

LangChain入门指南

LangChain入门
什么是LangChain
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
官方文档:https://python.langchain.com/en/latest/
中文文档:https://www.langchain.com.cn/
如何使用 LangChain?
要使用 LangChain,开发人员首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
LangChain 为特定用例提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互、提取、评估和汇总。
LangChain的模型
LangChain model 是一种抽象,表示框架中使用的不同类型的模型。LangChain 中的模型主要分为三类:
1.LLM(大型语言模型):这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
2.聊天模型( Chat Model):聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
3.文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
LangChain 的主要特点
LangChain 旨在为六个主要领域的开发人员提供支持:
1.LLM 和提示:LangChain 使管理提示、优化它们以及为所有 LLM 创建通用界面变得容易。此外,它还包括一些用于处理 LLM 的便捷实用程序。
2.链(Chain):这些是对 LLM 或其他实用程序的调用序列。LangChain 为链提供标准接口,与各种工具集成,为流行应用提供端到端的链。数据增强生成:
3.LangChain 使链能够与外部数据源交互以收集生成步骤的数据。例如,它可以帮助总结长文本或使用特定数据源回答问题。
4.Agents:Agents 让 LLM 做出有关行动的决定,采取这些行动,检查结果,并继续前进直到工作完成。LangChain 提供了代理的标准接口,多种代理可供选择,以及端到端的代理示例。
5.内存:LangChain 有一个标准的内存接口,有助于维护链或代理调用之间的状态。它还提供了一系列内存实现和使用内存的链或代理的示例。
6.评估:很难用传统指标评估生成模型。这就是为什么 LangChain 提供提示和链来帮助开发者自己使用 LLM 评估他们的模型。
使用示例
LangChain 支持大量用例,例如:
针对特定文档的问答:根据给定的文档回答问题,使用这些文档中的信息来创建答案。聊天机器人:构建可以利用 LLM 的功能生成文本的聊天机器人。Agents:开发可以决定行动、采取这些行动、观察结果并继续执行直到完成的代理。快速入门指南:使用 LangChain 构建端到端语言模型应用程序
[OPENAI_API_KEY可以去官网生成(调用接口要钱,比较便宜)]
安装
首先,安装 LangChain。只需运行以下命令:
pip install langchain环境设置现在,由于 LangChain 经常需要与模型提供者、数据存储、API 等集成,我们将设置我们的环境。在这个例子中,我们将使用 OpenAI 的 API,因此我们需要安装他们的 SDK:pip install openai接下来,让我们在终端中设置环境变量:export OPENAI_API_KEY = "..."或者,如果您更喜欢在 Jupyter notebook 或 Python 脚本中工作,您可以像这样设置环境变量:import os os .environ[ "OPENAI_API_KEY" ] = "..."构建语言模型应用程序:LLM
# 导入LLM包装器。 from langchain.llms import OpenAI # 初始化包装器,temperature越高结果越随机 llm = OpenAI(temperature=0.9) # 进行调用 text = "What would be a good company name for a company that makes colorful socks?" print(llm(text)) #生成结果,结果是随机的 例如: Glee Socks. Rainbow Cozy SocksKaleidoscope Socks.Prompt Templates: 管理LLMs的Prompts
一般来说我们不会直接把输入给模型,而是将输入和一些别的句子连在一起,形成prompts之后给模型。
例如之前根据产品取名的用例,在实际服务中我们可能只想输入"socks",那么"What would be a good company name for a company that makes"就是我们的template。
from langchain.prompts import PromptTemplate prompt = PromptTemplate( input_variables=["product"], template="What is a good name for a company that makes {product}?", ) print(prompt.format(product="colorful socks")) # 输出结果 What is a good name for a company that makes colorful socks?构建语言模型应用程序:Chat Model
还可以使用聊天模型。这些是语言模型的变体,它们在底层使用语言模型但具有不同的界面。聊天模型使用聊天消息作为输入和输出,而不是“文本输入、文本输出”API。聊天模型 API 的使用还比较新,所以大家都还在寻找最佳抽象使用方式。
要完成聊天,您需要将一条或多条消息传递给聊天模型。LangChain 目前支持 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 类型。您将主要使用 HumanMessage、AIMessage 和 SystemMessage。
from langchain.chat_models import ChatOpenAIfrom langchain.schema import ( AIMessage, HumanMessage, SystemMessage)chat = ChatOpenAI(temperature=0)chat([HumanMessage(content="Translate this sentence from English to French. I love programming.")])#输出结果 AIMessage(content="J'aime programmer.", additional_kwargs={})使用 generate 为多组消息生成完成。这将返回一个带有附加消息参数的 LLMResult:
from langchain.chat_models import ChatOpenAIfrom langchain.schema import ( AIMessage, HumanMessage, SystemMessage)batch_messages = [ [ SystemMessage(content="You are a helpful assistant that translates English to Chinese."), HumanMessage(content="Translate this sentence from English to Chinese. I love programming.") ], [ SystemMessage(content="You are a helpful assistant that translates English to Chinese."), HumanMessage(content="Translate this sentence from English to Chinese. I love artificial intelligence.") ],]result = chat.generate(batch_messages)print(result)
result.llm_output['token_usage']
对于聊天模型,您还可以通过使用 MessagePromptTemplate 来使用模板。您可以从一个或多个 MessagePromptTemplates 创建 ChatPromptTemplate。ChatPromptTemplate 的方法format_prompt返回一个 PromptValue,您可以将其转换为字符串或 Message 对象,具体取决于您是否要使用格式化值作为 LLM 或聊天模型的输入。
from langchain.chat_models import ChatOpenAIfrom langchain.prompts.chat import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate,)chat = ChatOpenAI(temperature=0)template="You are a helpful assistant that translates {input_language} to {output_language}."system_message_prompt = SystemMessagePromptTemplate.from_template(template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])# get a chat completion from the formatted messageschat(chat_prompt.format_prompt(input_language="English", output_language="Chinese", text="I love programming.").to_messages())# -> AIMessage(content="我喜欢编程。(Wǒ xǐhuān biānchéng.)", additional_kwargs={})探索将内存与使用聊天模型初始化的链和代理一起使用。这与 Memory for LLMs 的主要区别在于我们可以将以前的消息保留为它们自己唯一的内存对象,而不是将它们压缩成一个字符串。
from langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate)from langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemoryprompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."), MessagesPlaceholder(variable_name="history"), HumanMessagePromptTemplate.from_template("{input}")])llm = ChatOpenAI(temperature=0)memory = ConversationBufferMemory(return_messages=True)conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)conversation.predict(input="Hi there!")# -> 'Hello! How can I assist you today?'conversation.predict(input="I'm doing well! Just having a conversation with an AI.")# -> "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"conversation.predict(input="Tell me about yourself.")
完整代码
import osos .environ[ "OPENAI_API_KEY" ] = ""from langchain.chat_models import ChatOpenAIfrom langchain.schema import ( AIMessage, HumanMessage, SystemMessage)chat = ChatOpenAI(temperature=0)batch_messages = [ [ SystemMessage(content="You are a helpful assistant that translates English to Chinese."), HumanMessage(content="Translate this sentence from English to Chinese. I love programming.") ], [ SystemMessage(content="You are a helpful assistant that translates English to Chinese."), HumanMessage(content="Translate this sentence from English to Chinese. I love artificial intelligence.") ],]result = chat.generate(batch_messages)print(result)print(result.llm_output['token_usage'])print("********************************************************************")from langchain.chat_models import ChatOpenAIfrom langchain.chat_models import ChatOpenAIfrom langchain import LLMChainfrom langchain.prompts.chat import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate,)chat = ChatOpenAI(temperature=0)template="You are a helpful assistant that translates {input_language} to {output_language}."system_message_prompt = SystemMessagePromptTemplate.from_template(template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])chain = LLMChain(llm=chat, prompt=chat_prompt)print(chain.run(input_language="English", output_language="Chinese", text="I love programming."))print("********************************************************************")from langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate)from langchain.chains import ConversationChainfrom langchain.chat_models import ChatOpenAIfrom langchain.memory import ConversationBufferMemoryprompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."), MessagesPlaceholder(variable_name="history"), HumanMessagePromptTemplate.from_template("{input}")])llm = ChatOpenAI(temperature=0)memory = ConversationBufferMemory(return_messages=True)conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)conversation.predict(input="Hi there!")# -> 'Hello! How can I assist you today?'conversation.predict(input="I'm doing well! Just having a conversation with an AI.")# -> "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"print(conversation.predict(input="Tell me about yourself."))
print("aaaaaaaa")print(sum(range(0,101)))# # 导入LLM包装器。from langchain.llms import OpenAI# 初始化包装器,temperature越高结果越随机import osfrom langchain.prompts import PromptTemplateimport openaifrom langchain.prompts import PromptTemplatefrom langchain.llms import OpenAI#你申请的openai的api keyos .environ[ "OPENAI_API_KEY" ] = ""llm = OpenAI(temperature=0.9)# 进行调用text = "What would be a good company name for a company that makes colorful socks?"print(llm(text))prompt = PromptTemplate( input_variables=["product"], template="What is a good name for a company that makes {product}?",)print(prompt.format(product="colorful socks"))llm = OpenAI(temperature=0.9)prompt = PromptTemplate( input_variables=["product"], template="What is a good name for a company that makes {product}?",)from langchain.chains import LLMChainchain = LLMChain(llm=llm, prompt=prompt)chain.run("colorful socks")def completion(prompt): completions = openai.Completion.create( engine="text-davinci-003", prompt=prompt, max_tokens=1024, n=1, stop=None, temperature=0.8, ) message = completions.choices[0].text return messageprint(completion("中关村科金是一家怎样的公司?"))

信息抽取
根据输入的内容抽取关键信息
from langchain.prompts import PromptTemplatefrom langchain.llms import OpenAIChatfrom langchain.chains import LLMChainimport osimport openai# #你申请的openai的api keyos.environ['OPENAI_API_KEY'] = ''text="北京市(Beijing),简称“京”,古称燕京、北平,是中华人民共和国首都、直辖市、国家中心城市、超大城市,国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心, \ 中国历史文化名城和古都之一。 截至2020年,北京市下辖16个区,总面积16410.54平方千米。 2022年末,北京市常住人口2184.3万人。 \北京市地处中国北部、华北平原北部,东与天津市毗连,其余均与河北省相邻,中心位于东经116°20′、北纬39°56′,是世界著名古都和现代化国际城市, \ 也是中国共产党中央委员会、中华人民共和国中央人民政府和中华人民共和国全国人民代表大会常务委员会所在地。\北京市地势西北高、东南低。西部、北部和东北部三面环山,东南部是一片缓缓向渤海倾斜的平原。境内流经的主要河流有:永定河、潮白河、北运河、拒马河等,\北京市的气候为暖温带半湿润半干旱季风气候,夏季高温多雨,冬季寒冷干燥,春、秋短促。北京被世界城市研究机构GaWC评为世界一线城市, \联合国报告指出北京市人类发展指数居中国城市第二位。 [4] 北京市成功举办夏奥会与冬奥会,成为全世界第一个“双奥之城”。 \2022年,北京市实现地区生产总值41610.9亿元,按不变价格计算,比上年增长0.7%。其中,第一产业增加值111.5亿元,下降1.6%;第二产业增加值6605.1亿元,下降11.4%;第三产业增加值34894.3亿元,增长3.4%。" #加载openai的llmllm = OpenAIChat(model_name="gpt-3.5-turbo") #创建模板fact_extraction_prompt = PromptTemplate( input_variables=["text_input"], template="从下面的本文中提取关键事实。尽量使用文本中的统计数据来说明事实:\n\n {text_input}") #定义chainfact_extraction_chain = LLMChain(llm=llm, prompt=fact_extraction_prompt)facts = fact_extraction_chain.run(text)print(facts)输出结果:

文档问答
import osfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.text_splitter import TokenTextSplitterfrom langchain.llms import OpenAIfrom langchain.chains import ChatVectorDBChainfrom langchain.document_loaders import DirectoryLoaderimport jieba as jbimport openaifiles=['xxx.txt','xxx.txt']import timestart_time = time.time() for file in files: #读取data文件夹中的中文文档 my_file=f"./data/{file}" with open(my_file,"r",encoding='utf-8') as f: data = f.read() #对中文文档进行分词处理 cut_data = " ".join([w for w in list(jb.cut(data))]) #分词处理后的文档保存到data文件夹中的cut子文件夹中 cut_file=f"./data/cut/cut_{file}" with open(cut_file, 'w') as f: f.write(cut_data) f.close() #加载文档loader = DirectoryLoader('./data/cut',glob='**/*.txt')docs = loader.load()#文档切块text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)doc_texts = text_splitter.split_documents(docs)#调用openai Embeddingsa=os.environ["OPENAI_API_KEY"] = ""embeddings = OpenAIEmbeddings(openai_api_key=a)#向量化vectordb = Chroma.from_documents(doc_texts, embeddings, persist_directory="./data/cut")vectordb.persist()#创建聊天机器人对象chainchain = ChatVectorDBChain.from_llm(OpenAI(temperature=0, model_name="gpt-3.5-turbo"), vectordb, return_source_documents=True)def get_answer(question): chat_history = [] result = chain({"question": question, "chat_history": chat_history}) return result["answer"]question = "xxxxxxxxxxx"print(get_answer(question))end_time = time.time() # 程序结束时间run_time = end_time - start_time # 程序的运行时间,单位为秒print(run_time)如果问题及答案在文档中会返回正确的结果,如果不在文本中,则会返回错误信息
可能出现的问题
UnicodeEncodeError: 'gbk' codec can't encode character '\u0643' in position 58: illegal multibyte sequence如果是vscode编辑器可能是电脑设置的问题,解决方法win+i > 时间和语言 > 时间 日期 区域格式设置 >其他时间 日期 区域格式设置>区域更改日期,时间或数字格式> 管理>更改系统区域设置
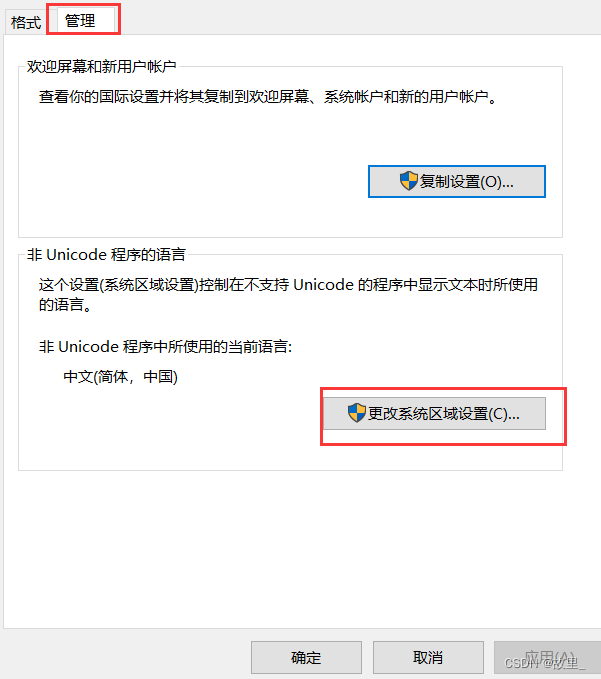
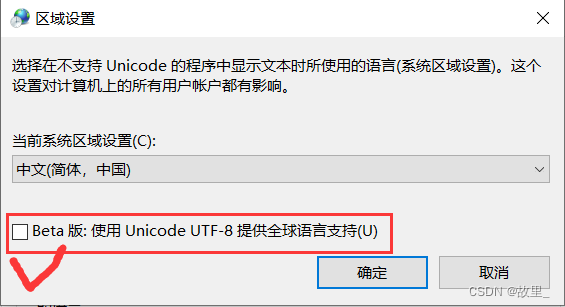
Beta打钩能解决这个问题,这个是针对txt文本(其他文档没试过),出现问题不一定是代码的问题,这个打钩可能会影响电脑其他应用乱码(大部分应用不会)
搜索问答(待更新)
可能出现的问题:
ImportError: cannot import name 'load_tools' from 'langchain.agents'我用的是python3.7,然后将python版本升级到了3.9就解决了。来源地址:https://blog.csdn.net/lht0909/article/details/130412875
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












