



目录
-
1. HTTP和HTTPS
- 1.1. HTTP的请求和响应流程:打开一个网页的过程
- 1.2. URL
- 2. 客户端HTTP请求
-
3. Fiddler抓包工具的使用
- 3.1. 工作原理
- 3.2. Fiddler抓取HTTPS设置
- 3.3. Fiddler抓取Chorme的对话
- 3.4. Fidder界面介绍
- 3.5. 实例:捕捉访问百度时候的请求和响应
-
4. 其他内容
- 4.1 Cookie和Session
HTTP: 一种发布和接受HTML页面方法,端口号为80
HTTPS: HTTP的安全版,在HTTP上加入了SSL层,端口号为443
SSL: 用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全

网络爬虫可以理解为模拟浏览器操作的过程
浏览器的主要功能是向服务器发送请求,在浏览器窗口展示您选择的网络资源,HTTP是一套计算机通过网络进行通信的规则
1.1. HTTP的请求和响应流程:打开一个网页的过程
主要流程

1.2. URL
基本格式: scheme://host[:port]/path/.../[?query-string][#anchor]
-
scheme:协议, http,https
-
host: 服务器的IP地址或者域名 -
port#: 服务器的端口(如果是协议默认端口,缺省端口为80)
-
path: 访问资源的路径 -
query-string: 参数,发送给http服务器的数据 -
anchor: 锚(跳转到网页的而制定锚点位置)
例如:
http://www.baidu.com
URL只是标识资源的位置,而HTTP是用来提交和获取资源. 客户端发送一个HTTP请求到服务器请求消息,包括如下格式
请求行、请求头部、空行、请求数据
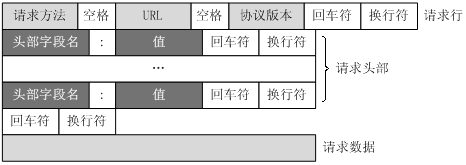
- 请求行
由请求方法字段、URL字段和HTTP协议版本字段组成,通过空格分隔,例如:GET /index.html HTTP/1.1
HTTP协议的请求方法主要有GET,POST方法
1) GET:从服务器获取数据
定义: 最常见的一种请求方式,当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页的,使用的都是GET方式
GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含的URL参数来阐述响应内容,即GET请求的参数是URL的一部分: http://www.baidu.com/s?wd=Chinese
"Get" 请求的参数 是URL的一部分
2) POST:向服务器传送数据
POST请求参数在请求体中,消息长度没有限制且以隐式的方式进行发送,通过用来向HTTP服务器提交数据(上传文件等),请求的参数放在Content-Type消息头中,指明该消息的媒体类型和编码
"POST"请求的参数 不在URL中,而在请求体中。
Fiddler是一款强大Web调试工具,它能记录所有客户端和服务器的HTTP请求。 Fiddler启动的时候,默认IE的代理设为了127.0.0.1:8888,而其他浏览器是需要手动设置。
3.1. 工作原理
Fiddler 是以代理web服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888

3.2. Fiddler抓取HTTPS设置
首先需要在官网上下载Fiddler安装程序:https://www.telerik.com/fiddler
启动Fiddler,打开菜单栏中的 Tools > Telerik Fiddler Options,打开“Fiddler Options”对话框。

- 对Fidder进行设置
- 打开工具栏->Tools->Fiddler Options->HTTPS,
- 选中Capture HTTPS CONNECTs (捕捉HTTPS连接),
- 选中Decrypt HTTPS traffic(解密HTTPS通信)
- 另外我们要用Fiddler获取本机所有进程的HTTPS请求,所以中间的下拉菜单中选中...from all processes (从所有进程)
- 选中下方Ignore server certificate errors(忽略服务器证书错误)


- Fiddler 主菜单 Tools -> Fiddler Options…-> Connections

- 重启Fidder
3.3. Fiddler抓取Chorme的对话
使用chorme的SwitchOmega插件 + 搭配使用SwitchOmega和Fiddler抓取数据

3.4. Fidder界面介绍
设置好后,本机HTTP通信都会经过127.0.0.1:8888代理,也就会被Fiddler拦截到。

请求 (Request) 部分详解
- Headers —— 显示客户端发送到服务器的 HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。
- Textview —— 显示 POST 请求的 body 部分为文本。
- WebForms —— 显示请求的 GET 参数 和 POST body 内容。
- HexView —— 用十六进制数据显示请求。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息.
- Raw —— 将整个请求显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果请求的 body 是 XML 格式,就是用分级的 XML 树来显示它。
响应 (Response) 部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的 header。
- TextView —— 使用文本显示相应的 body。
- ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
- Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密 (P3P) 信息。
- Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
3.5. 实例:捕捉访问百度时候的请求和响应
请求头(www.baidu.com)
# 1. 请求行:请求方法+URL+协议号
GET https://www.baidu.com/ HTTP/1.1
# 2. 请求头补:
Host: www.baidu.com
Connection: keep-alive # 常链接,不关闭长期保存
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1 # 升级一个不安全的请求: HTTP->HTTPS
# 浏览器客户端的一个版本信息
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
# 可以接收的文本的类型
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
# 客户端可以做的编码操作
Accept-Encoding: gzip, deflate, br
# 客户端支持的语言 + 权重
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,en-CA;q=0.6
# Cookie值:保存在本地浏览器的文本文件,记录当前在网络中的状态-》比如记录账户密码自动登录
Cookie: BAIDUID=4F583A04A0193EBE0C9849C551B9305C:FG=1; BIDUPSID=4F583A04A0193EBE0C9849C551B9305C; PSTM=1545978093; BD_UPN=12314753; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1440_21082_28205_28132_27751_27245_27509; H_PS_645EC=4f9b6%2FduIgSKPevnFeBA8pfSrBrfEA3Hy4jDyjs%2FTHh5IbfnjsLRKgH25MM; delPer=0; BD_CK_SAM=1; PSINO=7; BD_HOME=0
x-hd-token: rent-your-own-vps
响应的内容(www.baidu.com)

这跟我们右击游览器查看源代码出来的代码是一摸一样的
4.1 Cookie和Session
Cookie: 通过客户端记录的信息确定用户的身份
Session: 通过服务器记录的信息确定用户的身份












