

基于SCN增量恢复DG同步


问题描述:做scn恢复备库的测试,吭哧了几天,今天终于可以记录一下,遇到了很多坑,作为初学者可以更好地理解DG,主要先关闭备库,在主库做归档丢失备库无法同步,备库产生GAP,然后增量备份恢复备库,版本:SQL*Plus: Release 11.2.0.4.0 Production on Thu Nov 28 09:33:14 2019
备库操作:关闭备库,关闭之前首先要检查一下主备是否同步,否则会产生一些不必要的麻烦
SQL> select process,client_process,sequence#,status,block#,blocks from v$managed_standby; 检查一下备库进程,mrp进程正在等待应用进程,然后就需要重新应用一下保持DG同步

SQL> recover managed standby database cancel; 关闭一下实时应用
SQL> select process,client_process,sequence#,status,BLOCK#,BLOCKS from v$managed_standby; 这个时候实时应用关闭,mrp进程是被关掉的,日志中都可以看到

SQL> alter database recover managed standby database using current logfile disconnect from session; 开启实时同步,这个时候mrp进程是起来的

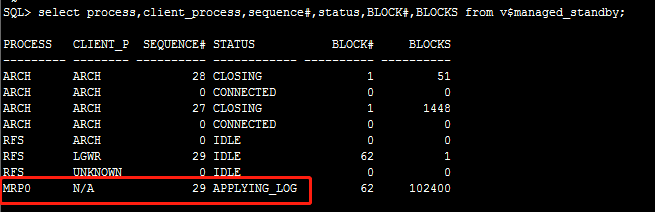
SQL> select process,client_process,status,sequence#,block#,blocks from v$managed_standby; 查询一下wait状态变成了applying应用状态

关闭备库,前边都是废话,检查一下备库是否同步,下边取消实时应用,也就是关掉
SQL> recover managed standby database cancel;
SQL> shutdown immediate

3.主库上操作:模拟归档丢失,这时备库的已经关掉
SQL> alter system switch logfile;

SQL> select max(sequence#) from v$archived_log; 查询一下归档序号到了24号

SQL> archive log list 这里写一下查找归档路径的方法,不用在意我这里的归档号,这是后来补上的图,当时没做这个操作,查到路径在USE_DB_RECOVERY_FILE_DEST,这是系统默认的闪回去内,这里也可以修改的。

SQL> show parameter log_archive_dest_1

SQL> desc v$archived_log

SQL> select name from v$archived_log; 按照这个步骤来可以找到归档的路径

[root@orcl ~]# cd /home/oracle/flashdata/ORCL/archivelog/2019_11_27/ 找到该路径,我切换了两次,所以序列号到24

这里对比一下备库的序列号,注意这里是备库截至到序列号是22,下边是我遇到的一个大坑

这里让主库模拟丢失的本来是23和24,但是备库一直出现不了GAP的状态,后来一看备库日志说的是23已经再被运输中(in transit),所以说这里如果备库重新启动23是直接被应用的,如果把23号归档mv掉,是产生不了GAP的,所以要模拟mv掉归档 就mv 24号归档,也就是切换的第二个归档,这里需要注意下

主库继续模拟丢失归档
[root@orcl 2019_11_27]# mv o1_mf_1_24_gxx0qq27_.arc /tmp 这里我随便挪到一个目录下

备库上:启动备库,查看GAP
SQL> startup mount
SQL> recover managed standby database using current logfile disconnect from session;
SQL> select process,client_process,sequence#,status,BLOCK#,BLOCKS from v$managed_standby; 已经可以看到mrp进程正在等待GAP24号

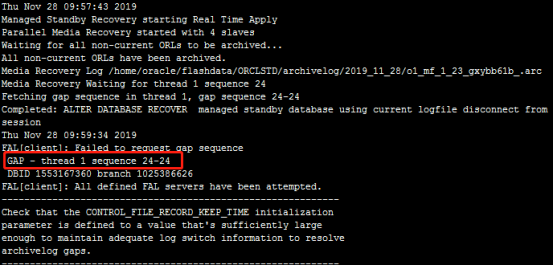
这个是日志截图都是gap24号
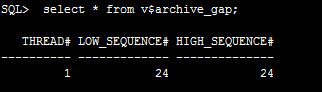
SQL> select * from v$archive_gap; 这些都可以查到
主库上:查询到24号归档的scn号,然后做增量备份,这里要做的是在主库上查询到24号归档的scn号,也就是在对24号归档做操作之前的记录,然后在备库增量恢复
SQL> select FIRST_CHANGE# from v$archived_log where SEQUENCE# =24; 查询到24号归档之前的操作

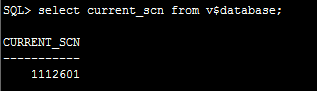
SQL> select current_scn from v$database; 确认一下24号scn号的范围怎么样,这里是当前的归档号
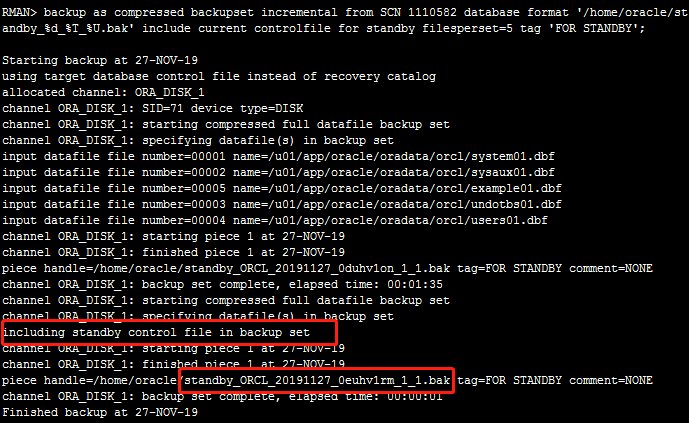
主库上做基于1110582的备份
[oracle@orcl ~]$ rman target /
RMAN> backup as compressed backupset incremental from SCN 1110582 database format "/home/oracle/standby_%d_%T_%U.bak" include current controlfile for standby filesperset=5 tag "FOR STANDBY"; 这里要看一下哪个是控制文件,以及rman备份文件的权限问题
这里查看一下备份的文件

传输到备库 /home/oracle下
[oracle@orcl ~]$ scp *.bak 192.168.1.5:/home/oracle

10.在备库上进行恢复scn号,首先恢复控制文件
[root@orclstd oracle]# su - oracle
[oracle@orclstd ~]$ rman target /
RMAN> restore standby controlfile from "/home/oracle/standby_ORCL_20191127_0euhv1rm_1_1.bak";

RMAN> alter database mount; 到mount状态
RMAN> catalog start with"/home/oracle"; 注册一下传输过来的备份,这里rman有一个文件头损坏的报错,这里不影响后边的报错,但是我没有理解
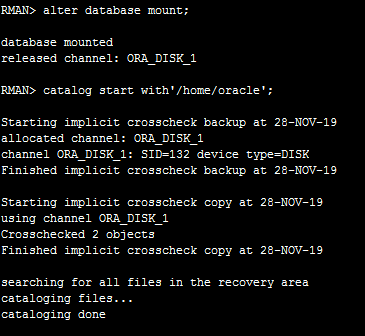
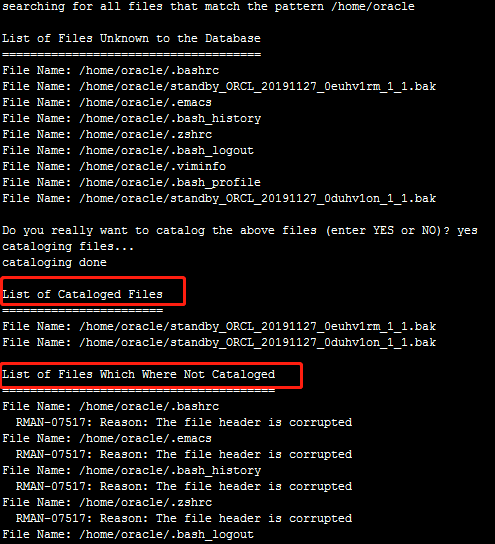
RMAN> recover database noredo; 增量恢复备份文件
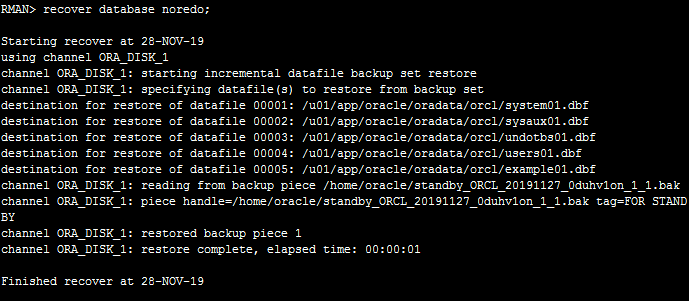
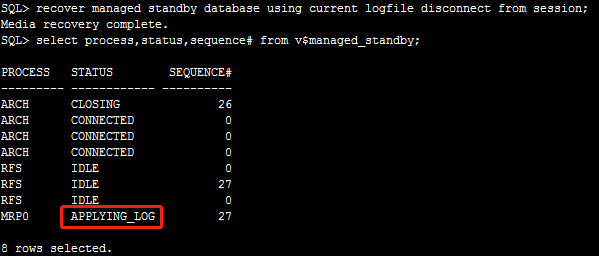
验证,这里状态都变成了应用日志,这里也可以在主库多切换几次日志,看看备库有没有实时同步
SQL> recover managed standby database using current logfile disconnect from session;
Media recovery complete.
SQL> select process,status,sequence# from v$managed_standby;
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












