

HTTP1.0和HTTP1.1和HTTP2.0的主要区别

目录
先上结论,面试常问,同时也是我们学习HTTP协议所必须了解的一些新机制,我们往往学习的都是HTTP1.0的一些基础,1.1 2.0也是企业中常用的东西,也优化了很多nb的属性,下面我们简单来了解下!
HTTP1.0和1.1的区别
长,短连接keep-alive,流水线模式
HTTP 是基于TCP/IP协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要重新建立连接的话,开销会比较大。因此最好能保持一个长连接,同一个c端可以用这个“长连接”来发多个请求。
- 在HTTP/1.0中,默认使用的是短连接,每次请求都要重新建立一次连接;
- 双方建立连接
- C端发出请求信息
- S端回送响应信息
- 双方关掉连接
- HTTP 1.1起,默认使用报保活机制–“长连接” ,默认开启 Connection: keep-alive 报头字段(close代表关闭);
HTTP/1.1的"长连接"机制有非流水线和流水线 两种工作的方式。
- 流水线方式是客户端在收到HTTP的响应报文之前就能接着发送新的请求报文(不断的push请求过去,和工厂流水线一样,让S端处理)。当然,HTTP服务器S端得按照客户请求的顺序响应,以保证客户端能够区分出其每次请求的响应内容。
- 非流水线方式是客户在收到前一个响应后才能发送下一个请求。
注意:
- “长连接”加双引号的原因是HTTP是无状态的,因此他并没有什么长短链接的区别,他本质就是一来一回就断开连接,只是keep-alive 报头字段引入了保活机制,让他看起来像“长链接了”!
新增表示IP内某台主机的Host报头属性
-
HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,但虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。那么我们就需区分这些主机名
-
HTTP1.1的请求消息和响应消息都应支持Host报头属性,他会标识着请求域名内的具体主机,且请求消息中如果没有Host报头属性会报告一个错误(400 Bad Request)。
新增错误状态的响应码409,410
更具体化的像客户端反映了请求错误的信息;
如:
-
409(Conflict)表示请求的资源与资源的当前状态发生冲突;
-
410(Gone)表示服务器上的某个资源被永久性的删除。
节约带宽,断点续传功能range报头
-
HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能;
-
.HTTP1.1则在请求头引入了range报头属性,它1.允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。2.可以实现多线程下载的断点续传
-
HTTP1.1使用时客户端时可以先发送一个只带Host报头属性的请求,如果服务器接收此请求并且回送响应码100,客户端就可以继续发送带实体的完整请求了。原因如下:
100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
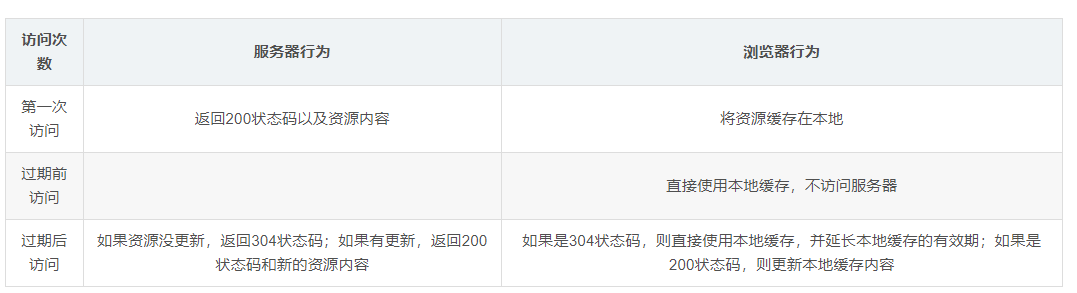
缓存处理Cache-Control报头
有很多种! 简单了解Cache-Control:max-age=N这种: N是缓存有效期限多少秒
比如我们C端对S端两次请求同一张图片或者音频资源:
- 我们c端本地的缓存可能还没过期,直接使用;
- 过期了的话,发送请求给s端,s端检测资源是否变化; 变化返回状态码200,新的资源并且缓存C本地,没变化直接返回304状态码提醒c端延长他本地缓存的生命,并且直接使用;
![在这里插入图片描述]()
HTTP1.1和2.0的区别
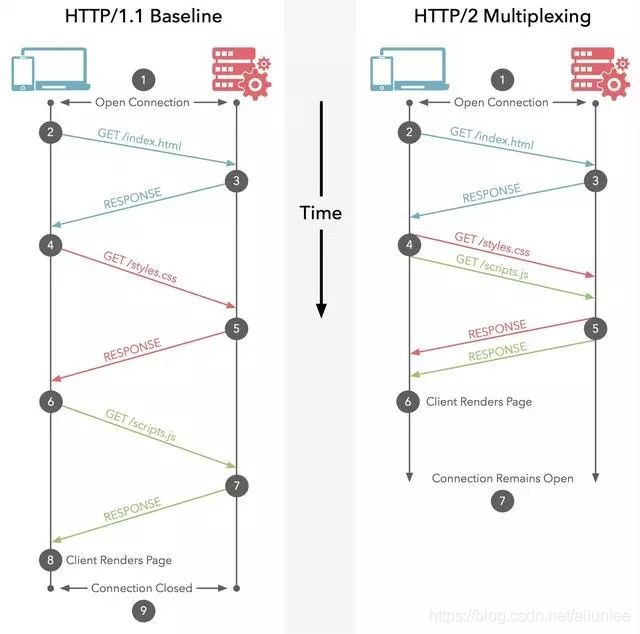
多路复用
HTTP2.0使用了多路复用的技术,做到同一个socket连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。(HTTP1.1也可以多建立几个TCP连接来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。)
头部header数据压缩
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对 header 的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
在HTTP1.1中,HTTP请求和响应都是由状态行(首行)、请求/响应头部(header)、消息主体(body)三部分组成。
一般而言,消息主体body都会经过gzip压缩,或者本身传输的就是压缩过后的二进制文件,但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着Web功能越来越复杂,每个页面产生的请求数也越来越多,导致消耗在头部的流量越来越多,尤其是每次都要传输User-Agent、Cookie这类不会频繁变动的报头字段,完全是一种浪费。
服务器推送server push
为了改善延迟,HTTP2.0引入了server push,它允许在浏览器明确地请求之前,服务端主动推送资源给浏览器,免得客户端再次创建连接发送请求到服务器端获取。这样C端可以直接从本地加载这些资源,不用再通过网络。
服务端推送是一种在C端请求之前S端主动发送数据的机制(注意和1.1的长链接的流水线模式C端连续push请求区分)。
网页使用了许多资源:HTML、样式表、脚本、图片等等。在HTTP1.1中S端要想发送这些资源给C端,那么每一个资源都得收到C端明确地请求。(比如html+css两份需要C端申请两次,S端才能依次全发过去); 这是一个很慢的过程。
来源地址:https://blog.csdn.net/wtl666_6/article/details/128697770
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341




















