

Python机器学习之随机梯度下降法如何实现

本文小编为大家详细介绍“Python机器学习之随机梯度下降法如何实现”,内容详细,步骤清晰,细节处理妥当,希望这篇“Python机器学习之随机梯度下降法如何实现”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
随机梯度下降法
为什么使用随机梯度下降法?
如果当我们数据量和样本量非常大时,每一项都要参与到梯度下降,那么它的计算量时非常大的,所以我们可以采用随机梯度下降法。
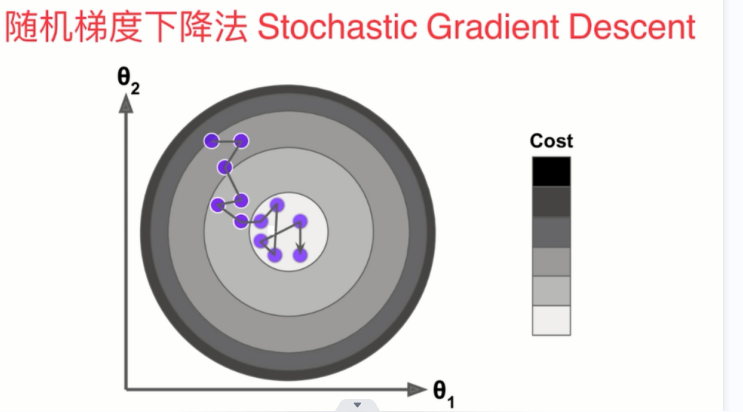
随机梯度下降法中的学习率必须是随着循环的次数增加而递减的。如果eta取一样的话有可能在非常接近我们的最优值时会跳过,所以随着迭代次数的增加,学习率eta要随之减小,我们可以用模拟退火的思想实现(如下图所示),t0和t1是一个常数,定值,其通常是根据经验取得一些值。

随机梯度下降法的实现
随机梯度下降法的公式如下图所示,其中挑出一个样本出来计算。

先创建x,y,以下取10000个样本
import numpy as npm = 10000x = np.random.random(size=m)y = x*3 + 4 + np.random.normal(size=m)写入函数
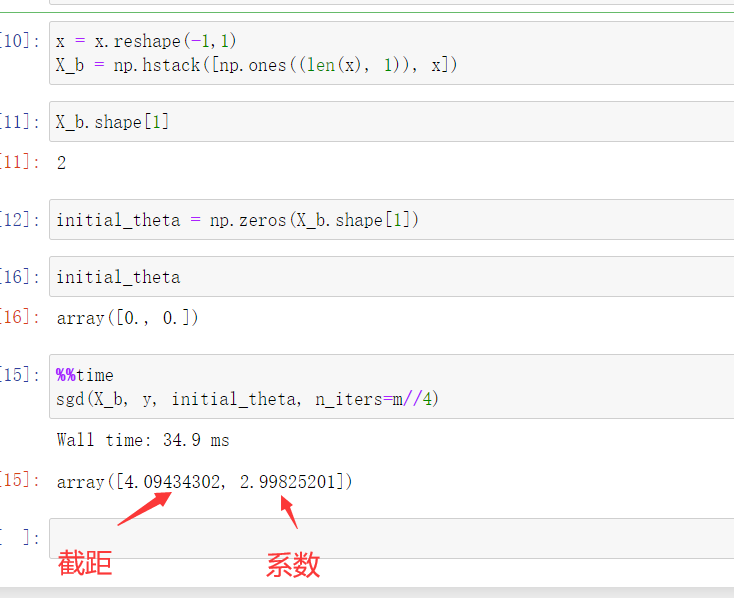
def dj_sgd(theta, x_i, y_i): # 传入一个样本,获取对应的梯度 return x_i.T.dot(x_i.dot(theta)-y_i)*2 # MSEdef sgd(X_b, y, initial_theta, n_iters): # 求出整个theta的函数 def learning_rate(i_iter): t0 = 5 t1 = 50 return t0/(i_iter+t1) theta = initial_theta i_iter = 1 while i_iter <= n_iters: index = np.random.randint(0, len(X_b)) x_i = X_b[index] y_i = y[index] gradient = dj_sgd(theta, x_i, y_i) # 求导数 theta = theta - gradient*learning_rate(i_iter) # 求步长 i_iter += 1 return theta调用函数,求出截距和系数
以上随机梯度的缺点是不能照顾到每一点,因此需要进行改进。
以下对其中的函数进行修改。
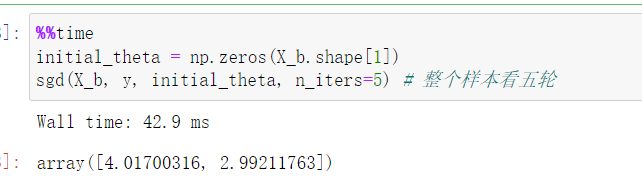
def dj_sgd(theta, x_i, y_i): # 传入一个样本,获取对应的梯度 return x_i.T.dot(x_i.dot(theta)-y_i)*2 # MSEdef sgd(X_b, y, initial_theta, n_iters): # 求出整个theta的函数 def learning_rate(i_iter): t0 = 5 t1 = 50 return t0/(i_iter+t1) theta = initial_theta m = len(X_b) for cur_iter in range(n_iters): # 每一次循环都把样本打乱,n_iters的代表整个样本看几轮 random_indexs = np.random.permutation(m) X_random = X_b[random_indexs] y_random = y[random_indexs] for i in range(m): theta = theta - learning_rate(cur_iter*m+i) * (dj_sgd(theta, X_random[i], y_random[i])) return theta与前边运算结果进行对比,其耗时更长。
读到这里,这篇“Python机器学习之随机梯度下降法如何实现”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341















