿下所有工作表的名称,以下两种用法作用一样,官方推荐第一种第一种用法sheet_names1=w.sheetnames# sheet_names2=w.get_sheet_names()# 指定当前工作表,以下两种用法作用一样,官方推荐第一种第一种用法w_s1=w["demo1"]# w_s2=w.get_sheet_by_name("demo2")# 删除一个工作表w.remove(w["demo2"])sheet_names2=w.sheetnames# 保存文件w.save('data/demo.xlsx')print(sheet_names1)print(sheet_names2)>>>输出结果['demo2', 'demo1']['demo1']2.2 worksheet对象
常用属性
title:表格的标题
dimensions:表格的大小,这里的大小是指含有数据的表格的大小,即:左上角的坐标:右下角的坐标,
max_row:表格的最大行
min_row:表格的最小行
max_column:表格的最大列
min_column:表格的最小列
rows:按行获取单元格(Cell对象) - 生成器
columns:按列获取单元格(Cell对象) - 生成器
freeze_panes:冻结窗格,冻结单元格上边所有行和左边所有列,但单元格所在行列不冻结 ,在果冻页面时,冻结的行和列始终保持不动
values:按行获取表格的内容(数据) - 生成器
常用方法
iter_rows:按行获取所有单元格,内置属性有(min_row,max_row,min_col,max_col)
iter_cols:按列获取所有的单元格
append:在表格末尾添加数据,参数为一列表或者元祖
merge_cells:合并多个单元格
unmerge_cells:移除合并的单元格
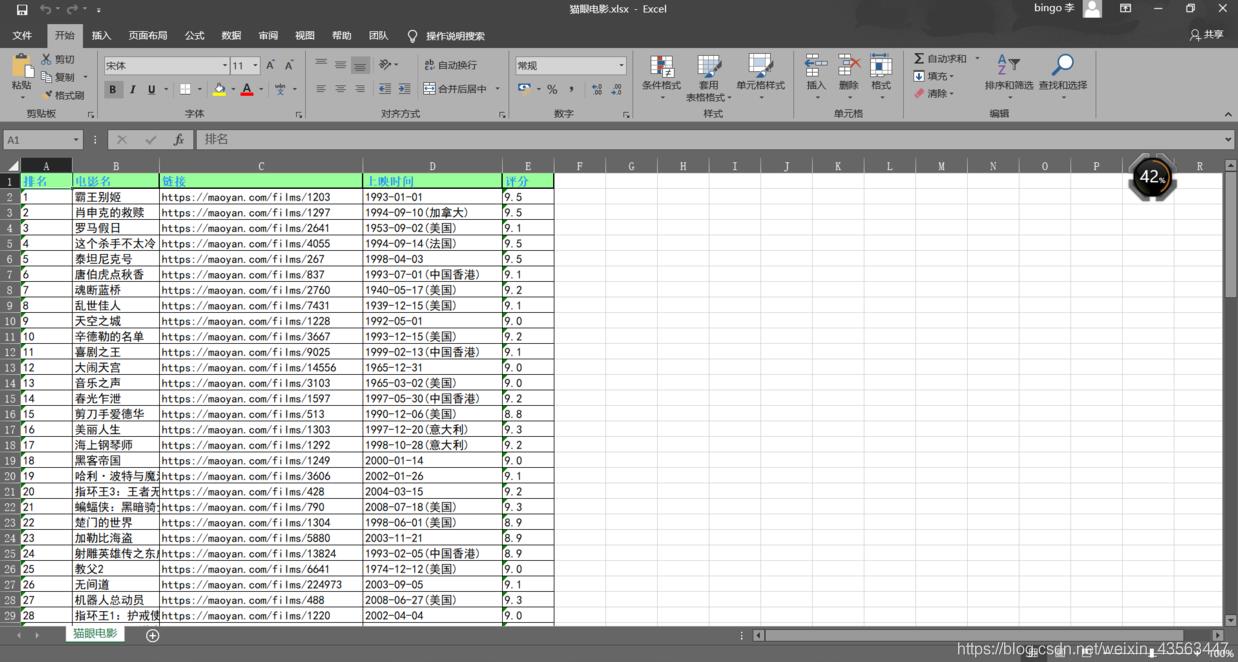
现在有这样一个excel表格:
from openpyxl import load_workbookw=load_workbook("data/猫眼电影.xlsx")w_s=w[w.sheetnames[0]] # 选择第一个工作表print("工作表标题:",w_s.title)print("工作表最大行数:",w_s.max_row)print("工作表最小行数:",w_s.min_row)print("工作表的大小(左上角到右下角的坐标):",w_s.dimensions)print("工作表最大列数:",w_s.max_column)print("工作表最小列数",w_s.min_column)w_s.freeze_panes="B2" # 冻结第一列和第一行,# w_s.freeze_panes = 'B1' # 冻结列A# w_s.freeze_panes = 'C1' # 冻结列A和B# w_s.freeze_panes = 'C2' # 冻结行1和列A和列B# w_s.freeze_panes = 'A1' # 无冻结# w_s.freeze_panes = None # 无冻结# w_s.freeze_panes = 'A2' # 设置第一行为冻结w.save("data/猫眼电影.xlsx")>>>输出结果工作表标题: 猫眼电影工作表最大行数: 101工作表最小行数: 1工作表的大小(左上角到右下角的坐标): A1:E101工作表最大列数: 5工作表最小列数 1from openpyxl import load_workbookw=load_workbook("data/猫眼电影.xlsx")w_s=w[w.sheetnames[0]] # 选择第一个工作表# 获取第一行所有cell,返回一个生成器rows=w_s.iter_rows(min_row=1,max_row=1,min_col=1)# 获取第一行的第一行到第五行的cell,返回一个生成器cols=w_s.iter_cols(min_col=1,max_col=1,min_row=1,max_row=5)for row in rows: print(row)for col in cols: print(col)# 写入一行数据w_s.append([1,2,3,4,5])# 合并单元格,A1至D1合并到A1w_s.merge_cells('A1:D1')# 拆分单元格,此处需要注意的是若先合并再拆分单元格,拆分后的单元格不再恢复拆分前的格式和数值w_s.unmerge_cells('A1:D1')w.save("data/猫眼电影.xlsx")>>>输出结果(<Cell '猫眼电影'.A1>, <Cell '猫眼电影'.B1>, <Cell '猫眼电影'.C1>, <Cell '猫眼电影'.D1>, <Cell '猫眼电影'.E1>)(<Cell '猫眼电影'.A1>, <Cell '猫眼电影'.A2>, <Cell '猫眼电影'.A3>, <Cell '猫眼电影'.A4>, <Cell '猫眼电影'.A5>)如下图,合并再拆分,cell之前的格式和值时不再存在。
2.3 Cell对象
获取cell方法
通过坐标定位的方法
cell1=w_s["A"][:5]cell2=w_s["A5"]通过iter_rows()迭代方法,指定行列范围
rows = w_s.iter_rows(min_col=1, max_col=w_s.max_column, min_row=1, >max_row=1)for row in rows: for cell in row: print(cell)print("+"*20)cols = w_s.iter_cols(min_row=1, max_row=5, min_col=1, max_col=1)for col in cols: for cell in col: print(cell)>>>输出结果<Cell '猫眼电影'.A1><Cell '猫眼电影'.B1><Cell '猫眼电影'.C1><Cell '猫眼电影'.D1><Cell '猫眼电影'.E1>++++++++++++++++++++<Cell '猫眼电影'.A1><Cell '猫眼电影'.A2><Cell '猫眼电影'.A3><Cell '猫眼电影'.A4><Cell '猫眼电影'.A5>通过指定具体行列方法
cell3=w_s.cell(row=1,column=1)迭代全部行或列
for row in w_s.rows: for cell in row: cell.value=None for column in w_s.columns: for cell in column: cell.value=None迭cell赋值
cell.value="xxx"
4 样式设置
目前官方提供的styles提供的样式有以下几块:
Font: 来设置文字的大小,颜色和下划线等
PatternFill: 填充图案和渐变色
Border: 单元格的边框
Alignment: 单元格的对齐方式等
Font:
from openpyxl.styles import Fontfont = Font(name='宋体',size = 11,bold=True,italic=True,strike=True,color='000000')cell.font = font设置字体为“宋体”,大小为11,bold为加粗,italic为斜体,strike为删除线,颜色为黑色
PatternFill:
from openpyxl.styles import PatternFillfill = PatternFill(fill_type = "solid", fgColor="9AFF9A")cell.fill = fillfill_type指定填充类型,fgColor指定填充颜色(必须为RGB值,RGB颜色对照表)。另外需注意的是,fill_type若没有特别指定>类型,则后续的参数都无效,平时所用也是solid(完全填充,无渐变)和None最多,官方提供的还有
[‘none', ‘solid'', ‘darkDown', ‘darkGray', ‘darkGrid', ‘darkHorizontal', ‘darkTrellis', ‘darkUp', ‘darkVertical', ‘gray0625', ‘gray125', ‘lightDown', ‘lightGray', ‘lightGrid', ‘lightHorizontal', ‘lightTrellis', ‘lightUp', ‘lightVertical', 'mediumGray']
PatternFill:
from openpyxl.styles import Border,Sideborder = Border(left=Side(border_style='thin', color='000000'),right=Side(border_style='thin', color='000000'),top=Side(border_style='thin', color='000000'),bottom=Side(border_style='thin', color='000000'))cell.border = border官方提供的样式还有:
[‘dashDot', ‘dashDotDot', ‘dashed', ‘dotted', ‘double', ‘hair', ‘medium', >‘mediumDashDot', ‘mediumDashDotDot', ‘mediumDashed', ‘slantDashDot', ‘thick', 'thin']
Alignment:
from openpyxl.styles import Alignmentalign = Alignment(horizontal=‘left',vertical=‘center',wrap_text=True)cell.alignment = alignhorizontal: 水平方向对齐方式,左对齐left,居中center和右对齐right,分散对齐distributed,跨列居中centerContinuous,两端对齐justify,填充fill,常规general
vertical:垂直方向对齐方式,居中center,靠上top,靠下bottom,两端对齐justify,分散对齐distributed
wrap_text:自动换行
3、案例
掌握以上就基本平时够用了,自己写了一个案例。
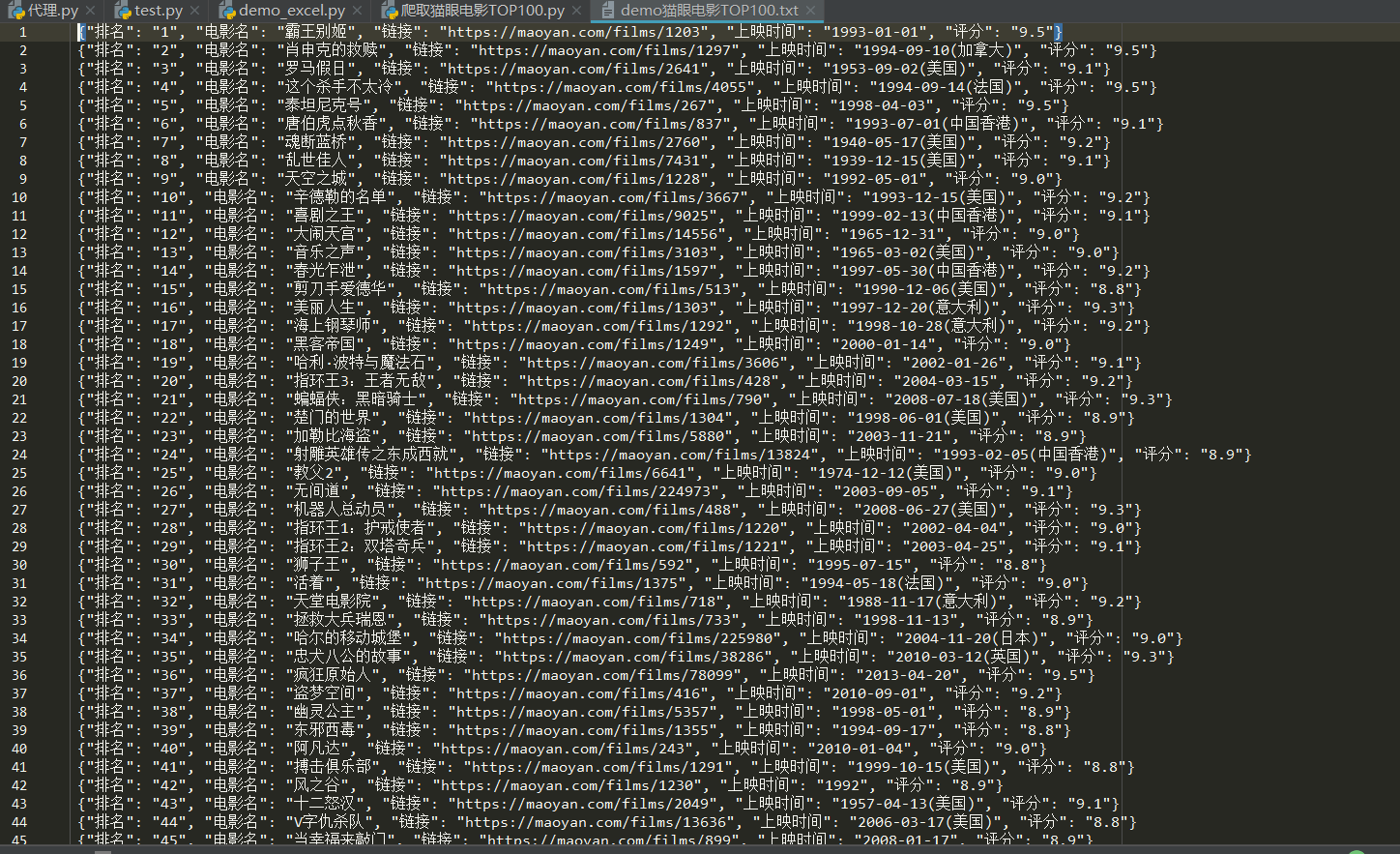
现在有这样一个txt文件,需要把它写进excel文件中
代码如下:
from openpyxl import Workbookimport jsonfrom openpyxl.styles import Font, PatternFill, Alignment, Border, Side# 定义表头的样式style_head = { "border": Border(left=Side(style='medium', color='FF000000'), right=Side(style='medium', color='FF000000'), top=Side(style='medium', color='FF000000'), bottom=Side(style='medium', color='FF000000')), "fill": PatternFill("solid", fgColor="9AFF9A"), "font": Font(color="1E90FF", bold=True), "alignment": Alignment(horizontal="center", vertical="center")}# 定义表内容样式style_content = { "border": Border(left=Side(style='thin', color='FF000000'), right=Side(style='thin', color='FF000000'), top=Side(style='thin', color='FF000000'), bottom=Side(style='thin', color='FF000000')), "alignment": Alignment(horizontal='left', vertical='center'), "font": Font(name="黑体")}def get_data(): with open("data/demo猫眼电影TOP100.txt", 'r', encoding='UTF8') as f: # 迭代读取文件的每一行 for line in f.readlines(): # 将读取到的内容转化为python对象 data = json.loads(line) yield datadef write_to_excel(): # 创建一个工作簿 w = Workbook() # 获取当前工作表 w_s = w.active # 更改当前工作表名称 w_s.title = "猫眼电影" # 设置行的高度 w_s.row_dimensions[1].height = 20 # 设置列的宽度 w_s.column_dimensions["B"].width = 15 w_s.column_dimensions["C"].width = 35 w_s.column_dimensions["D"].width = 24 # 写入表头信息 title = ["排名", "电影名", "链接", "上映时间", "评分"] w_s.append(title) # 迭代方式取出表头(第一行)每个cell,指定样式 for row in w_s.iter_rows(max_row=1, min_col=1): for cell in row: cell.border = style_head["border"] cell.fill = style_head["fill"] cell.font = style_head["font"] cell.alignment = style_head["alignment"] # 从txt文件中获取相关数据 datas = get_data() for data in datas: # 写入表内容 w_s.append(list(data.values())) # 迭代方式取出表中每个cell,指定样式 for row in w_s.iter_rows(min_row=2, min_col=1): for cell in row: cell.border = style_content["border"] cell.alignment = style_content["alignment"] cell.font = style_content["font"] # 保存excel文件 w.save("data/猫眼电影.xlsx")if __name__ == "__main__": write_to_excel()完成后:
关于“Python利器openpyxl之操作excel表格的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












