



一、 TFTP协议介绍
TFTP(Trivial File Transfer Protocol,简单文件传输协议)
是TCP/IP协议族中的一个用来在客户端与服务器之间进行简单文件传输的协议
特点:
- 简单
- 占用资源小
- 适合传递小文件
- 适合在局域网进行传递
- 端口号为69
- 基于UDP实现
二、TFTP下载过程
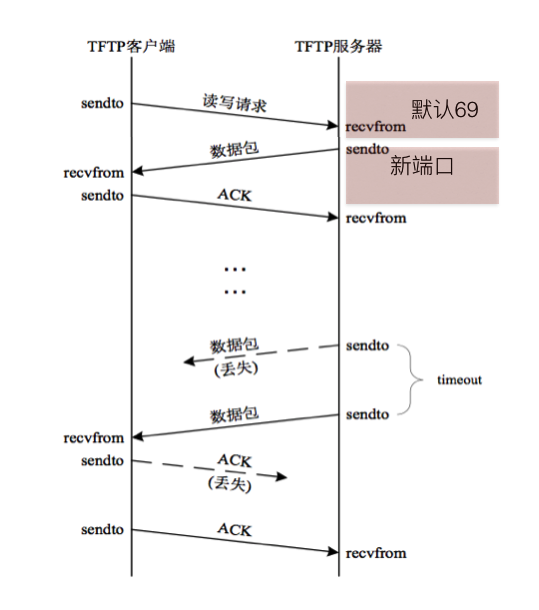
TFTP服务器默认监听69号端口
当客户端发送“下载”请求(即读请求)时,需要向服务器的69端口发送
服务器若批准此请求,则使用一个新的、临时的 端口进行数据传输
1、搜索
当服务器找到需要现在的文件后,会立刻打开文件,把文件中的数据通过TFTP协议发送给客户端
2、分段
如果文件的总大小较大(比如3M),那么服务器分多次发送,每次会从文件中读取512个字节的数据发送过来
3、添加序号
因为发送的次数有可能会很多,所以为了让客户端对接收到的数据进行排序,所以在服务器发送那512个字节数据的时候,会多发2个字节的数据,用来存放序号,并且放在512个字节数据的前面,序号是从1开始的
4、添加操作码
因为需要从服务器上下载文件时,文件可能不存在,那么此时服务器就会发送一个错误的信息过来,为了区分服务发送的是文件内容还是错误的提示信息,所以又用了2个字节 来表示这个数据包的功能(称为操作码),并且在序号的前面

5、发送确认码(ACK)
因为udp的数据包不安全,即发送方发送是否成功不能确定,所以TFTP协议中规定,为了让服务器知道客户端已经接收到了刚刚发送的那个数据包,所以当客户端接收到一个数据包的时候需要向服务器进行发送确认信息,即发送收到了,这样的包成为ACK(应答包)
6.发送完毕
为了标记数据已经发送完毕,所以规定,当客户端接收到的数据小于516(2字节操作码+2个字节的序号+512字节数据)时,就意味着服务器发送完毕了
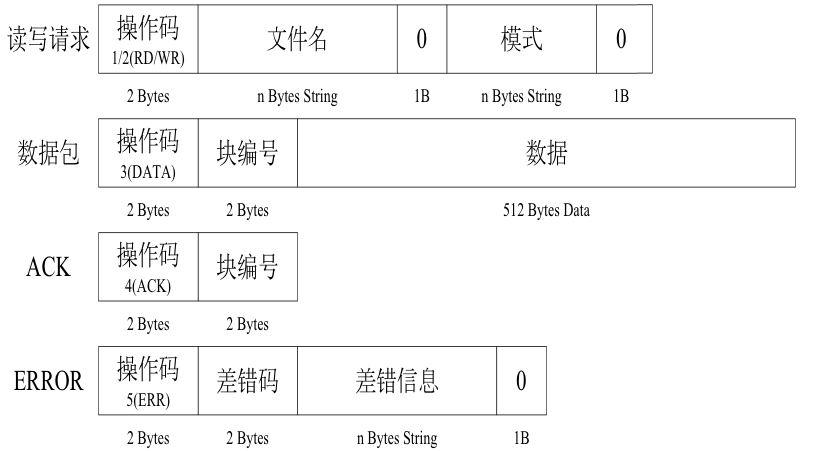
TFTP数据包的格式如下:
三、代码实现
#coding=utf-8
from socket import *
import struct#结构体模块
import sys
if len(sys.argv) != 2:
print('-'*30)
print("tips:")
print("python xxxx.py 192.168.1.1")
print('-'*30)
exit()
else:
ip = sys.argv[1]#从程序外部获取参数
# 创建udp套接字
udpSocket = socket(AF_INET, SOCK_DGRAM)
#构造下载请求数据
cmd_buf = struct.pack("!H8sb5sb",1,"test.jpg",0,"octet",0)
#发送下载文件请求数据到指定服务器
sendAddr = (ip, 69)
udpSocket.sendto(cmd_buf, sendAddr)
p_num = 0
recvFile = ''
while True:
recvData,recvAddr = udpSocket.recvfrom(1024)
recvDataLen = len(recvData)
# print recvAddr # for test
# print len(recvData) # for test
cmdTuple = struct.unpack("!HH", recvData[:4])
# print cmdTuple # for test
cmd = cmdTuple[0]
currentPackNum = cmdTuple[1]
if cmd == 3: #是否为数据包
# 如果是第一次接收到数据,那么就创建文件
if currentPackNum == 1:
recvFile = open("test.jpg", "a")
# 包编号是否和上次相等
if p_num+1 == currentPackNum:
recvFile.write(recvData[4:]);
p_num +=1
print '(%d)次接收到的数据'%(p_num)
ackBuf = struct.pack("!HH",4,p_num)
udpSocket.sendto(ackBuf, recvAddr)
# 如果收到的数据小于516则认为出错
if recvDataLen<516:
recvFile.close()
print '已经成功下载!!!'
break
elif cmd == 5: #是否为错误应答
print "error num:%d"%currentPackNum
break
udpSocket.close()运行效果:
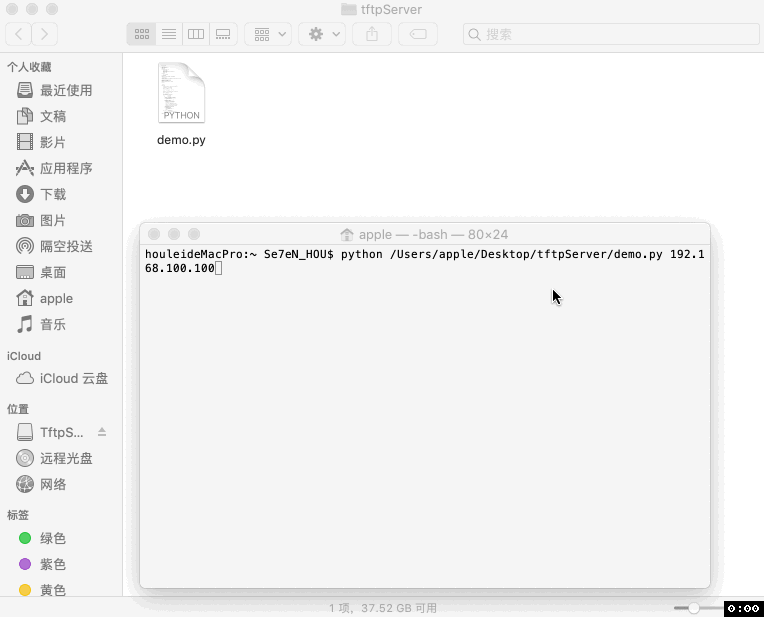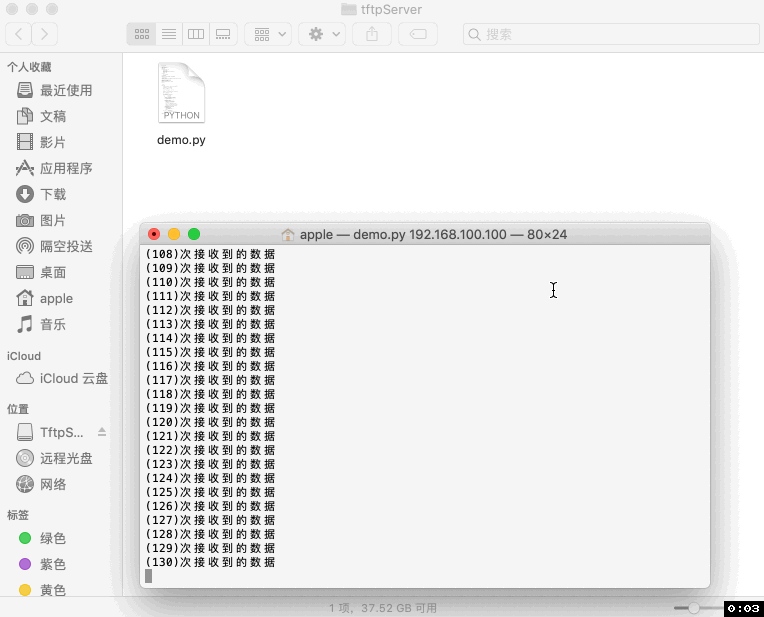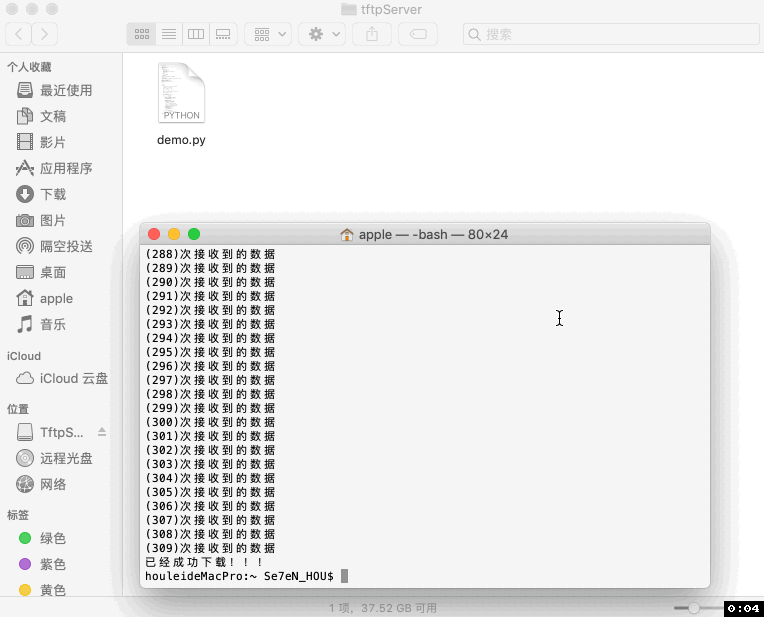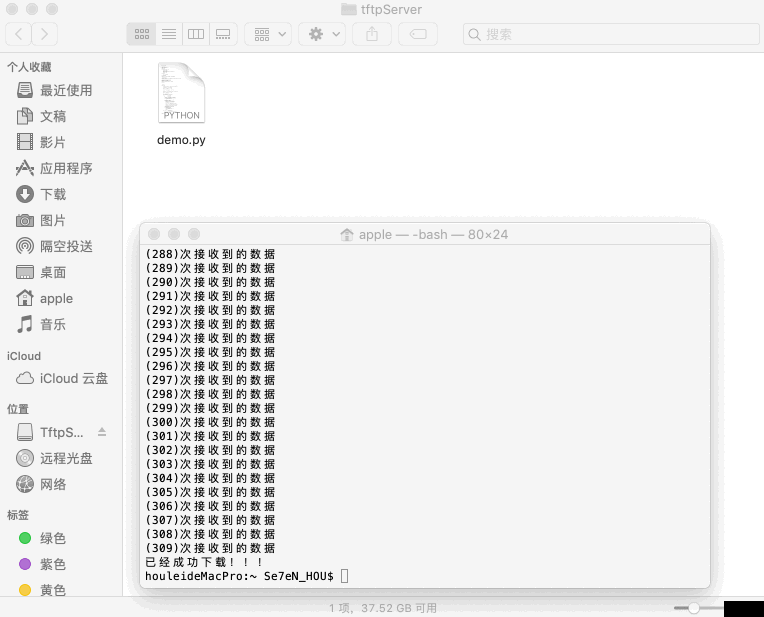
四、代码说明
我们写的是TFTP客户端的代码实现,要想实现客户端的下载功能,首先我们要有一个TFTP服务器,从网上可以下载Tftp32服务器软件
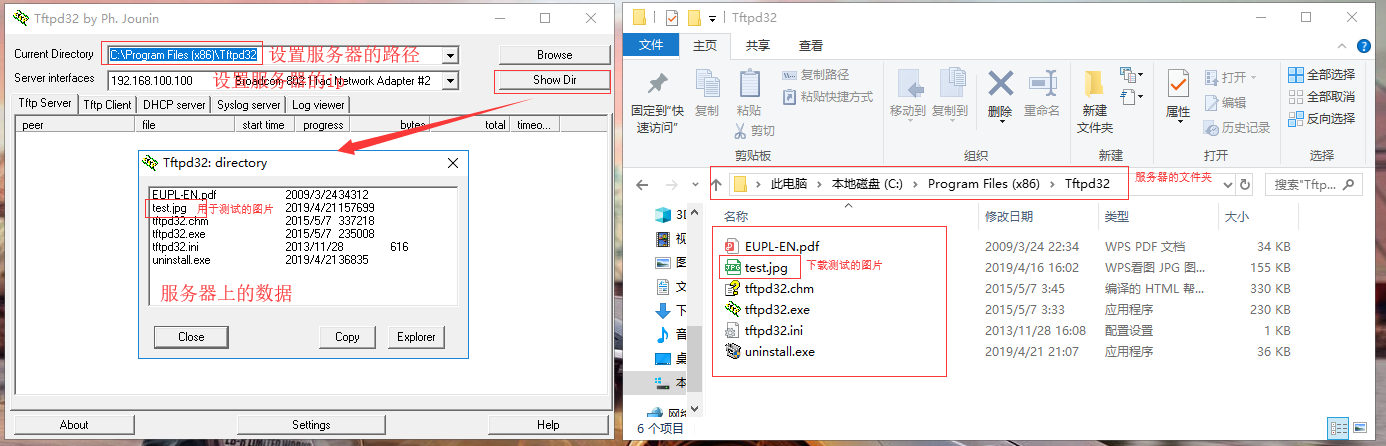
五、struct.pack()和struct.unpack()说明
python中的struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~。一般输入的渠道来源络的二进制流。
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式下面来谈谈主要的方法:
1、struct.pack(fmt,v1,v2,.....)
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串
2、struct.unpack(fmt,string)
顾名思义,解包。比如pack打包,然后就可以用unpack解包了。返回一个由解包数据(string)得到的一个元组(tuple), 即使仅有一个数据也会被解中len(string) 必须等于 calcsize(fmt),这里面涉及到了一个calcsize函数。struct.calcsize(fmt):这个就是用来计算fmt格式所描述的结构的大小。
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照Python manual如下:

import struct
buffer = struct.pack("ihb", 1, 2, 3)
print(buffer)
print(repr(buffer))
print(struct.unpack("ihb", buffer))
print("-----------------------------------")
data = [1, 2, 3]
buffer = struct.pack("!ihb", *data)
print(buffer)
print(repr(buffer))
print(struct.unpack("!ihb", buffer))运行结果为:
b'\x01\x00\x00\x00\x02\x00\x03'
b'\x01\x00\x00\x00\x02\x00\x03'
(1, 2, 3)
-----------------------------------
b'\x00\x00\x00\x01\x00\x02\x03'
b'\x00\x00\x00\x01\x00\x02\x03'
(1, 2, 3)首先将参数1,2,3打包,打包前1,2,3明显属于python数据类型中的integer,pack后就变成了C结构的二进制串,转成 python的string类型来显示就是'\x01\x00\x00\x00\x02\x00\x03'。由于本机是小端('little- endian', 故而高位放在低地址段。i 代表C struct中的int类型,故而本机占4位,1则表示为01000000;h 代表C struct中的short类型,占2位,故表示为0200;同理b 代表C struct中的signed char类型,占1位,故而表示为03。
在Format string 的首位,有一个可选字符来决定大端和小端,列表如下: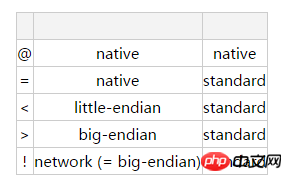
如果没有附加,默认为@,即使用本机的字符顺序(大端or小端),对于C结构的大小和内存中的对齐方式也是与本机相一致的(native),比如有的机器integer为2位而有的机器则为四位;有的机器内存对其位四位对齐,有的则是n位对齐(n未知,我也不知道多少)。还有一个标准的选项,被描述为:如果使用标准的,则任何类型都无内存对齐。比如刚才的小程序的后半部分,使用的format string中首位为!即为大端模式标准对齐方式,故而输出的为'\x00\x00\x00\x01\x00\x02\x03',其中高位自己就被放在内存的高地址位了。












